







-
选择CentOS-7-x86_64-Minimal-1708.iso版本
-
一个镜像安装三个CentOS虚拟机、三个账号都为root、密码***
-
一个主机名为Master、一个为Slave1、一个为Slave2
-
之后可以根据文件 /etc/hostname 更改
-
完成登录之后如图:
-

-


-
登录成功后,设置静态IP
|Master|IP |192.168.23.200
|Slave1|IP |192.168.23.201
|Slave2|IP |192.168.23.202
1)使用root用户登录虚拟机,使用“ip addr”查看虚拟机网络,可以发现虚拟机还没有配置网络

2)开始配置虚拟机网络,点击VMbox顶部菜单栏“设备”——>“网络”——>“网络”,进入网络配置项。配置网络连接方式为“桥接网卡

3)使用命令“vim /etc/sysconfig/network-scripts/ifcfg-enp0s3”修改IP,不同虚拟机网络配置文件可以稍有不同,不一定都是ifcfg-enp0s3,具体看实际情况。具体配置如下图,其中红色方框部分为修改与添加部分。

4)完成配置后,使用“service network restart”命令重启网络,使用“ip addr”命令查看IP,使用“ping www.baidu.com”测试网络是否可用。如下图,完成网络配置。

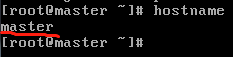
5)使用“hostname”命令查看虚拟机当前主机名,使用“vi /etc/hostname”编辑修改虚拟机主机名。修改后使用命令“reboot”重启生效
6) 赋予普通用户hadoop、为其增加sudo权限
在root用户下完成添加普通用户sudo权限的操作,为所有机器普通用户配置sudo
1、添加sudo文件写权限:chmod u+w /etc/sudoers
2、编辑sudoers文件:vi /etc/sudoers
找到行“root ALL=(ALL) ALL”,在下面添加“hadoop ALL=(ALL) ALL”,其中xxx为需要添加sudo权限的普通用户。
3、撤销sudoers文件写权限:chmod u-w /etc/sudoers
以上完成为普通用户添加sudo权限操作
4、在vi下,使用 ?.root 快速查找位置
5、为hadoop用户创建一个专门的目录供其使用
mkdir /user
将hadoop组件需要的都在/user目录下,将组变掉。
chown -R hadoop:hadoop /user

- 为之后容易操作,建议继续安装Xshell6来完成操作
- 百度网盘Xshell6 密码j7si
- 这里要注意的是,你的电脑本地IP需要和虚拟机ping通,由于我这里是192.168.23.*开头的,所以我设置的静态IP也是以这个开头。自己可以在本机 ipconfig 查看 IP
- 新建三个会话,名字分别为master,slave1.slave2

- 最终结果如图

7)配置SSH免密登录
注意:以下操作每台虚拟机都需完成
0)配置hosts文件
vi /etc/hosts

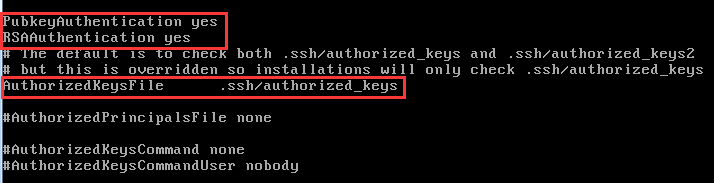
1)使用root用户修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。检查下面几行前面”#”注释是否取消掉,若以下项没有则自行增加:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
3)取消注释后,继续使用root重启sshd服务
[root@master]# service sshd restart
4)退出使用普通用户,在~目录下完成以下免密操作:
(1)执行完命令,生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
ssh-keygen -t rsa (一直回车)
[hadoop@master ~]$ cd .ssh
(2)将公钥拷贝到要免密登陆的目标机器master上
使用以下命令将自身公钥放到authorized_keys文件中,以master为例
[hadoop@master ~ .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~ .ssh]$ chmod 600 authorized_keys
其他几台将自身公钥拷贝到master机器上
[hadoop@slave1 ~ .ssh]$ ssh-copy-id hadoop@master
[hadoop@salve2 ~ .ssh]$ ssh-copy-id hadoop@master
master的authorized文件得到全部机器公钥后,修改authorized_keys文件权限为600,分发给其他机器,以其中一台为例
[hadoop@master ~ .ssh]$ scp authorized_keys
3)在机器上测试是否能够互相登录,以下为例
[hadoop@master ~]$ ssh slave1
[hadoop@master ~]$ ssh slave2
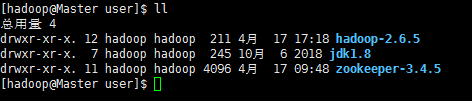
安装jdk1.8
-
压缩在/user目录下
-
配置环境变量vi /etc/profile
- export JAVA_HOME=/user/jdk1.8
- export PATH=$ JAVA_HOME/bin:$PATH
- source /etc/profile
- java -version

-
SCP到Slave1和Slave2
安装Zookeeper3.4.5
1)上传zookeeper3.4.5安装包到/user目录
2)解压安装包
[hadoop@master ~]$ tar -zxvf zookeeper-3.4.5.tar.gz
3)进入zookeeper解压后的conf目录,复制一份zookeeper配置文件zoo_sample.cfg并命名为zoo.cfg
[hadoop@conf ~]$ cp zoo_sample.cfg zoo.cfg
4)zookeeper安装目录下创建data与logs目录,分别用于存放zookeeper产生的数据与日志,之后修改zookeeper配置文件zoo.cfg,修改内容如下:

[hadoop@zookeeper-3.4.5 ~]$ mkdir data
[hadoop@zookeeper-3.4.5 ~]$ mkdir logs
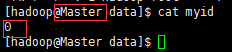
5)在第一个zookeeper节点master机器的zookeeper/data目录下创建myid文件,并写入值0
[hadoop@zookeeper-3.4.5 ~]$ echo 0 > data/myid
[hadoop@zookeeper-3.4.5 ~]$ cat data/myid
6)配置环境变量
[hadoop@master ~]$ sudo vi /etc/profile
在文件相应位置加入以下内容:
export ZOOKEEPER_HOME=/user/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
7)刷新配置
[hadoop@master ~]$ sudo source /etc/profile
8)传输zookeeper目录与配置文件给其他节点机器,以Slave1为例
[hadoop@master ~]$ scp zookeeper-3.4.5 Slave1:/user
之后为每个myid文件写入自己定义的server

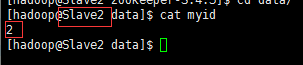
9)将配置分发到其他节点上
scp -r /user/zookeeper-3.4.5/ Slave1:/user/
scp -r /user/zookeeper-3.4.5/ Slave2:/user/
- 启动所有ZK的节点
bin/zkServer.sh start
11)查看状态
bin/zkServer.sh status
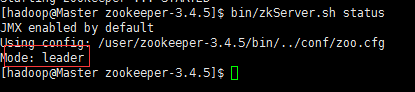
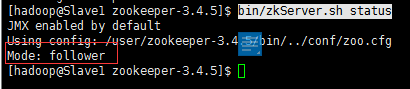
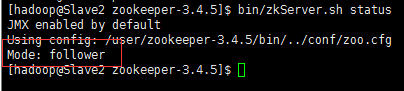
当看到 2个: follower 和 1个: leader 说明配置成功
现在开始安装Hadoop
- Hadoop下载链接
- 在本机电脑下载好后,通过Xftp上传

-1)配置环境变量
在hadoop-env.sh和mapred-env.sh还有yarn-env.sh中写上你的jdk路径(有可能这条属性被注释掉了,记得解开,把前面的#去掉就可以了)
export JAVA_HOME=/opt/modules/jdk1.8.0_171
2)配置 /user/hadoop-2.6.0/etc/hadoop 下的5个文件
core-site.xml
hdfs-site.xml
mapred-site.xml(重命名:mapred-site.xml.template)
yarn-site.xml
core-site.xml
---------------------------------------------------------------------------
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- ns -->
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/user/hadoop-2.6.5/data/tmp</value>
</property>
<!-- Resource Manager UI的默认用户dr.who权限不正确 ,这里写上你的机器用户名-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>Master</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Master:2181,Slave1:2181,Slave2:2181</value>
</property>
</configuration>
---------------------------------------------------------------------------
hdfs-site.xml
---------------------------------------------------------------------------
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>Master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>Master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>Slave1:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value> Slave1:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Master:8485;Slave1:8485;Slave2:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/user/hadoop-2.6.5/data/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,由于centOS的sshfence命令没有安装,所以使用本机自带的shell(假如这个不成功,则试下使用sshfence) -->
<property>
<name>dfs.ha.fencing.methods</name>
<value> shell(/bin/true)</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///user/hadoop-2.6.5/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<!--这里注意了,file///,不然会疯的!-->
<value>file:///user/hadoop-2.6.5/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
---------------------------------------------------------------------------
mapred-site.xml
---------------------------------------------------------------------------
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MapReduce JobHistory Server地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
---------------------------------------------------------------------------
yarn-site.xml
---------------------------------------------------------------------------
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Slave2</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
</configuration>
Slaves
---------------------------------------------------------------------------
Master
Slave1
Slave2
3)分发文件
注:只要配置一台,配置完了,把配置分发给其他机器,使用如下命令(scp命令):
scp -r /user/hadoop-2.6.5/ hadoop@192.168.23.201:/user
scp -r /user/hadoop-2.6.5/ hadoop@192.168.23.202:/user
启动 Hadoop 集群
【启动过程】
1、首先zookeeper已经启动好了吧(三台都要启动)
开启命令 bin/zkServer.sh start
2、启动三台journalnode(这个是用来同步两台namenode的数据的)
$ sbin/hadoop-deamon.sh start journalnode
3、操作namenode(只要格式化一台,另一台同步,两台都格式化,你就做错了!!)
1)、格式化第一台:
$ bin/hdfs namenode -format
2)、启动刚格式化好的namenode:
$ sbin/hadoop-deamon.sh start namenode
3)、在第二台机器上同步namenode的数据:
$ bin/hdfs namenode -bootstrapStandby
4)、启动第二台的namenode:
$ sbin/hadoop-deamon.sh start namenode
4、查看web
注意:如果用主机名登陆,必须在 C:\Windows\System32\drivers\etc 下的 hosts配置映射
http://Master:50070
http://Slave1:50070


5、这时可以查看在zookeeper上生成一个节点 hadoop-ha,这个是自动生成的,通过下面的命令生成:
$ bin/hdfs zkfc -formatZK
6、你登录zookeeper的客户端,就是bin/zkCli.sh里面通过 “ls /” 可以看到多了个节点

等到完全启动了之后,就可以kill掉active的namenode,你就会发现stanby的机器变成active,然后再去启动那台被你kill掉的namenode(启动起来是stanby的状态),然后你再去kill掉active,stanby的机器又会变成active,到此你的HA自动故障转移已经完成了。
这是官网的帮助文档:http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
后话:其实也可以做resourcemanager的HA,但是其实你能搭出namenode的HA,对于你来说,resourcemanager的HA就很简单了。
7、配置文件
只修改yarn-site.xml文件
yarn-site.xml
-------------------------------------------------------------
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<!--是否开启RM ha,默认是开启的-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>Slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>Slave2</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>Master:2181,Slave1:2181,Slave2:2181</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
发送yarn-site.xml 到其他机器
scp etc/hadoop/yarn-site.xml hadoop@192.168.23.201:/user/hadoop-2.6.5/etc/hadoop/
scp etc/hadoop/yarn-site.xml hadoop@192.168.23.202:/user/hadoop-2.6.5/etc/hadoop/
三、启动 ResourceManager
在Slave1上:
sbin/start-yarn.sh
在Slave2上:
sbin/yarn-daemon.sh start resourcemanager
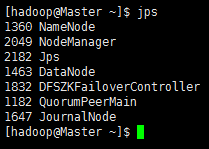
Master
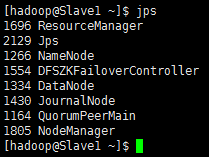
Slave1
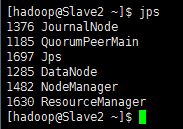
Slave2
观察web 8088端口
当Slave1的ResourceManager是Active状态的时候,访问Slave2的ResourceManager会自动跳转到PC02的web页面
测试HA的可用性
查看的状态:
bin/yarn rmadmin -getServiceState rm1 ##查看rm1的状态
bin/yarn rmadmin -getServiceState rm2 ##查看rm2的状态
然后你可以提交一个job到yarn上面,当job执行一半(比如map执行了100%),然后kill -9 掉active的rm
这时候如果job还能够正常执行完,结果也是正确的,证明你rm自动切换成功了,并且不影响你的job运行!!!
Hadoop HA搭建完成
参考博客:
https://blog.csdn.net/qq_33187206/article/details/80776839
http://www.cnblogs.com/ljy2013/p/4512550.html?utm_source=tuicool&utm_medium=referral















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









