






深度学习与自然语言处理——第一次作业
一、实验题目
首先阅读https://docs.qq.com/pdf/DUUR2Z1FrYUVqU0ts文章,参考文章来计算所提供数据库中文的平均信息熵。
二、实验过程
1.中文语料预处理
由于一元模型不需要考虑上下文关系,所以其读取语料的方式与二元模型和三元模型不一样,直接将文件夹中的txt文件合并写入一个文件中,再通过jieba进行分词,得到所需要的txt格式语料库。
二元模型和三元模型需要考虑上下文关系,不能直接去掉所有标点符号得到无分隔的语料。通过中文停词表清理语料,生成由停词分行的txt格式语料库。
读取文件:
def read_data(path):
data_txt = []
files = os.listdir(path)
for file in files:
position = path + '\\' + file # 构造绝对路径,"\\",其中一个'\'为转义符
with open(position, 'r', encoding='ANSI') as f:
data = f.read()
ad = '本书来自www.cr173.com免费txt小说下载站\n更多更新免费电子书请关注www.cr173.com'
data = data.replace(ad, '')
data_txt.append(data)
f.close()
return data_txt, files
一元模型语料库预处理:
def preprocess():
path = "E:\文档\第二学期学校文件\coursework\coursework1\jyxstxtqj_downcc.com"
data_txt,filenames = read_data(path)
for file in filenames: # 遍历文件夹
position = path + '\\' + file # 构造绝对路径,"\\",其中一个'\'为转义符
with open(position, "r", encoding='ANSI') as f:
for line in f.readlines():
with open("E:\文档\第二学期学校文件\coursework\coursework1\jyxs.txt", "a",encoding='ANSI') as p:
p.write(line)
二元、三元模型语料库预处理:
def preprocess_sentence():
line = ''
data_txt,filenames = read_data("E:\文档\第二学期学校文件\coursework\coursework1\jyxstxtqj_downcc.com")
punctuations = stop_punctuation("E:\文档\第二学期学校文件\coursework\coursework1\stop_punctuation.txt")
with open('./jyxs_sentence.txt', "w", encoding='ANSI') as f:
for i in range(len(data_txt)):
text = data_txt[i]
for x in text:
if x in ['\n', '。', '?', '!', ',', ';', ':'] and line != '\n': # 以部分中文符号为分割换行
if line.strip() != '':
f.write(line + '\n') # 按行存入语料文件
line = ''
elif x not in punctuations:
line += x
f.close()
2.词频统计
一元模型只需要统计每个词在语料库中出现的频数,得到词频表。二元模型也需要统计每次词在语料库中出现的频数,得到词频表,作为计算条件概率P(wi|wi-1)时的分母,并且需要统计每个二元词组在语料库中出现的频数,得到二元模型词频表。三元模型需要统计每个二元词组在语料库中出现的频数,得到二元模型词频表,作为计算条件概率P(wi|wi-2,wi-1)时的分母,并且需要统计每个三元词组在语料库中出现的频数,得到三元模型词频表。
一元模型词频统计:
def get_tf(words):
tf_dic = {}
for w in words:
tf_dic[w] = tf_dic.get(w, 0) + 1
return tf_dic.items()
二元模型词频统计:
def get_bigram_tf(tf_dic, words):
for i in range(len(words)-1):
tf_dic[(words[i], words[i+1])] = tf_dic.get((words[i], words[i+1]), 0) + 1
# 非句子末尾二元词频统计
def get_bi_tf(tf_dic, words):
for i in range(len(words)-2):
tf_dic[(words[i], words[i+1])] = tf_dic.get((words[i], words[i+1]), 0) + 1
二元模型词频统计:
def get_trigram_tf(tf_dic, words):
for i in range(len(words)-2):
tf_dic[((words[i], words[i+1]), words[i+2])] = tf_dic.get(((words[i], words[i+1]), words[i+2]), 0) + 1
3.计算信息熵
一元模型的信息熵计算公式为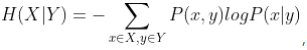
其中P(x)可近似等于每个词在语料库中出现的频率。
二元模型的信息熵计算公式为
,其中联合概率P(x,y)可近似等于每个二元词组在语料库中出现的频率,条件概率P(x|y)可近似等于每个二元词组在语料库中出现的频数与以该二元词组的第一个词为词首的二元词组的频数的比值。
三元模型的信息熵计算公式为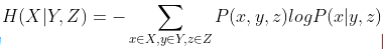 其中联合概率P(x,y,z)可近似等于每个三元词组在语料库中出现的频率,条件概率P(x|y,z)可近似等于每个三元词组在语料库中出现的频数与以该三元词组的前两个词为词首的三元词组的频数的比值。
其中联合概率P(x,y,z)可近似等于每个三元词组在语料库中出现的频率,条件概率P(x|y,z)可近似等于每个三元词组在语料库中出现的频数与以该三元词组的前两个词为词首的三元词组的频数的比值。
实验结果
- 一元模型:
语料库字数: 7284925
分词个数: 4293365
平均词长: 1.697
基于词的一元模型的中文信息熵为: 12.281 比特/词
运行时间: 92.809 s
- 二元模型
语料库字数: 7284925
分词个数: 4309148
平均词长: 1.691
语料行数: 1007126
二元模型长度: 3302022
基于词的二元模型的中文信息熵为: 6.725 比特/词
运行时间: 50.052 s
- 三元模型
语料库字数: 7284925
分词个数: 4309148
平均词长: 1.691
语料行数: 1007126
三元模型长度: 2378147
基于词的三元模型的中文信息熵为: 2.41 比特/词
运行时间: 44.78 s
实验代码
import os
import jieba
import math
import time
import re
import logging
# 读取文件夹文件
def read_data(path):
data_txt = []
files = os.listdir(path)
for file in files:
position = path + '\\' + file # 构造绝对路径,"\\",其中一个'\'为转义符
with open(position, 'r', encoding='ANSI') as f:
data = f.read()
ad = '本书来自www.cr173.com免费txt小说下载站\n更多更新免费电子书请关注www.cr173.com'
data = data.replace(ad, '')
data_txt.append(data)
f.close()
return data_txt, files
# 一元模型语料库预处理
def preprocess():
path = "E:\文档\第二学期学校文件\coursework\coursework1\jyxstxtqj_downcc.com"
data_txt,filenames = read_data(path)
for file in filenames: # 遍历文件夹
position = path + '\\' + file # 构造绝对路径,"\\",其中一个'\'为转义符
with open(position, "r", encoding='ANSI') as f:
for line in f.readlines():
with open("E:\文档\第二学期学校文件\coursework\coursework1\jyxs.txt", "a",encoding='ANSI') as p:
p.write(line)
# 一元模型词频统计
def get_tf(words):
tf_dic = {}
for w in words:
tf_dic[w] = tf_dic.get(w, 0) + 1
return tf_dic.items()
if __name__ == '__main__':
before = time.time()
preprocess()
with open("E:\文档\第二学期学校文件\coursework\coursework1\jyxs.txt", 'r', encoding='ANSI') as f:
corpus = f.read() # 读取文件得到语料库文本
split_words = [x for x in jieba.cut(corpus)] # 利用jieba分词
words_len = len(split_words)
print("语料库字数:", len(corpus))
print("分词个数:", words_len)
print("平均词长:", round(len(corpus)/words_len, 3))
words_tf = get_tf(split_words) # 得到词频表
# print("词频表:", words_tf)
entropy = [-(uni_word[1]/words_len)*math.log(uni_word[1]/words_len, 2) for uni_word in words_tf]
print("基于词的一元模型的中文信息熵为:", round(sum(entropy), 3), "比特/词")
after = time.time()
print("运行时间:", round(after-before, 3), "s")
def stop_punctuation(path): # 中文字符表
with open(path, 'r', encoding='utf-8') as f:
items = f.read()
return [l.strip() for l in items]
def preprocess_sentence():
line = ''
data_txt,filenames = read_data("E:\文档\第二学期学校文件\coursework\coursework1\jyxstxtqj_downcc.com")
punctuations = stop_punctuation("E:\文档\第二学期学校文件\coursework\coursework1\stop_punctuation.txt")
with open('./jyxs_sentence.txt', "w", encoding='ANSI') as f:
for i in range(len(data_txt)):
text = data_txt[i]
for x in text:
if x in ['\n', '。', '?', '!', ',', ';', ':'] and line != '\n': # 以部分中文符号为分割换行
if line.strip() != '':
f.write(line + '\n') # 按行存入语料文件
line = ''
elif x not in punctuations:
line += x
f.close()
# 二元模型词频统计
def get_bigram_tf(tf_dic, words):
for i in range(len(words)-1):
tf_dic[(words[i], words[i+1])] = tf_dic.get((words[i], words[i+1]), 0) + 1
if __name__ == '__main__':
before = time.time()
preprocess_sentence()
with open('./jyxs_sentence.txt', 'r', encoding='ANSI') as f:
corpus = []
count = 0
for line in f:
if line != '\n':
corpus.append(line.strip())
count += len(line.strip())
split_words = []
words_len = 0
line_count = 0
words_tf = {}
bigram_tf = {}
for line in corpus:
for x in jieba.cut(line):
split_words.append(x)
words_len += 1
get_tf(words_tf, split_words)
get_bigram_tf(bigram_tf, split_words)
split_words = []
line_count += 1
print("语料库字数:", count)
print("分词个数:", words_len)
print("平均词长:", round(count / words_len, 3))
print("语料行数:", line_count)
# print("非句子末尾词频表:", words_tf)
# print("二元模型词频表:", bigram_tf)
bigram_len = sum([dic[1] for dic in bigram_tf.items()])
print("二元模型长度:", bigram_len)
entropy = []
for bi_word in bigram_tf.items():
jp_xy = bi_word[1] / bigram_len # 计算联合概率p(x,y)
cp_xy = bi_word[1] / words_tf[bi_word[0][0]] # 计算条件概率p(x|y)
entropy.append(-jp_xy * math.log(cp_xy, 2)) # 计算二元模型的信息熵
print("基于词的二元模型的中文信息熵为:", round(sum(entropy), 3), "比特/词") # 6.402
after = time.time()
print("运行时间:", round(after-before, 3), "s")
# 非句子末尾二元词频统计
def get_bi_tf(tf_dic, words):
for i in range(len(words)-2):
tf_dic[(words[i], words[i+1])] = tf_dic.get((words[i], words[i+1]), 0) + 1
# 三元模型词频统计
def get_trigram_tf(tf_dic, words):
for i in range(len(words)-2):
tf_dic[((words[i], words[i+1]), words[i+2])] = tf_dic.get(((words[i], words[i+1]), words[i+2]), 0) + 1
if __name__ == '__main__':
before = time.time()
# preprocess_sentence()
with open('./jyxs_sentence.txt', 'r', encoding = 'ANSI') as f:
corpus = []
count = 0
for line in f:
if line != '\n':
corpus.append(line.strip())
count += len(line.strip())
split_words = []
words_len = 0
line_count = 0
words_tf = {}
trigram_tf = {}
for line in corpus:
for x in jieba.cut(line):
split_words.append(x)
words_len += 1
get_bi_tf(words_tf, split_words)
get_trigram_tf(trigram_tf, split_words)
split_words = []
line_count += 1
print("语料库字数:", count)
print("分词个数:", words_len)
print("平均词长:", round(count / words_len, 3))
print("语料行数:", line_count)
# print("非句子末尾二元词频表:", words_tf)
# print("三元模型词频表:", trigram_tf)
trigram_len = sum([dic[1] for dic in trigram_tf.items()])
print("三元模型长度:", trigram_len)
entropy = []
for tri_word in trigram_tf.items():
jp_xy = tri_word[1] / trigram_len # 计算联合概率p(x,y)
cp_xy = tri_word[1] / words_tf[tri_word[0][0]] # 计算条件概率p(x|y)
entropy.append(-jp_xy * math.log(cp_xy, 2)) # 计算三元模型的信息熵
print("基于词的三元模型的中文信息熵为:", round(sum(entropy), 3), "比特/词") # 0.936
after = time.time()
print("运行时间:", round(after-before, 3), "s")














 2488
2488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









