







python中文件的基本操作
1 打开文件:open函数
- 格式:
open('path','mode')
| 模式 | 描述 |
|---|---|
| r | 默认模式:以只读方式打开文件,文件的指针将会放在文件的开头 |
| r+ | 打开一个文件用于读写,文件指针将会放在文件的开头 |
| w | 打开一个文件只用于写入,如果该文件已存在则打开文件,并从开头开始编辑,会覆盖原文件的内容;如果该文件不存在,创建新文件 |
| w+ | 打开一个文件用于读写,如果该文件已存在则打开文件,并从开头开始编辑,会覆盖原文件的内容;如果该文件不存在,创建新文件 |
| a | 打开一个文件用于追加,如果该文件已存在,文件指针将会放在文件的结尾,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |
| 打开一个文件用于读写,如果该文件已存在,文件指针将会放在文件的结尾,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入 |

(1)读取文件内容:r
f=open('song.txt','r') ## 打开的文件名,模式
f1=f.read()
print(f1)
输出:
hello python
hello java
hello sql
(2)写入文件内容:w
f=open('song.txt','w')
f1=f.write('hello world')
print(f1)
输出:11 ##返回写入的总字节数

(3)追加文件内容:a
f=open('song.txt','a')
f1=f.write('hello linux')
print(f1) ## 返回写入的总字节数

2 文件操作方法
(1) read() 方法用来直接读取字节到字符串中, 最多读取给定数目个字节. 如果没有给定 size 参数(默认值为 -1)或者 size值为负, 文件将被读取直至末尾
(2)readline() 方法读取打开文件的一行(读取下个行结束符之前的所有字节). 然后整行,包括行结束符,作为字符串返回
f=open('song.txt','r')
f1=f.readline()
print(f1) ## hello world
(3)readlines():读取所有(剩余的)行然后把它们作为一个字符串列表返回
f=open('song.txt','r')
f1=f.readlines()
print(f1)
输出:
['hello world\n', 'hello linux']
(4)f.close() :关闭文件
(5)f.seek() :对文件进行指针偏移操作,有三种模式,
seek(0,0) 默认移动到文件开头或简写成seek(0)
seek(x,1) 表示从当前指针位置向后移x(正数)个字节,如果x是负数,则是当前位置向前移动x个字节
seek(x,2) 表示从文件末尾向前后移x(正数)个字节,如果x负数,则是从末尾向前移动x个字节
(6)f.tell():显示当前文件的指针所在位置
- 可以使用with语句打开文件,不需要关闭,可以同时打开多个文件
with open('song.txt','a+') as f: ## 打开文件
print(f.tell()) ## 当前指针位置 24
f.seek(0,0) ## 指针移动到文件开头
print(f.tell()) ## 0
f.seek(0,1) ## 当前指针位置向后移动0个字节
print(f.tell()) ## 0
f.seek(0,2) ## 指针移动到文件末尾
print(f.tell()) ## 24
3 os模块
Python的os模块提供了执行文件处理操作的方法
(1)查看系统的信息
import os
print(os.name) ## 获取操作系统类型
print(os.environ) ## 获取系统的环境变量
print(os.getcwd())
## 查看当前目录:C:\Users\kang~\PycharmProjects\pythonProject3

(2) 目录名和文件名拼接
- os.path.dirname获取某个文件对应的目录名
- __file__当前文件
- join拼接, 将目录名和文件名拼接起来
import os
BASE_DIR=os.path.dirname(__file__)
file=os.path.join(BASE_DIR,'text.txt')
print(file) ## C:/Users/kang~/PycharmProjects/pythonProject3\text.txt
4 json模块
(1) 将python对象编码成json字符串
import json
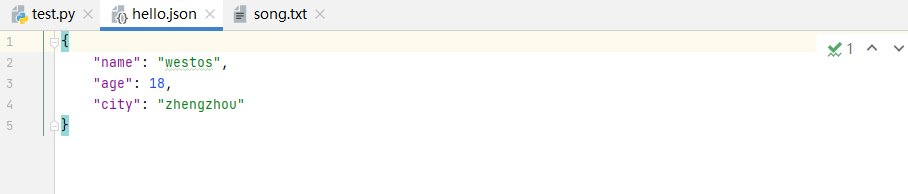
users = {'name':'westos', "age":18, 'city':'zhengzhou'}
json_str = json.dumps(users)
with open('hello.json', 'w') as f:
# indent=4: 缩进为4个空格
json.dump(users, f, indent=4)
print("存储成功")
print(json_str, type(json_str))
输出:
存储成功
{"name": "westos", "age": 18, "city": "zhengzhou"} <class 'str'>
(2)将json字符串解码成python对象
import json
with open('hello.json') as f:
obj=json.load(f)
print(obj,type(obj))
输出:
{'name': 'westos', 'age': 18, 'city': 'zhengzhou'} <class 'dict'>
5 存储为excel文件
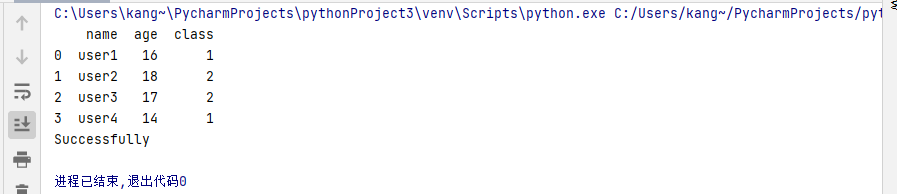
import pandas
users = [
{'name': 'user1', 'age': 16, 'class': 1},
{'name': 'user2', 'age': 18, 'class': 2},
{'name': 'user3', 'age': 17, 'class': 2},
{'name': 'user4', 'age': 14, 'class': 1}
]
df = pandas.DataFrame(users)
print(df)
df.to_excel('users.xlsx')
print('Successfully')

7 练习:词频统计
- 读取文件,统计每个单词出现的次数
(1)方法一
with open('song.txt') as f:
words = f.read().split()
dick1 = {}
for word in words:
if word in dick1:
dick1[word] += 1
else:
dick1[word] = 1
print(dick1)
输出:
{'hello': 5, 'world': 2, 'linux': 2, 'k8s': 1, 'os': 1, 'windows': 1}
(2)方法二
from collections import Counter
with open('song.txt') as f:
words = f.read().split()
Count = Counter(words)
print(Count)
输出:
Counter({'hello': 5, 'world': 2, 'linux': 2, 'k8s': 1, 'os': 1, 'windows': 1})














 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









