







布隆过滤器
定义
布隆过滤器是⼀种概率型数据结构,它的特点是⾼效的插⼊和查询,能明确告知某个字符串⼀定不存在或者可能存在;
布隆过滤器相⽐传统的查询结构(例如: hash, set, map等数据结构) 更加⾼效,占⽤空间更⼩;但是其缺点是它返回的结果是概率性的,也就是说结果存在误差的,虽然这个误差是可控的;同时它不⽀持删除操作;
组成
位图(bit数组) + n个hash函数
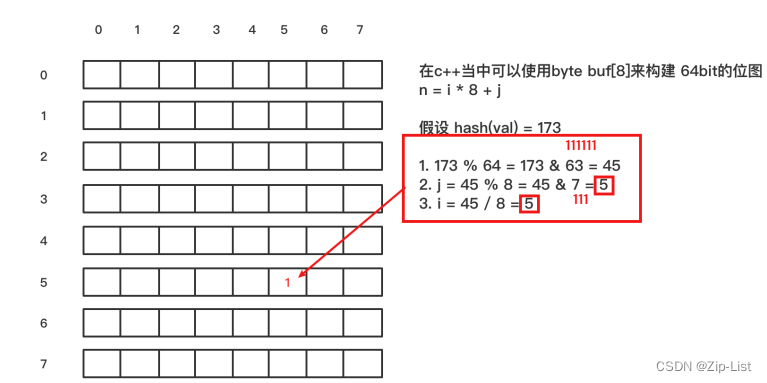
原理
当⼀个元素加⼊位图时,通过k个hash函数将这个元素映射到位图的k个点,并把它们置为
1;当检索时,再通过k个hash函数运算检测位图的k个点是否都为1;如果有不为1的点,那么认为
不存在;如果全部为1,则可能存在(存在误差);
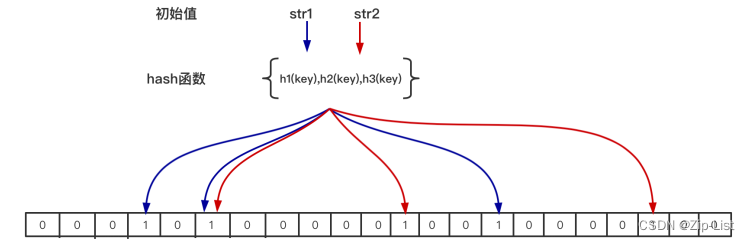
-
在位图中每个槽位只有两种状态(0或者1),⼀个槽位被设置为1状态,但不明确它被设置了多少次;也就是不知道被多少个str1哈希映射以及是被哪个hash函数映射过来的;所以不⽀持删除操作;
-
在实际应⽤过程中,布隆过滤器该如何使⽤?要选择多少个hash函数,要分配多少空间的位图,存储多少元素?另外如何控制假阳率(布隆过滤器能明确⼀定不存在,不能明确⼀定存在,那么存在的判断是有误差的,假阳率就是错误判断存在的概率)?
-
在实际应⽤中,我们确定n和p,通过上⾯的计算算出m和k;也可以在⽹站上选取合适的值:
https://hur.st/bloomfilter -
已知k,如何选择k个hash函数?
// 采⽤⼀个hash函数,给hash传不同的种⼦偏移值
// #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
uint64_t hash1 = MurmurHash2_x64(key, len, Seed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < k; i++) // k 是hash函数的个数
{
Pos[i] = (hash1 + i*hash2) % m; // m 是位图的⼤⼩
}
// 通过这种⽅式来模拟 k 个hash函数 跟我们前⾯开放寻址法 双重hash是⼀样的思路















 1356
1356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









