







目录
2.5 决策树分类器DecisionTreeClassifier参数及方法
本文仅介绍一些数据挖掘需要了解的基础知识,实验代码仅供参考。
一,题目描述
分类任务
1.验证型实验
1.1目的
1)理解分类任务
2)考察学生对数据预处理步骤的理解,强化预处理的重要性
3)基模型可以调用已有的包,训练学生熟悉数据挖掘的基本框架
4)学会多维度的对模型进行评估以及模型中参数的讨论1.2数据集
1)UCI的soybean数据集, 数据中包含缺失值
2)UCI蛋白质数据集,特征处理
3)其他数据集数据说明:给一个train和一个test
1.3 方法要求
1)要有针对数据特点的预处理步骤
2)原则上不限制模型,决策树,NB,NN,SVM,random forest均可,且不限于上述方法1.4 结果要求
1)实现一个基本分类模型,并计算其评估指标如准确率,召回率等
2)对模型中的关键参数,(如决策树中停止分裂条件,NN中层数等参数)进行不同范围的取值,讨论参数的最佳取值范围。
3)对进行数据预处理和未进行预处理的分类结果进行对比,以验证预处理步骤的有效性
4)若对同一数据采用两种或多种模型进行了分类,对多种模型结果进行对比,以评估模型对该数据集上分类任务的适用性。1.5 提交材料清单
1)代码源文件
2)报告文档,文档中需说明数据,方法,运行结果,对比效果图等
3)填写了测试数据集的预测标签的文档文本或excel
二,实验准备
1,数据集下载
1.1 常用数据集链接
UCI:http://archive.ics.uci.edu/ml/datasets.php(常用)
Kaggle:https://www.kaggle.com/competitions
KDnuggets:https://www.kdnuggets.com/datasets/index.html
其他汇总:https://blog.csdn.net/weixin_44784939/article/details/96453965
链接: https://pan.baidu.com/s/18Wv1ypl9V99YaM7F8hLHIg 提取码: d4m4
1.2 UCI数据集
这里使用的是UCI网站中的Balanced-Scala数据集;
1)进入UCI官网后显示

2)根据任务类型选择数据集

3)选择数据集

4)点击数据集链接查看详情

5)数据集下载


6)数据集内容


1.3 Kaggle
Kaggle注册时可能由于没有连接外网,出现验证码无法显示的问题:Captcha must be filled out
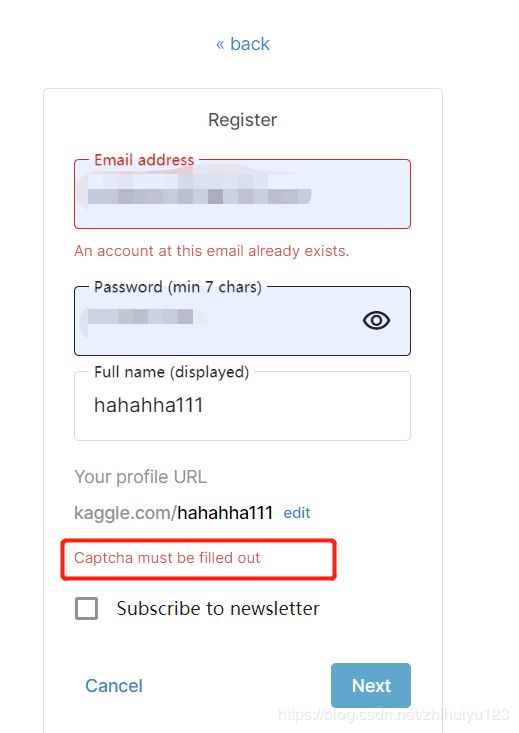
解决方法:@星星学园【记录:kaggle注册时验证码不出现的解决方法】
2,所需基础知识
参考@Python大本营【如何用Python处理分类和回归问题?(附代码)】
2.1 分类的方法
一些常用的分类算法如下:
- K-近邻算法(KNN)
- 决策树算法
- 贝叶斯分类算法
- 支持向量机(SVM)
在学习过程中,分类模型通过分析训练集来构建分类器;
在分类过程中,预测给定数据的分类标签。将待分析的数据集元组和与之相关联的类标签分成一个训练集和一个测试集。从待分析的数据集中随机抽样组成训练集的各个元组,剩下的元组形成测试集,并独立于训练集的元组,这就意味着测试集不会被用来构建分类器。
测试集用于评估分类器的预测正确率。
分类器的正确率是分类器正确分类的测试元组所占得百分比。为了达到更高的正确率,最好的办法就是测试不同的算法,并在每个算法中尝试不同的参数。其中,最好的一个方法是交叉验证。
为了选择一个较好的算法来解决这个问题,对于不同的算法,必须考虑其正确率,训练时间,线性度,参数个数以及其他特殊情况。
2.2 去重
可以使用pandas进行数据读取和处理,其中drop_duplicates函数用于删除Series、DataFrame中重复记录,并返回删除重复后的结果。详细可参考:
2.3 扩增数据集
就是在原数据集基础上增加记录的数目,或者是记录的属性个数。
比如同类型拼接。
以增加记录属性个数为例。假设数据集的标签有两种结果YES/NO,可以将标签为YES的两条记录组合起来,使得属性数目增加为原先的两倍,这样可以保证标签取值正确的情况下,每条记录的属性个数翻倍。
2.4 特征映射
也称降维,是将高维多媒体数据的特征向量映射到一维或者 低维空间的过程。在高维特征数据库中,高维数据 存在数据冗余。由于索引结构的性能随着维数的增 大而迅速降低,在维数大10以后,性能还不如顺 序扫描,形成维数灾难。降维后,应用成熟的低维索引技术,以提高性能。基于特征映射方法简单来说是指将数据从高维空间映射到低维空间,然后用分类器进行分类,为了得到较好的分类性能。
但在某些情况下,为了充分挖掘数据的蕴含意义,不一定非要降维,以下面的数据集为例:
第一列为标签,第二列为数据名称,第三列为基因序列值(57个a、c、g、t随机组和而成);
若将第三列看作57个属性进行分析计算,则会丢失属性间的关联关系;
所以为了充分保留单个基因序列之间的关联关系,特征映射采用的方法为:
- 四个基因为一组,每个基因从[a、c、g、t]中选取,这样共有256种组和方式(aaaa、aaac、aaag、aaat······);
- 每个属性可以看作若干组基因组和而成,比如 t t a g c g g 可以看作 ttag、tagc、agcg、gcgg组和而成;
- 这样原属性可以转换为一个数组(大小为256),存放每种组和在原属性中出现的次数,比如:
- aaaa aaac aaag aaat······tttt
- 2 6 0 8 ······ 1
这样就可以充分保留相邻基因序列间的关系,从而更好的挖掘数据的信息;

2.5 决策树分类器DecisionTreeClassifier参数及方法
参数:
- criterion:特征选择标准,【entropy, gini】。默认gini,即CART算法。entropy表示决策树使用的是ID3算法;
- splitter:特征划分标准,【best, random】。best在特征的所有划分点中找出最优的划分点,random随机的在部分划分点中找局部最优的划分点。默认的‘best’适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐‘random’。
- max_depth:决策树最大深度,【int, None】。默认值是‘None’。一般数据比较少或者特征少的时候可以不用管这个值,如果模型样本数量多,特征也多时,推荐限制这个最大深度,具体取值取决于数据的分布。常用的可以取值10-100之间,常用来解决过拟合。
方法:
- 训练(拟合):fit(X, y[, sample_weight])——fit(train_x, train_y)
- 预测:predict(X)返回标签、predict_log_proba(X)、predict_proba(X)返回概率,每个点的概率和为1,一般取predict_proba(X)[:, 1]
- 评分(返回平均准确度):score(X, y[, sample_weight])——score(test_x, test_y)。等效于准确率accuracy_score
举例
x_train, x_test, y_train, y_test = train_test_split(x_old, y, test_size=0.2) clf = DecisionTreeClassifier(criterion='entropy') clf.fit(x_train, y_train) y_predict = clf.predict(x_test) print(clf.score(x_test, y_test))
2.6 支持向量机SVC
svm.SVC分类器简介:
C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel :核函数,默认是rbf,可以是‘linear’,‘poly’, ‘rbf’
liner – 线性核函数:u'v
poly – 多项式核函数:(gamma*u'*v + coef0)^degree
rbf – RBF高斯核函数:exp(-gamma|u-v|^2)
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略
2.7 classification_report方法说明
参考@Flint【机器学习classification_report方法及precision精确率和recall召回率 说明】
运行实例
当一个搜索引擎返回30个页面时,只有20页是相关的,而没有返回40个额外的相关页面,其精度为20/30 = 2/3,而其召回率为20/60 = 1/3。在这种情况下,精确度是“搜索结果有多大用处”,而召回是“结果如何完整”;
F1 F1值是精确度和召回率的调和平均值:精确度和召回率都高时, F1 F1值也会高. F1 F1值在1时达到最佳值(完美的精确度和召回率),最差为0.在二元分类中, F1 F1值是测试准确度的量度;
宏平均 macro avg:对每个类别的 精准、召回和F1 加和求平均;
微平均 micro avg:不区分样本类别,计算整体的 精准、召回和F1;
加权平均 weighted avg:是对宏平均的一种改进,考虑了每个类别样本数量在总样本中占比;

3,配置环境
1)sklearn
分类算法的使用主要通过调用sklearn库中的方法,所以需要在开发环境中配置sklearn库,除此之外还应该配置有numpy、scipy方便进行数据处理。
安装sklearn可以通过以下命令进行:
pip install -U scikit-learn由于我习惯在anaconda创建的虚拟环境中进行项目环境配置,所以这里依然采用这种方法,效果如下

2)使用pandas运行提示numpy不匹配
若提示numpy版本不匹配,可以参考这里@百度经验【python安装的第三方库怎么删除】,需要不断将已安装的numpy删除掉,然后再更新

三,参考代码及结果
数据集下载地址:Index of /ml/machine-learning-databases/balance-scale Parent Directory
参考代码
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import svm
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
data = pd.read_csv('balance-scale.data', header=None)
x_old = [] # 存放原数据集中的属性
y_old = [] # 存放扩增数据集中的属性
x_new = [] # 存放扩增数据集中的属性
y_new = [] # 存放扩增数据集中的标签
x_train = [] # 存放训练集的属性
y_train = [] # 存放训练集的标签
x_test = [] # 存放测试集的属性
y_test = [] # 存放测试集的标签
testSize = 0.2 # 测试数据所占总数据比重
'''数据预处理'''
def Preprocessing():
data.drop_duplicates() # 删除重复值
data.dropna() # 删除缺失值
# x_old = [] # 临时存储原属性值 用于合成扩增数据集中的属性值
for index in data.index:
line = data.loc[index].values
x_old.append(line[1:5]) # 获取原数据集中的属性
y_old.append(line[0]) # 获取原数据集中的标签
'''扩增数据集'''
L = x_old[y_old.index('L')] # 确定第一个标签为L的属性值
R = x_old[y_old.index('R')] # 确定第一个标签为R的属性值
B = x_old[y_old.index('B')] # 确定第一个标签为B的属性值
for i, value in enumerate(y_old):
if value == 'L':
x_new.append(np.concatenate((x_old[i], L), axis=0)) # 将扩展后的新属性值 存放入扩增数据集属性x中
y_new.append('L')
L = x_old[i] # 更新最新的标签为L的属性值 用于下一次拼接
elif value == 'R':
x_new.append(np.concatenate((x_old[i], R), axis=0))
y_new.append('R')
R = x_old[i]
else:
x_new.append(np.concatenate((x_old[i], B), axis=0))
y_new.append('B')
x_new.append(np.concatenate((B, x_old[i]), axis=0)) # 这里将属性对换后再次插入新数据集 以增大标签B所占的数据集避重
y_new.append('B')
B = x_old[i]
'''决策树方法'''
def DecisionTree(testSize):
print('------------------------决策树方法------------------------')
print('原数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_old, y_old, test_size=testSize)
clf = DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print(clf.score(x_test, y_test))
print(classification_report(y_test, y_predict))
print('扩增数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_new, y_new, test_size=testSize)
clf = DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print(clf.score(x_test, y_test))
print(classification_report(y_test, y_predict))
'''随机森林方法'''
def RandomForest(testSize):
print('------------------------随机森林方法------------------------')
print('原数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_old, y_old, test_size=testSize)
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
y_predict = rfc.predict(x_test)
print(rfc.score(x_test, y_test))
print(classification_report(y_test, y_predict))
print('扩增数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_new, y_new, test_size=testSize)
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
y_predict = rfc.predict(x_test)
print(rfc.score(x_test, y_test))
print(classification_report(y_test, y_predict))
'''KNN方法'''
def knn(testSize):
print('------------------------KNN方法------------------------')
print('原数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_old, y_old, test_size=testSize)
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
print(knn.score(x_test, y_test))
print(classification_report(y_test, y_predict))
print('扩增数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_new, y_new, test_size=testSize)
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
print(knn.score(x_test, y_test))
print(classification_report(y_test, y_predict))
'''SVC方法'''
def svc(testSize):
print('------------------------SVC方法------------------------')
print('原数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_old, y_old, test_size=testSize)
clf = svm.SVC()
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print(clf.score(x_test, y_test))
print(classification_report(y_test, y_predict))
print('扩增数据集:')
x_train, x_test, y_train, y_test = train_test_split(x_new, y_new, test_size=testSize)
clf = svm.SVC()
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print(clf.score(x_test, y_test))
print(classification_report(y_test, y_predict))
Preprocessing() # 数据预处理
DecisionTree(testSize)
RandomForest(testSize)
knn(testSize)
svc(testSize)
运行效果



















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









