







第三章 索引
学习时间:
12月20日——12月22日(3天)
学习内容:
第三章内容太多了,为方便以后查看,把目录链接放在此处。
学习目录:
一、索引器
1. 表的列索引
列索引一般通过 [ ] 来实现。
通过 [列名] 可以从 DataFrame 中取出相应的列,返回值为 Series
此外,若要取出单列,且列名中不包含空格,则可以用 .列名 取出,这和 [列名] 是等价的:


如果要取出多个列,则可以通过 [[列名名1,列表名2,…]] ,其返回值为一个 DataFrame

2. 序列的行索引
【a】以字符串为索引的 Series
如果取出单个索引的对应元素,则可以使用 [item]
若 Series 只有单个值对应,则返回这个标量值
如果有多个值对应,则返回一个 Series


如果取出多个索引的对应元素,则可以使用 [items的列表]

【b】以整数为索引的 Series
和字符串一样,如果使用 [int] 或 [int_list] ,则可以取出对应索引 元素 的值
注意:
如果不特别指定所对应的列作为索引,那么会生成从0开始的整数索引作为默认索引

注意:
请不要把纯浮点以及任何混合类型(字符串、整数、浮点类型等的混合)作为索引
3. loc索引器
对于表而言,有两种索引器
- 一种是基于 元素 的 loc 索引器
- 另一种是基于 位置 的 iloc 索引器。
loc 索引器的一般形式是 *loc[*, ] ,其中第一个 * 代表行的选择,第二个 * 代表列的选择。 其中, * 的位置分别是:
- 单个元素
- 元素列表
- 元素切片
- 布尔列表
- 函数
【a】 * 为单个元素
直接取出相应的行或列
第一个为多人叫Qiang Sun
第二个为只有一个人叫Quan Zhao

【b】 * 为元素列表
取出列表中所有元素值对应的行或列

【c】 * 为切片
之前的 Series 使用字符串索引时提到,如果是唯一值的起点和终点字符,那么就可以使用切片,并且包含两个端点,如果不唯一则报错

【d】 * 为布尔列表
类似于数据库,判断是否符合条件,为 True 的位置所对应的行会被选中, False 则会被剔除
删选体重小于70kg的

对于复合条件而言,可以用 |(或), &(且), ~(取反) 的组合来实现
例如选出复旦大学中体重超过70kg的大四学生,或者北大男生中体重超过80kg的非大四的学生:


【e】 * 为函数
直接举例说明吧
注意的是函数的形式参数 x 本质上即为 df_demo

还支持使用 lambda 表达式,其返回值也同样必须是先前提到的四种形式之一

4. iloc索引器
iloc 的使用与 loc 完全类似,只不过是针对位置进行筛选,在相应的 * 位置处一共也有五类合法对象,分别是:
1、整数、
2、 整数列表、
3、 整数切片、
4、 布尔列表
5、函数
函数的返回值必须是前面的四类合法对象中的一个,其输入同样也为 DataFrame 本身。
5. query方法
在 pandas 中,支持把字符串形式的查询表达式传入 query 方法来查询数据,其表达式的执行结果必须返回布尔列表。

在 query 表达式中,帮用户注册了所有来自 DataFrame 的列名,所有属于该 Series 的方法都可以被调用,和正常的函数调用并没有区别
例如查询体重超过均值的学生

- 同时,在 query 中还注册了若干英语的字面用法,帮助提高可读性,例如: or, and, or, is in, not in 。
- 在字符串中出现与列表的比较时, == 和 != 分别表示元素出现在列表和没有出现在列表,等价于 is in 和 not in
- 对于 query 中的字符串,如果要引用外部变量,只需在变量名前加 @ 符号。
6. 随机抽样
如果把 DataFrame 的
每一行看作一个样本
把每一列看作一个特征
再把整个 DataFrame 看作总体
想要对样本或特征进行随机抽样就可以用 sample 函数。
sample 函数中的主要参数为
1、n, 抽样数量
2、axis,抽样的方向(0为行、1为列)
3、 frac, 抽样比例(0.3则为从总体中抽出30%的样本)
4、replace, 是否放回
5、weights ,每个样本的抽样相对概率


二、多级索引
1. 多级索引及其表的结构
与单层索引的表一样,具备元素值、行索引和列索引三个部分。
行索引和列索引都是 MultiIndex 类型,只不过 索引中的一个元素是元组
这里建立一张新表,按照颜色区分
行索引的第四个元素为 (“B”, “Male”)
列索引的第二个元素为 (“Height”, “Senior”)
但我还没有太理解作者标记颜色之后的意思。

与单层索引类似, MultiIndex 也具有名字属性
- 图中的 School 和 Gender 分别对应了表的第一层和第二层行索引的名字
- Indicator 和 Grade 分别对应了第一层和第二层列索引的名字。
索引的名字通过 names 获得
索引的值属性通过 values 获得
表格内容如下:


得到某一层的索引,则需要通过 get_level_values 函数

2. 多级索引中的loc索引器
回到原表,将学校和年级设为索引

在索引前最好对 MultiIndex 进行排序以避免性能警告:


在多级索引中的元组有一种特殊的用法,可以对多层的元素进行交叉组合后索引,但同时需要指定 loc 的列,全选则用 : 表示。
[(level_0_list, level_1_list), cols]


3. IndexSlice对象
IndexSlice对象可以对每层进行切片,也允许将切片和布尔列表混合使用
Slice 对象一共有两种形式
第一种为 loc[idx[,]] 型
第二种为 loc[idx[,],idx[,]] 型
下面构造一个 索引不重复的 DataFrame
(构造过程省略,表如下图)

【a】 loc[idx[,]] 型
前一个 * 表示行的选择,后一个 * 表示列的选择


注意:
这种情况并不能进行多层分别切片
【b】 loc[idx[,],idx[,]] 型
前一个 idx 指代的是行索引,后一个是列索引。

4. 多级索引的构造
自己构造多级索引
常用的有
from_tuples,
from_arrays,
from_product
from_tuples 指根据传入由元组组成的列表进行构造

from_arrays 指根据传入列表中,对应层的列表进行构造

from_product 指根据给定多个列表的笛卡尔积进行构造

三、索引的常用方法
1. 索引层的交换和删除
为了方便理解交换的过程,这里构造一个三级索引的例子
构造过程省略,表如下图:

索引层的交换由 swaplevel 和 reorder_levels 完成
- swaplevel只能交换两个层
- reorder_levels可以交换任意层


若想要删除某一层的索引,可以使用 droplevel 方法
2. 索引属性的修改
通过 rename_axis 可以对索引层的名字进行修改
通过 rename 可以对索引的值进行修改,如果是多级索引需要指定修改的层号 level

3. 索引的设置与重置
构造一个新表
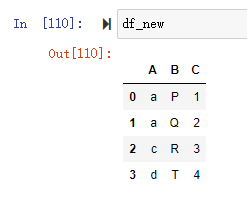
索引的设置可以使用 set_index 完成,这里的主要参数是 append ,表示是否来保留原来的索引,直接把新设定的添加到原索引的内层
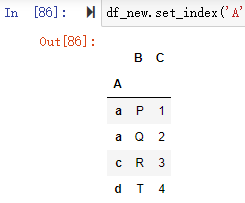
同时指定多个列作为索引















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









