






一、准备虚拟机资源
- 虚拟机清单
| 机器名称 | IP地址 | 角色 |
|---|---|---|
| rancher | 10.211.55.200 | 管理K8S集群 |
| k8svip | 10.211.55.199 | K8S VIP |
| master01 | 10.211.55.201 | K8S集群主节点 |
| master02 | 10.211.55.202 | K8S集群主节点 |
| master03 | 10.211.55.203 | K8S集群主节点 |
| node01 | 10.211.55.211 | K8S集群从节点 |
| node02 | 10.211.55.212 | K8S集群从节点 |
| 本篇完成的7台虚拟机(3台master、2台node、1台k8svip、1台rancher),可下载导入使用 链接: https://pan.baidu.com/s/1huTlZnj5s-SKc5TYFo7I7A?pwd=6666 --来自百度网盘超级会员v7的分享 | ||
注:密码均为 123456
二、配置信息
2.1 配置免密登录
# 在本地执行,把我本机的密匙批量发送到所有主机上,就可以实现免密登录
vim ~/.ssh/config
# 内容BEIGIN
Host k8svip
HostName 10.211.55.199
User root
Host rancher
HostName 10.211.55.200
User root
Host master01
HostName 10.211.55.201
User root
Host master02
HostName 10.211.55.202
User root
Host master03
HostName 10.211.55.203
User root
Host node01
HostName 10.211.55.211
User root
Host node02
HostName 10.211.55.212
User root
# 内容END
ssh-copy-id k8svip
ssh-copy-id rancher
ssh-copy-id master01
ssh-copy-id master02
ssh-copy-id master03
ssh-copy-id node01
ssh-copy-id node02
cd
mkdir bins
cd bins && vim k8svip
ssh -i ~/.ssh/id_rsa root@10.211.55.199
vim rancher
ssh -i ~/.ssh/id_rsa root@10.211.55.200
vim master01
ssh -i ~/.ssh/id_rsa root@10.211.55.201
vim master02
ssh -i ~/.ssh/id_rsa root@10.211.55.202
vim master03
ssh -i ~/.ssh/id_rsa root@10.211.55.203
vim node01
ssh -i ~/.ssh/id_rsa root@10.211.55.211
vim node02
ssh -i ~/.ssh/id_rsa root@10.211.55.212
chmod +x k8svip master01 master02 master03 node01 node02
修改 /etc/hosts ,添加如下内容
cat >> /etc/hosts << EOF
10.211.55.199 k8svip
10.211.55.201 master01
10.211.55.202 master02
10.211.55.203 master03
10.211.55.211 node01
10.211.55.212 node02
EOF
关闭防火墙和启用时间同步等
# 关闭防火墙(在3台master运行)
systemctl stop firewalld && systemctl disable firewalld
# 时间同步(在3台master运行)
yum install ntpdate -y && ntpdate time.windows.com
# 关闭swap(在3台master运行)
swapoff -a && sed -ri 's/.*swap.*/#&/' /etc/fstab
# 关闭selinux(在3台master运行)
# sed -i 's/enforcing/disabled/' /etc/selinux/config && setenforce 0
setenforce 0
# 安装必要的系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
三、安装docker19.03.9
所有master+node+rancher执行
# 1 切换镜像源
[root@master ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 2 查看当前镜像源中支持的docker版本
[root@master ~]# yum list docker-ce --showduplicates
# 3 安装特定版本的docker-ce
# 必须指定--setopt=obsoletes=0,否则yum会自动安装更高版本
[root@master ~]# yum install --setopt=obsoletes=0 docker-ce-18.06.3.ce-3.el7 -y
或(推荐) yum install -y docker-ce-19.03.9-3.el7 docker-ce-cli-19.03.9-3.el7
# 4 配置文件
vim /etc/systemd/system/docker.service
# 内容BEGIN
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
# 内容END
chmod +x /etc/systemd/system/docker.service
# 5 启动docker
# 重新加载配置文件
systemctl daemon-reload
# 启动docker
systemctl start docker
# 设置开机启动
systemctl enable docker.service
# 6 检查docker状态和版本
[root@master ~]# docker version
# 查询镜像加速地址: https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
# 可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://3io13djb.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload && sudo systemctl restart docker
# 7 配置ipv4
# 1 安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadmin -y
# 如果提示No package ipvsadmin available.需要使用 yum install -y ipvsadm
# 2 添加需要加载的模块写入脚本文件
[root@master ~]# cat <<EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
# 3 为脚本文件添加执行权限
[root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules
# 4 执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 5 查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
四、部署K8S
4.1 网络配置 iptables
对iptables内部的nf-call需要打开的内生的桥接功能
vim /etc/sysctl.d/k8s.conf
# 内容BEGIN
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
vm.swappiness=0
# 内容END
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
4.2 配置kubernetes源
vim /etc/yum.repos.d/kubernetes.repo
# 内容BEGIN
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-aarch64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
# 内容END
# 清除缓存
yum clean all
# 把服务器的包信息下载到本地电脑缓存起来,makecache建立一个缓存
yum makecache
4.3 安装kubelet kubeadm kubectl
# 当不指定具体版本时,将下载当前yum源对应的最新版本
yum install -y kubelet kubeadm kubectl
# 也可以指定版本,建议指定如下版本, 安装指定版本的kubelet,kubeadm,kubectl
yum install -y kubelet-1.20.11 kubeadm-1.20.11 kubectl-1.20.11
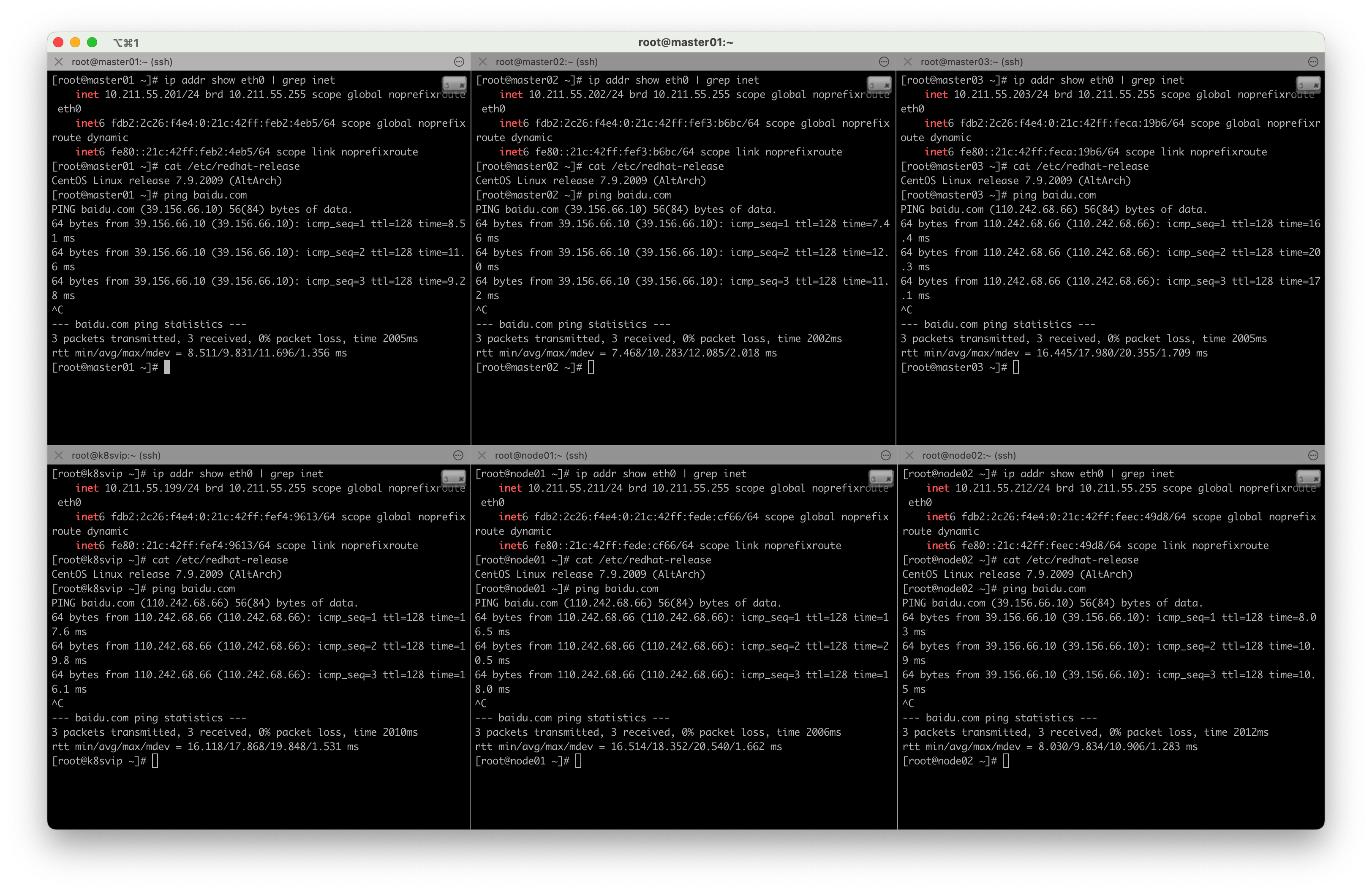
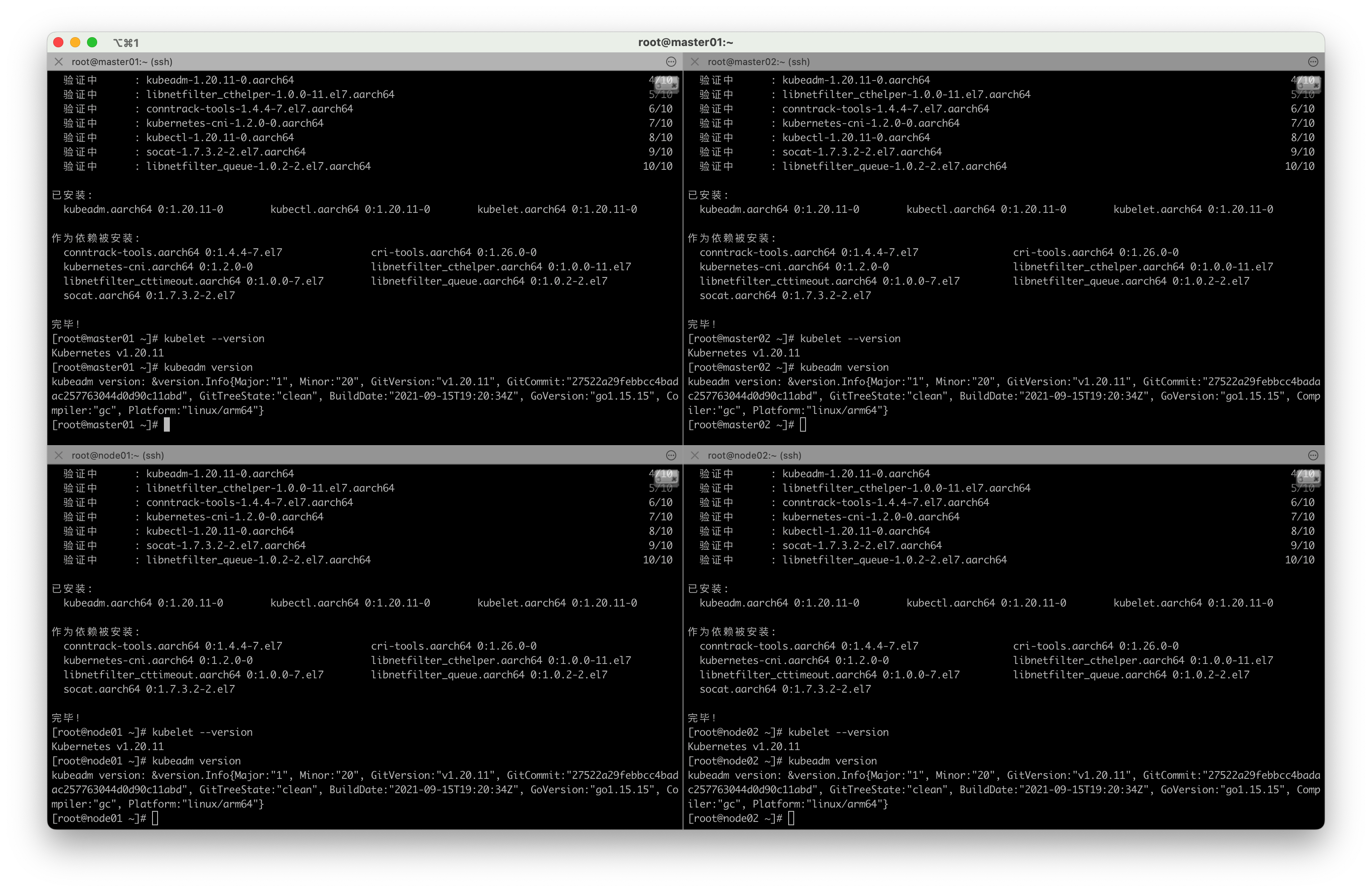
安装完成后,查看K8S版本
# 查看kubelet版本
[root@master01 ~]# kubelet --version
Kubernetes v1.20.11
# 查看kubeadm版本
[root@master01 ~]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.11", GitCommit:"27522a29febbcc4badac257763044d0d90c11abd", GitTreeState:"clean", BuildDate:"2021-09-15T19:20:34Z", GoVersion:"go1.15.15", Compiler:"gc", Platform:"linux/arm64"}
4.4 启动kubelet并设置开机启动服务
4.4.1 重新加载配置文件
systemctl daemon-reload
4.4.2 启动kubelet
systemctl start kubelet
4.4.3 查看kubelet启动状态
systemctl status kubelet
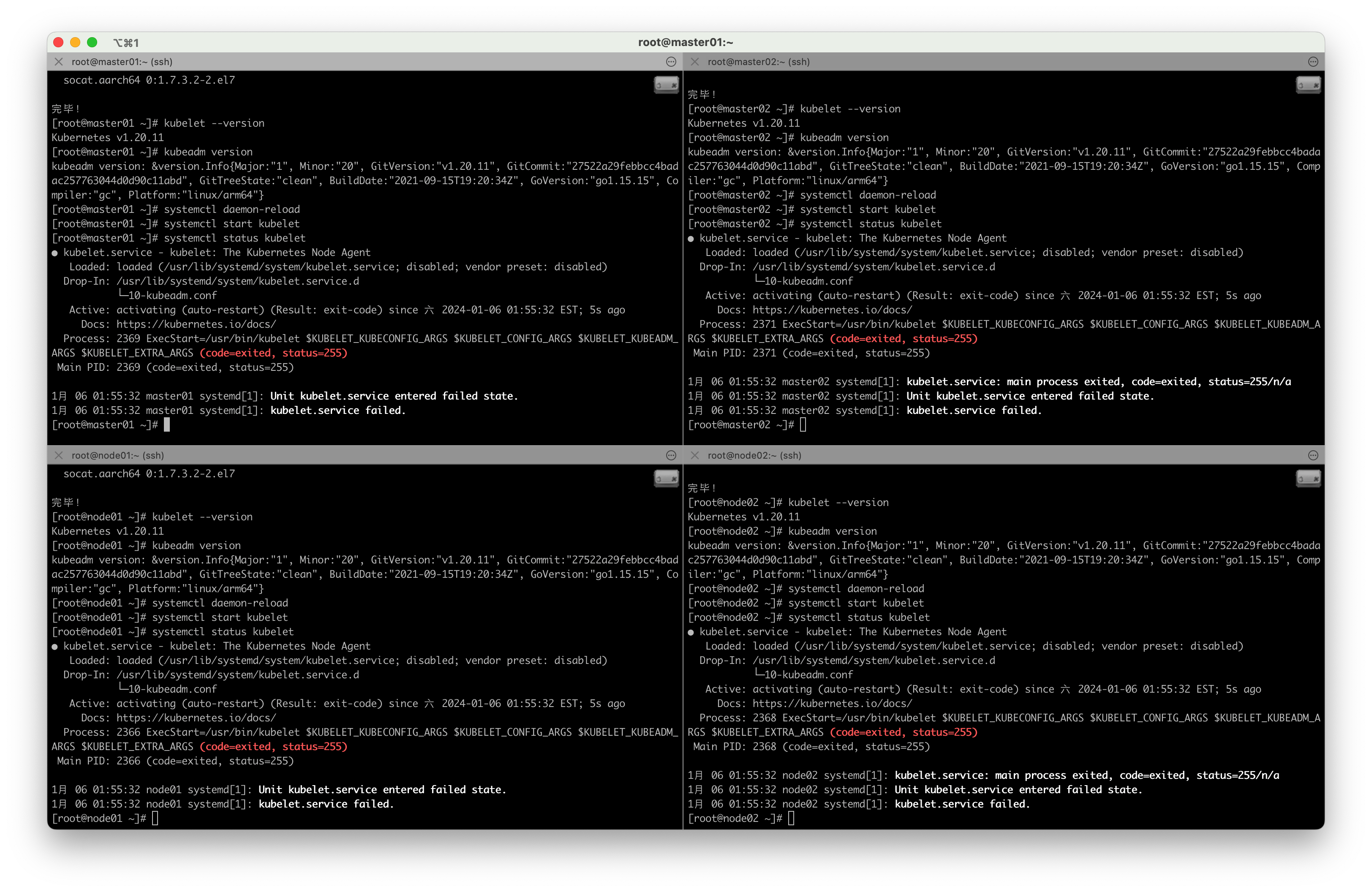
没启动成功,报错先不管,后面的 kubeadm init 会拉起
4.4.4 设置开机自启动
[root@master01 ~]# systemctl enable kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
4.4.5 查看kubelet开机启动状态
enabled-开启
disabled-关闭
[root@master01 ~]# systemctl is-enabled kubelet
enabled
4.4.6 查看日志
journalctl -xefu kubelet
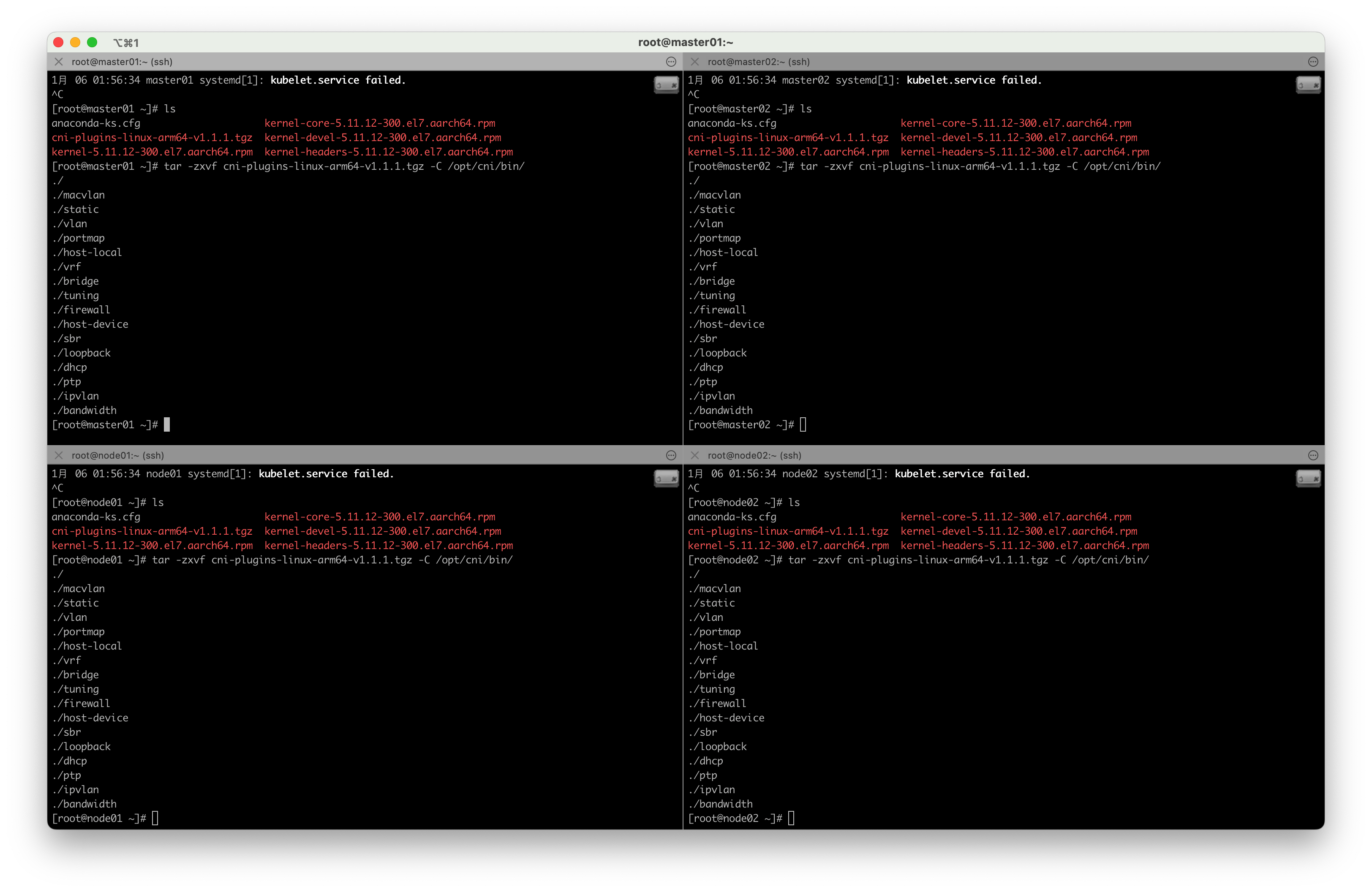
# 下载 cni-plugins-linux-arm64-v1.1.1.tgz 插件
$ wget https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-arm64-v1.1.1.tgz
# 解压 cni-plugins-linux-arm64-v1.1.1.tgz 插件 并且复制到 /opt/cni/bin/
tar -zxvf cni-plugins-linux-arm64-v1.1.1.tgz -C /opt/cni/bin/
准备集群镜像
# 在安装kubernetes集群之前,必须要提前准备好集群需要的镜像,所需镜像可以通过下面命令查看
[root@master ~]# kubeadm config images list
# 下载镜像
# 此镜像在kubernetes的仓库中,由于网络原因,无法连接,下面提供了一种替代方案
images=(
kube-apiserver:v1.20.11
kube-controller-manager:v1.20.11
kube-scheduler:v1.20.11
kube-proxy:v1.20.11
pause:3.2
etcd:3.4.13-0
coredns:1.7.0
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
node
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.20.11
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.20.11 k8s.gcr.io/kube-proxy:v1.20.11
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.20.11
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0 coredns:1.7.0
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0
4.7 keepalived + haproxy 搭建高用集群
# https://github.com/kubernetes/kubeadm/blob/master/docs/ha-considerations.md#options-for-software-load-balancing
# 3台master执行
yum install haproxy keepalived -y
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
#从本地复制到master主机
cd
scp Downloads/k8s/haproxy.cfg root@10.211.55.201:/etc/haproxy/haproxy.cfg
scp Downloads/k8s/check_apiserver.sh root@10.211.55.201:/etc/keepalived/check_apiserver.sh
scp Downloads/k8s/keepalived.conf root@10.211.55.201:/etc/keepalived/keepalived.conf
scp Downloads/k8s/haproxy.cfg root@10.211.55.202:/etc/haproxy/haproxy.cfg
scp Downloads/k8s/check_apiserver.sh root@10.211.55.202:/etc/keepalived/check_apiserver.sh
scp Downloads/k8s/keepalived.conf root@10.211.55.202:/etc/keepalived/keepalived.conf
scp Downloads/k8s/haproxy.cfg root@10.211.55.203:/etc/haproxy/haproxy.cfg
scp Downloads/k8s/check_apiserver.sh root@10.211.55.203:/etc/keepalived/check_apiserver.sh
scp Downloads/k8s/keepalived.conf root@10.211.55.203:/etc/keepalived/keepalived.conf
# 3台master执行
systemctl enable keepalived --now
systemctl enable haproxy --now
systemctl restart keepalived && systemctl restart haproxy
# systemctl status keepalived异常dead, 查看keepalived日志
journalctl -u keepalived
# (VI_1): unknown state 'SLAVE', defaulting to BACKUP
# https://www.ai2news.com/blog/2688548/
4.7 初始化K8S集群Master
注意,此操作只在规划的K8S Master的MASTER服务器(即本篇master01)上执行
# 执行初始化命令 初始化k8s集群
kubeadm init \
--control-plane-endpoint k8svip:8443 \
--kubernetes-version=v1.20.11 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--upload-certs
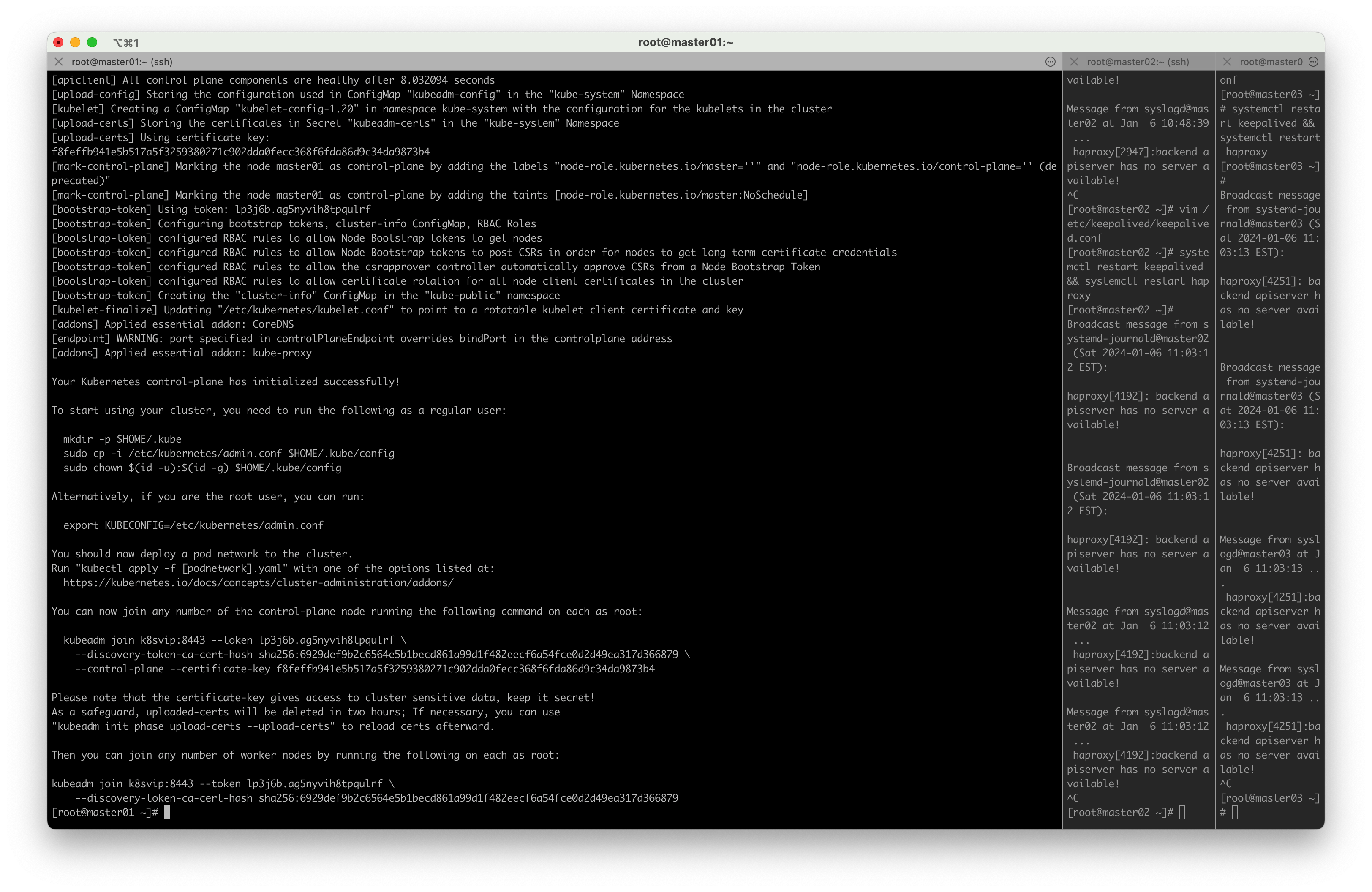
record
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join k8svip:8443 --token lp3j6b.ag5nyvih8tpqulrf \
--discovery-token-ca-cert-hash sha256:6929def9b2c6564e5b1becd861a99d1f482eecf6a54fce0d2d49ea317d366879 \
--control-plane --certificate-key f8feffb941e5b517a5f3259380271c902dda0fecc368f6fda86d9c34da9873b4
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8svip:8443 --token lp3j6b.ag5nyvih8tpqulrf \
--discovery-token-ca-cert-hash sha256:6929def9b2c6564e5b1becd861a99d1f482eecf6a54fce0d2d49ea317d366879
在master02和master03上执行
kubeadm join k8svip:8443 --token lp3j6b.ag5nyvih8tpqulrf \
--discovery-token-ca-cert-hash sha256:6929def9b2c6564e5b1becd861a99d1f482eecf6a54fce0d2d49ea317d366879 \
--control-plane --certificate-key f8feffb941e5b517a5f3259380271c902dda0fecc368f6fda86d9c34da9873b4
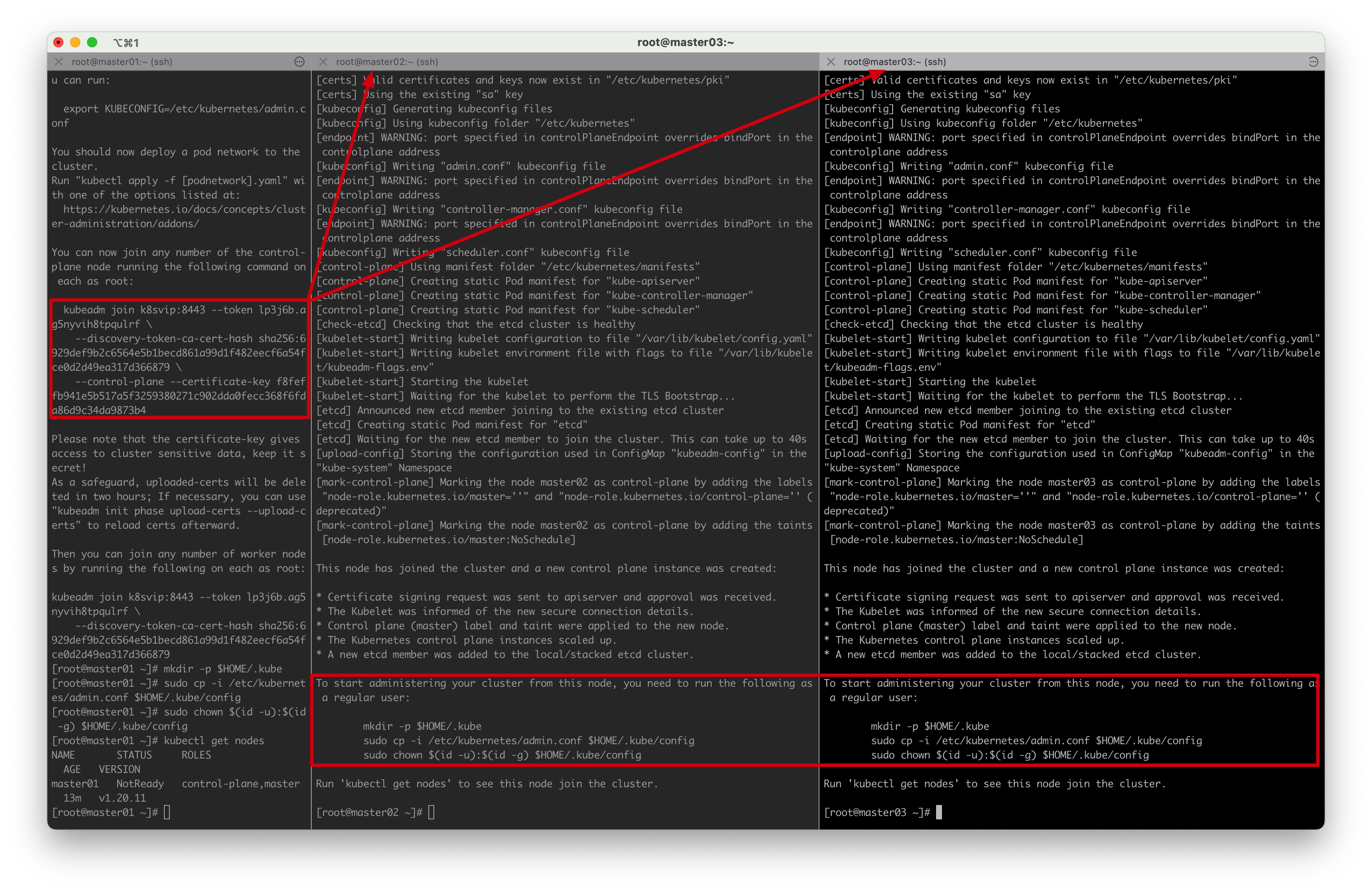
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 23m v1.20.11
master02 NotReady control-plane,master 7m57s v1.20.11
master03 NotReady control-plane,master 7m4s v1.20.11
在node01和node02上执行
kubeadm join k8svip:8443 --token lp3j6b.ag5nyvih8tpqulrf \
--discovery-token-ca-cert-hash sha256:6929def9b2c6564e5b1becd861a99d1f482eecf6a54fce0d2d49ea317d366879
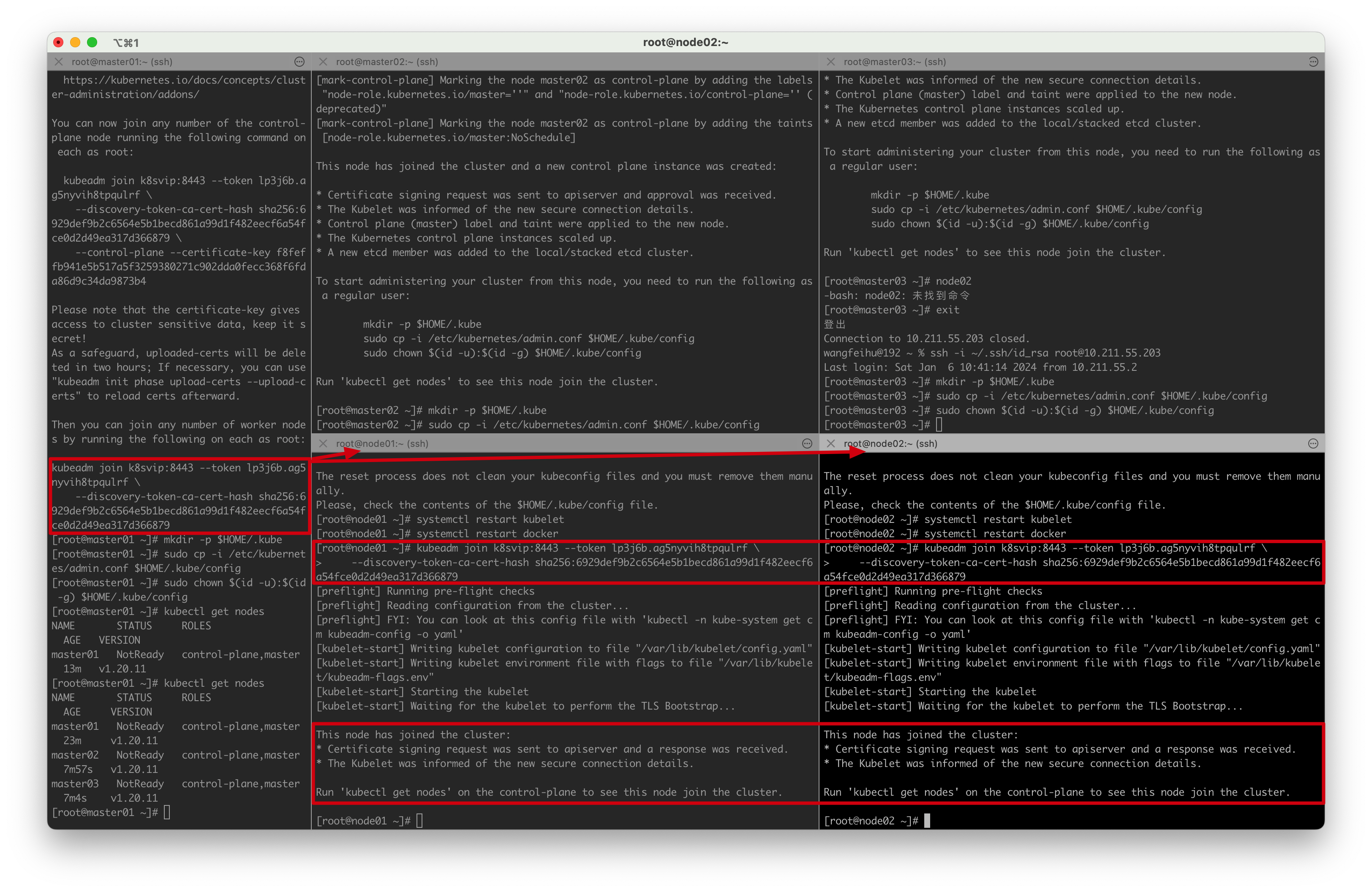
# master01执行
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 47m v1.20.11
master02 NotReady control-plane,master 32m v1.20.11
master03 NotReady control-plane,master 31m v1.20.11
node01 NotReady <none> 98s v1.20.11
node02 NotReady <none> 98s v1.20.11
NotReady原因是没有安装网络插件
部署CNI网络插件
# 下载flannel网络插件, pull master都要执行, master01执行
docker pull quay.io/coreos/flannel:v0.13.1-rc1
# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
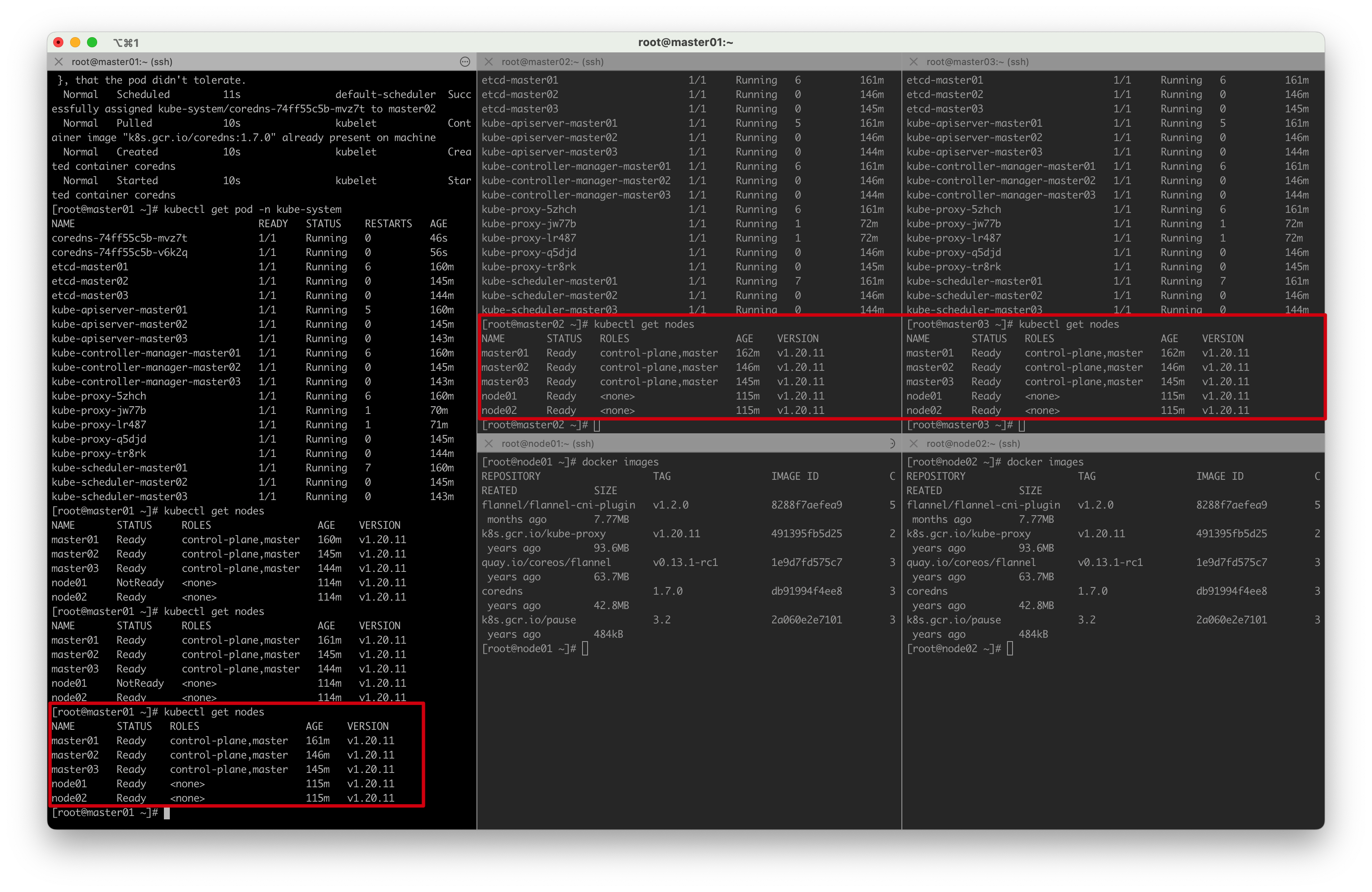
所有节点准备就绪,K8S部署成功!
五、部署Rancher
rancher节点下载部署Rancher2.5.16
# 仅在rancher上执行
[root@rancher ~]# docker pull rancher/rancher:v2.5.16-linux-arm64
v2.5.16-linux-arm64: Pulling from rancher/rancher
d2f2687beb6d: Pull complete
aba8efaaea67: Pull complete
20a1ce6fa2b1: Pull complete
2b812b3c01ac: Pull complete
09f43f47908d: Pull complete
8794f144ec90: Pull complete
0e282afd186a: Pull complete
a05d52249d02: Pull complete
9d0475de7093: Pull complete
1b140f918317: Pull complete
9b48d5529949: Pull complete
b21092b7d9f4: Pull complete
fc9a419c36e7: Pull complete
5c14e1cac5db: Pull complete
8ed65bec68cc: Pull complete
ba4c8f48c714: Pull complete
3c097325aa80: Pull complete
d9dfe0b09bc0: Pull complete
Digest: sha256:3c845285d4a11a738cba9409231c251aab22f3d9910875147cd0d1cf08bb8c49
Status: Downloaded newer image for rancher/rancher:v2.5.16-linux-arm64
docker.io/rancher/rancher:v2.5.16-linux-arm64
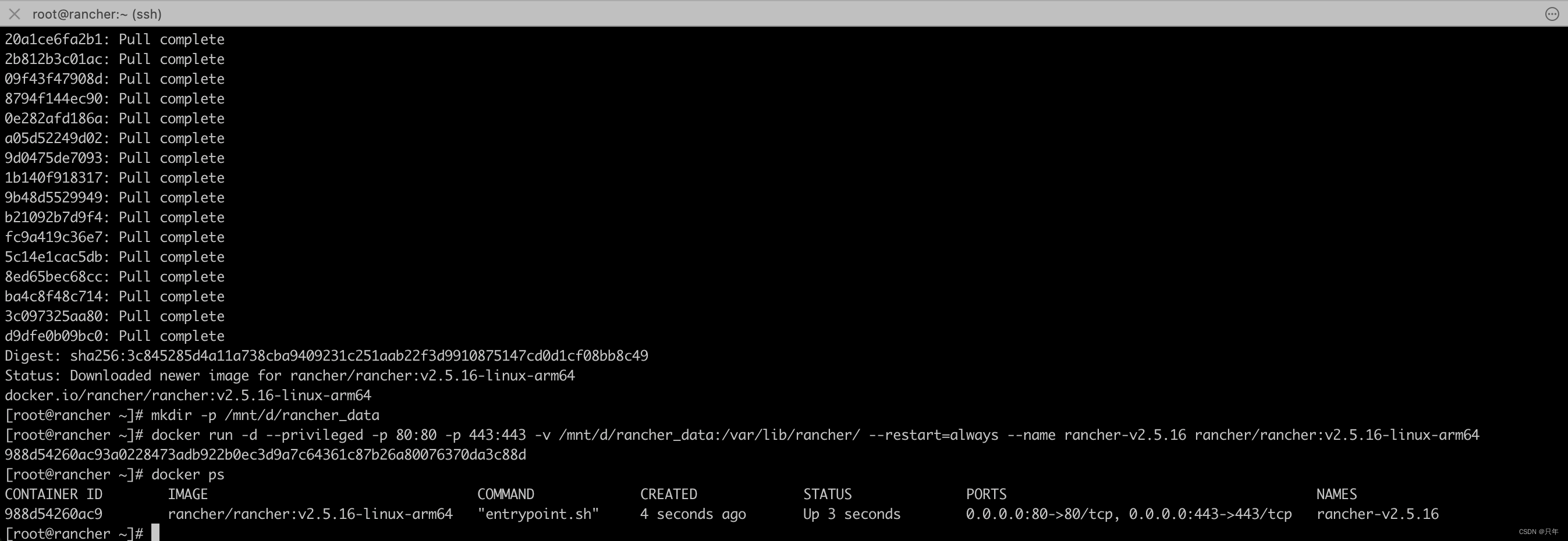
[root@rancher ~]# mkdir -p /mnt/d/rancher_data
[root@rancher ~]# docker run -d --privileged -p 80:80 -p 443:443 -e CATTLE_SYSTEM_CATALOG=bundled -v /mnt/d/rancher_data:/var/lib/rancher/ --restart=always --name rancher-v2.5.16 rancher/rancher:v2.5.16-linux-arm64
988d54260ac93a0228473adb922b0ec3d9a7c64361c87b26a80076370da3c88d
[root@rancher ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
988d54260ac9 rancher/rancher:v2.5.16-linux-arm64 "entrypoint.sh" 4 seconds ago Up 3 seconds 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp rancher-v2.5.16
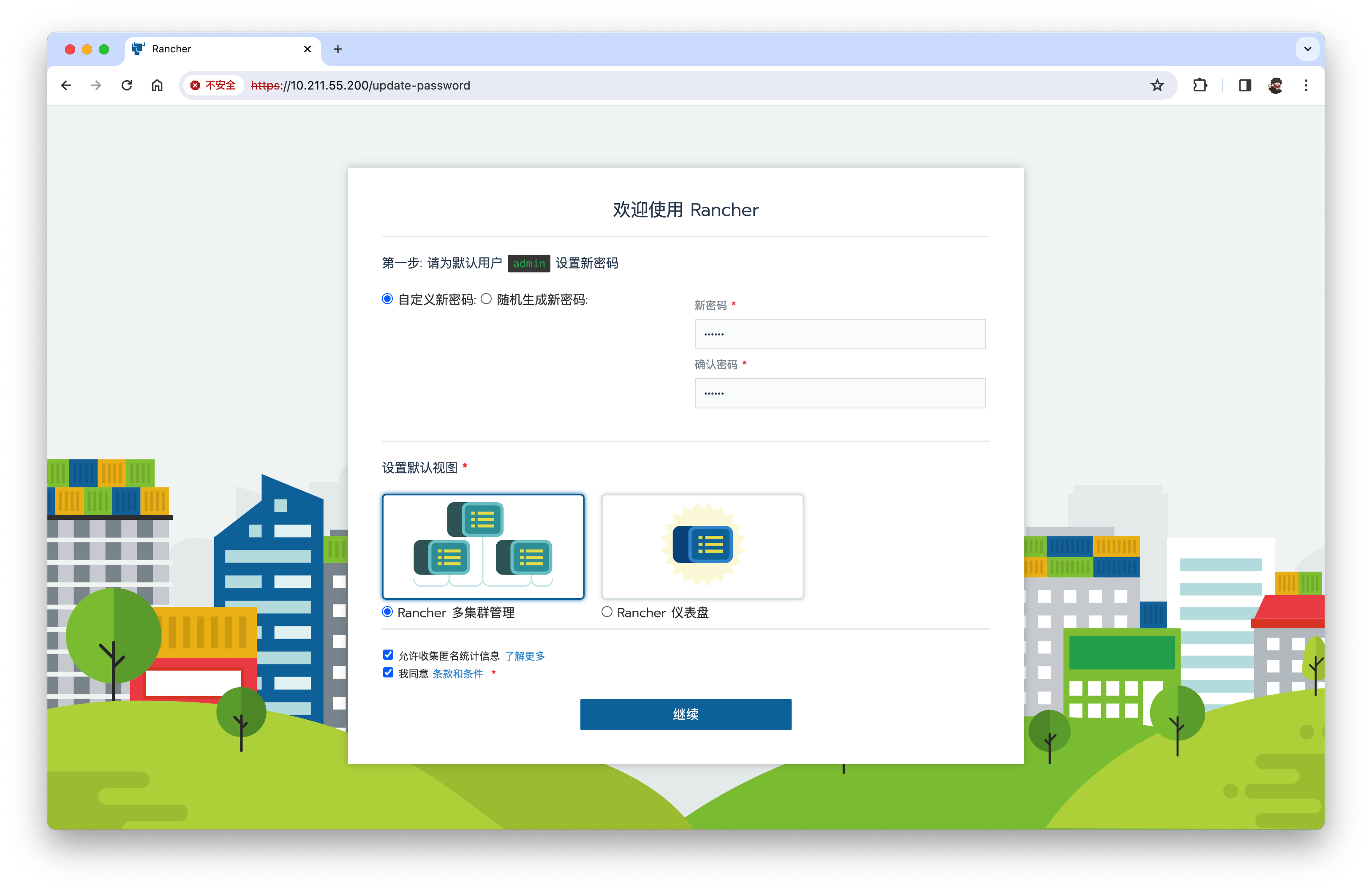
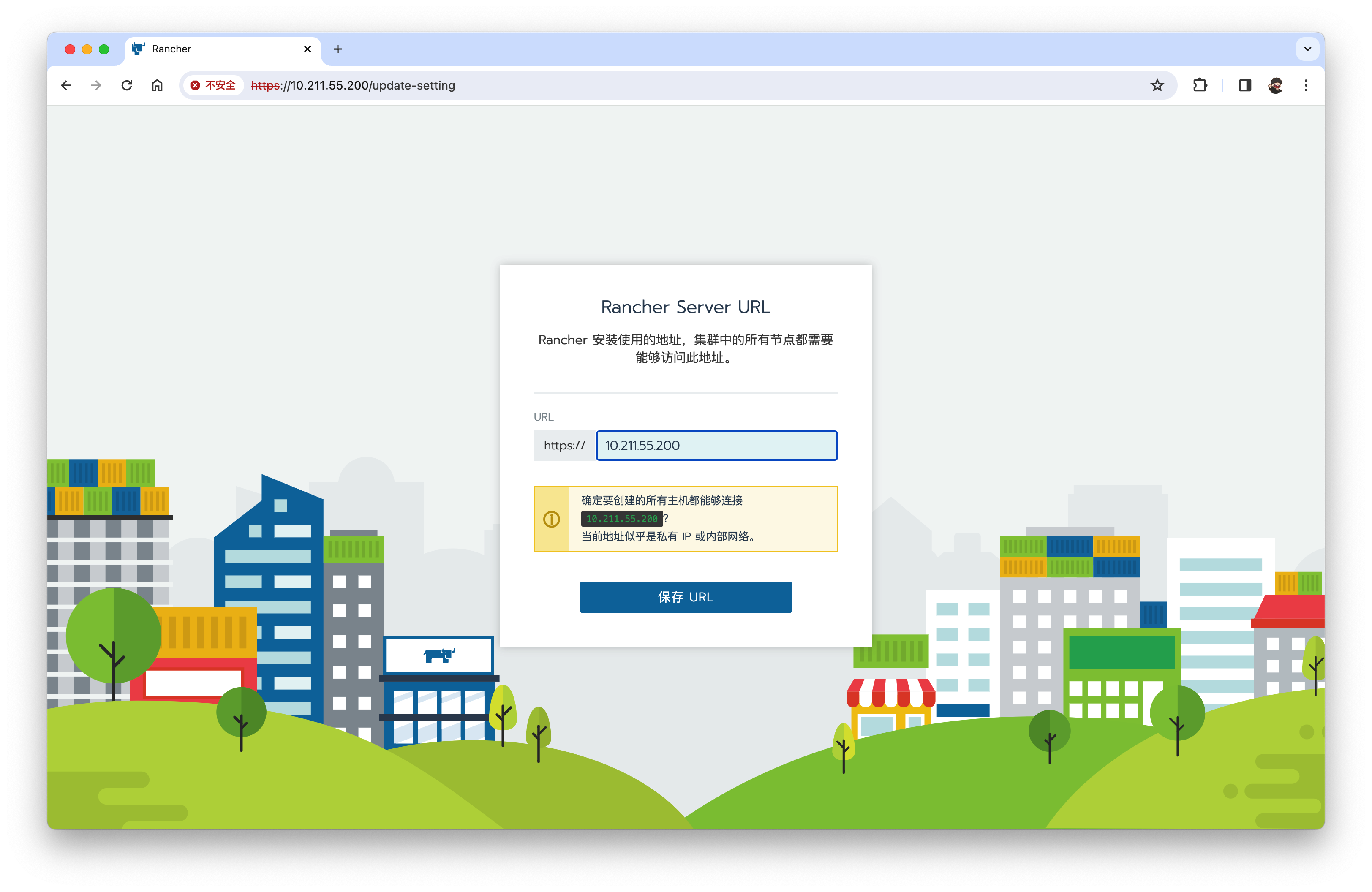
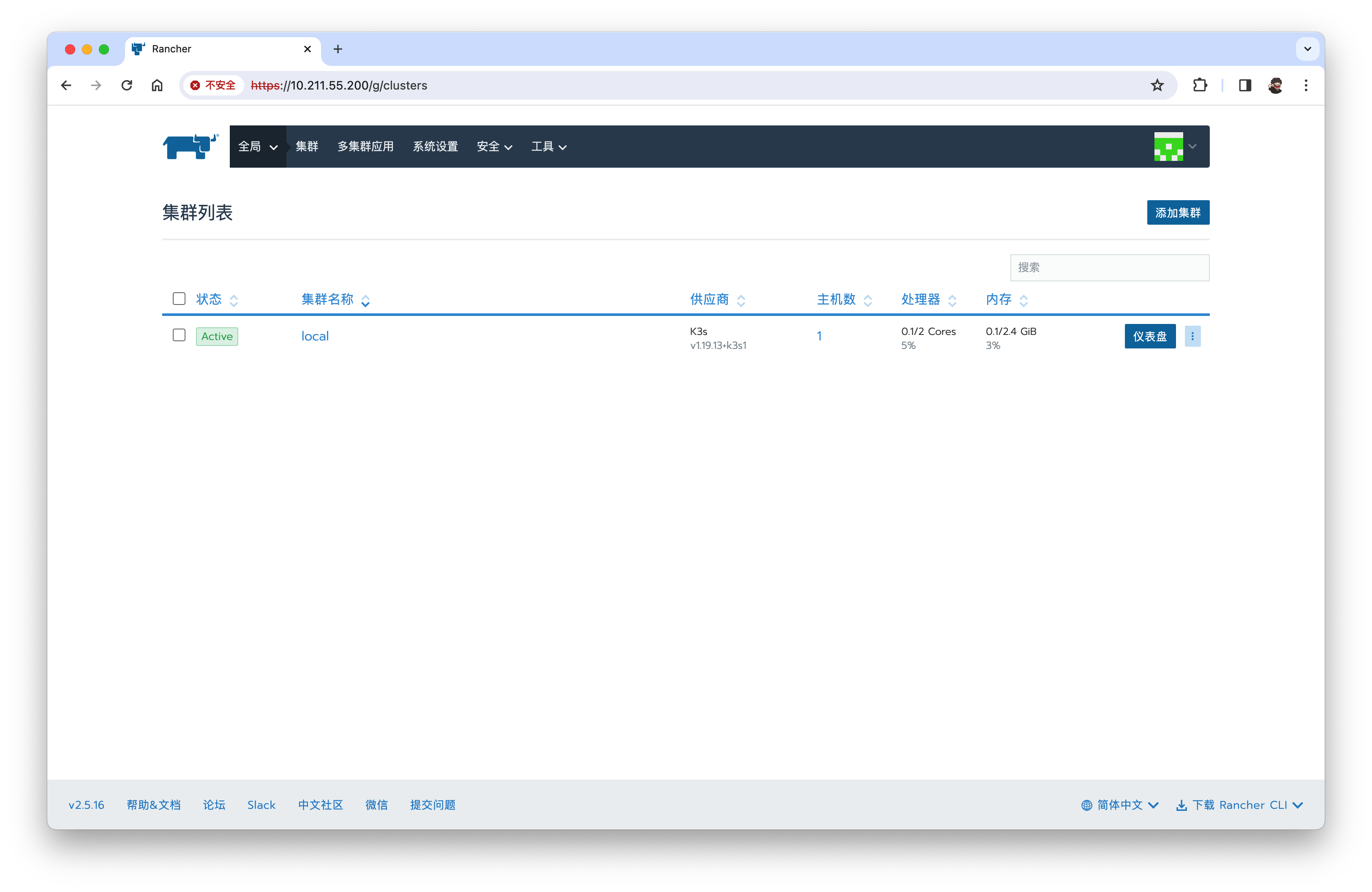
安全→用户→添加用户【dev/123】显示名称dev
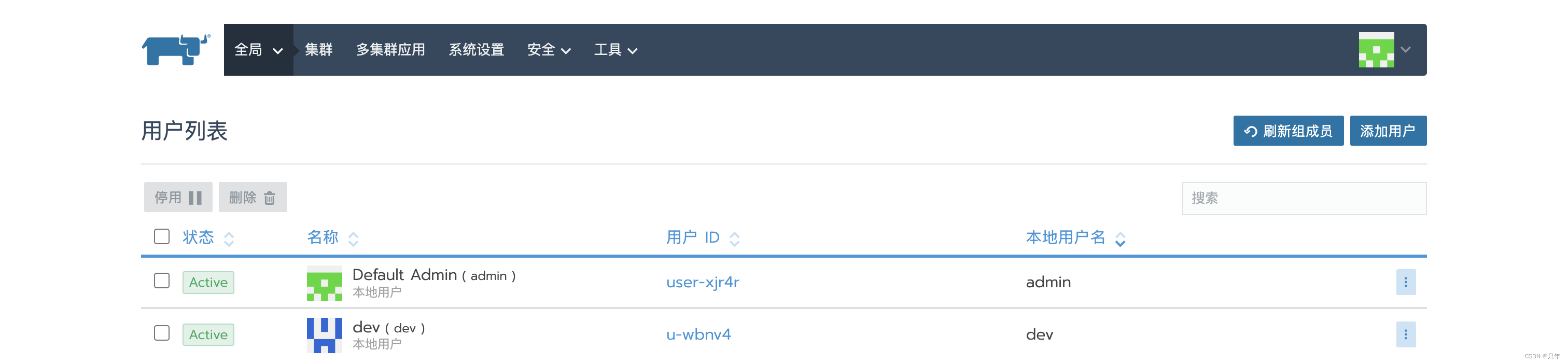
集群→添加集群→导入【dev】、成员角色【dev、owner】、标签【app=dev】
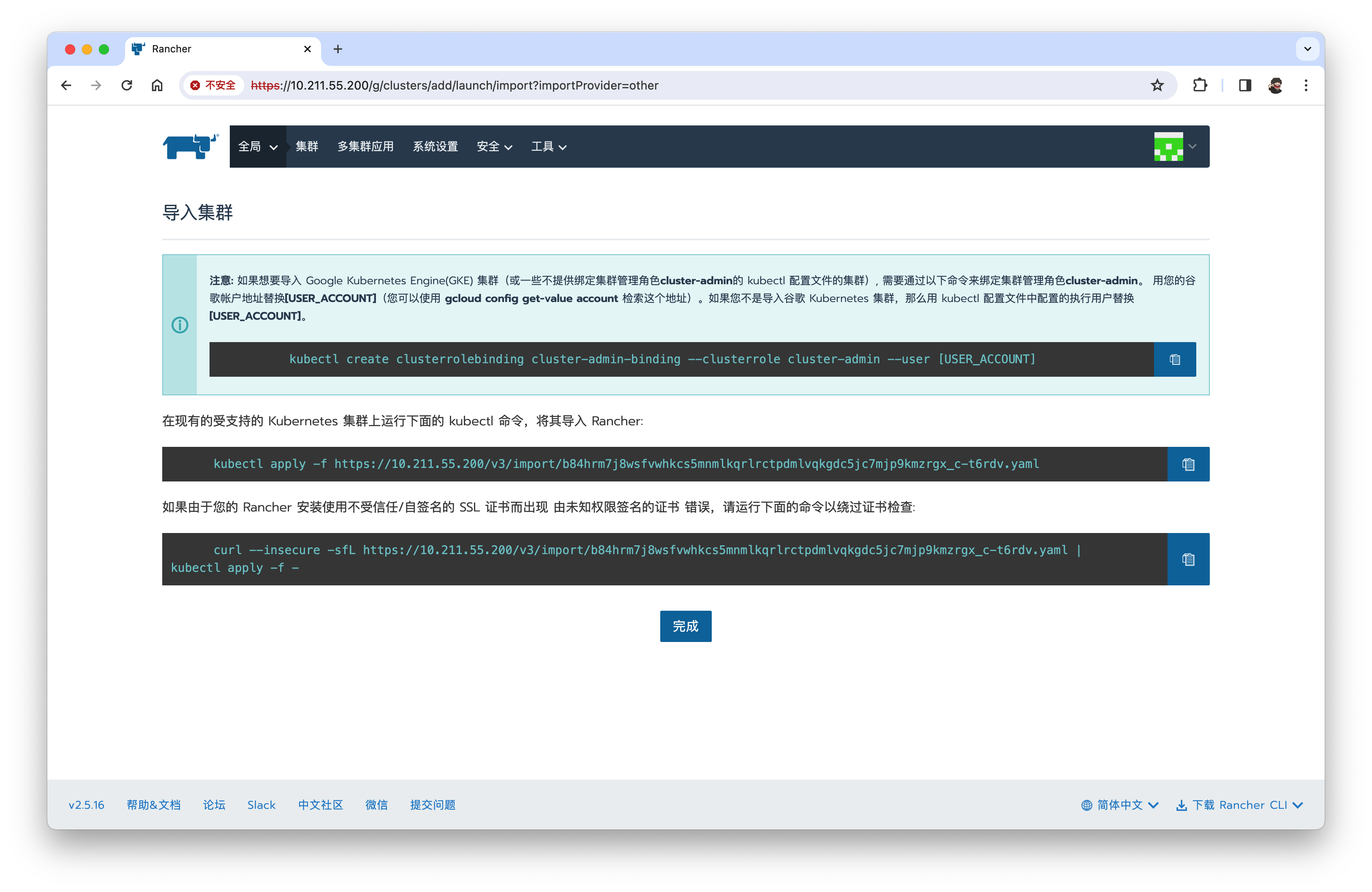
注意: 如果想要导入 Google Kubernetes Engine(GKE) 集群(或一些不提供绑定集群管理角色cluster-admin的 kubectl 配置文件的集群), 需要通过以下命令来绑定集群管理角色cluster-admin。 用您的谷歌帐户地址替换[USER_ACCOUNT](您可以使用 gcloud config get-value account 检索这个地址)。如果您不是导入谷歌 Kubernetes 集群,那么用 kubectl 配置文件中配置的执行用户替换[USER_ACCOUNT]。
kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user [USER_ACCOUNT]
在现有的受支持的 Kubernetes 集群上运行下面的 kubectl 命令,将其导入 Rancher:
# 在master上执行
kubectl apply -f https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml
如果由于您的 Rancher 安装使用不受信任/自签名的 SSL 证书而出现 由未知权限签名的证书 错误,请运行下面的命令以绕过证书检查:
# 在master上执行
curl --insecure -sfL https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml | kubectl apply -f -
执行过程
[root@master01 ~]# kubectl create clusterrolebinding cluster-admin-binding --clusterrole cluster-admin --user admin
clusterrolebinding.rbac.authorization.k8s.io/cluster-admin-binding created
[root@master01 ~]# kubectl apply -f https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml
Unable to connect to the server: x509: certificate has expired or is not yet valid: current time 2024-01-06T15:01:05-05:00 is before 2024-01-07T02:46:34Z
# 如果执行时出现x509错误,则可以通过将对应的yaml文件下载到服务器本地,然后执行apply
wget https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml --no-check-certificate
--2024-01-06 15:02:12-- https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml
正在连接 10.211.55.200:443... 已连接。
警告: 无法验证 10.211.55.200 的由 “/O=dynamiclistener-org/CN=dynamiclistener-ca” 颁发的证书:
无法本地校验颁发者的权限。
警告: 没有匹配的证书主体别名 (Subject Alternative Name)。
请求的主机名为 “10.211.55.200”。
已发出 HTTP 请求,正在等待回应... 没有接收到数据。
重试中。
--2024-01-06 15:02:13-- (尝试次数: 2) https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml
正在连接 10.211.55.200:443... 已连接。
警告: 无法验证 10.211.55.200 的由 “/O=dynamiclistener-org/CN=dynamiclistener-ca” 颁发的证书:
无法本地校验颁发者的权限。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:未指定 [text/plain]
正在保存至: “b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml”
[ <=> ] 4,905 --.-K/s 用时 0s
2024-01-06 15:02:13 (31.8 MB/s) - “b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml” 已保存 [4905]
[root@master01 ~]# kubectl apply -f b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml
clusterrole.rbac.authorization.k8s.io/proxy-clusterrole-kubeapiserver created
clusterrolebinding.rbac.authorization.k8s.io/proxy-role-binding-kubernetes-master created
namespace/cattle-system created
serviceaccount/cattle created
clusterrolebinding.rbac.authorization.k8s.io/cattle-admin-binding created
secret/cattle-credentials-9a6364d created
clusterrole.rbac.authorization.k8s.io/cattle-admin created
deployment.apps/cattle-cluster-agent created
[root@master01 ~]# curl --insecure -sfL https://10.211.55.200/v3/import/b84hrm7j8wsfvwhkcs5mnmlkqrlrctpdmlvqkgdc5jc7mjp9kmzrgx_c-t6rdv.yaml | kubectl apply -f -
clusterrole.rbac.authorization.k8s.io/proxy-clusterrole-kubeapiserver unchanged
clusterrolebinding.rbac.authorization.k8s.io/proxy-role-binding-kubernetes-master unchanged
namespace/cattle-system unchanged
serviceaccount/cattle unchanged
clusterrolebinding.rbac.authorization.k8s.io/cattle-admin-binding unchanged
secret/cattle-credentials-9a6364d unchanged
clusterrole.rbac.authorization.k8s.io/cattle-admin unchanged
deployment.apps/cattle-cluster-agent configured
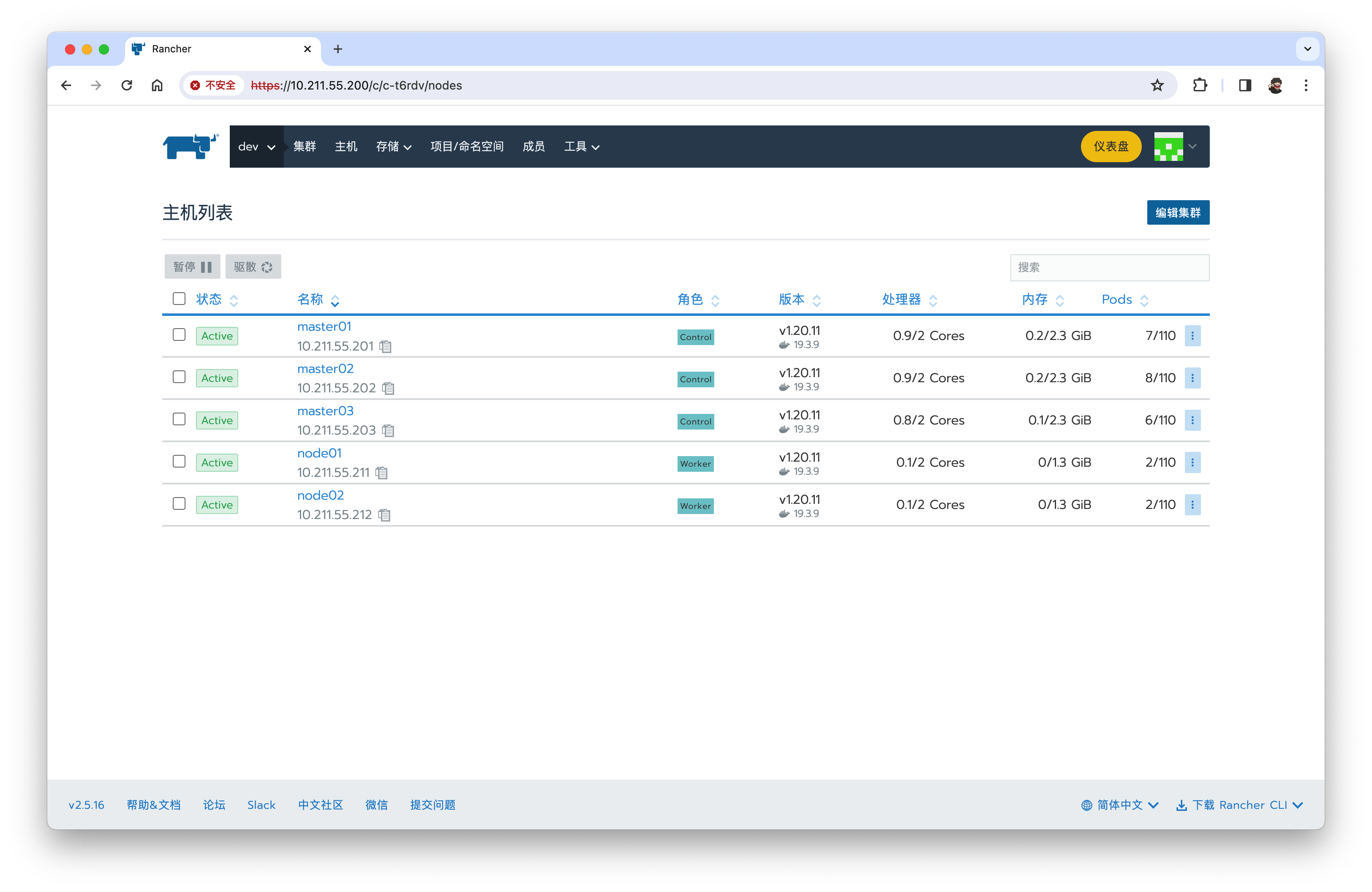
组件Controller Manager与 Scheduler不健康,如下图
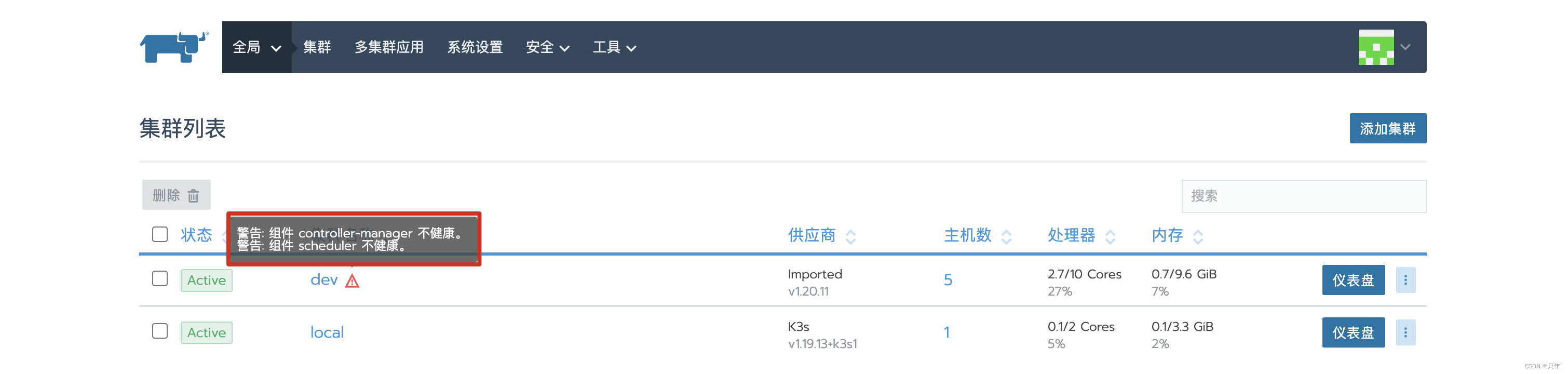
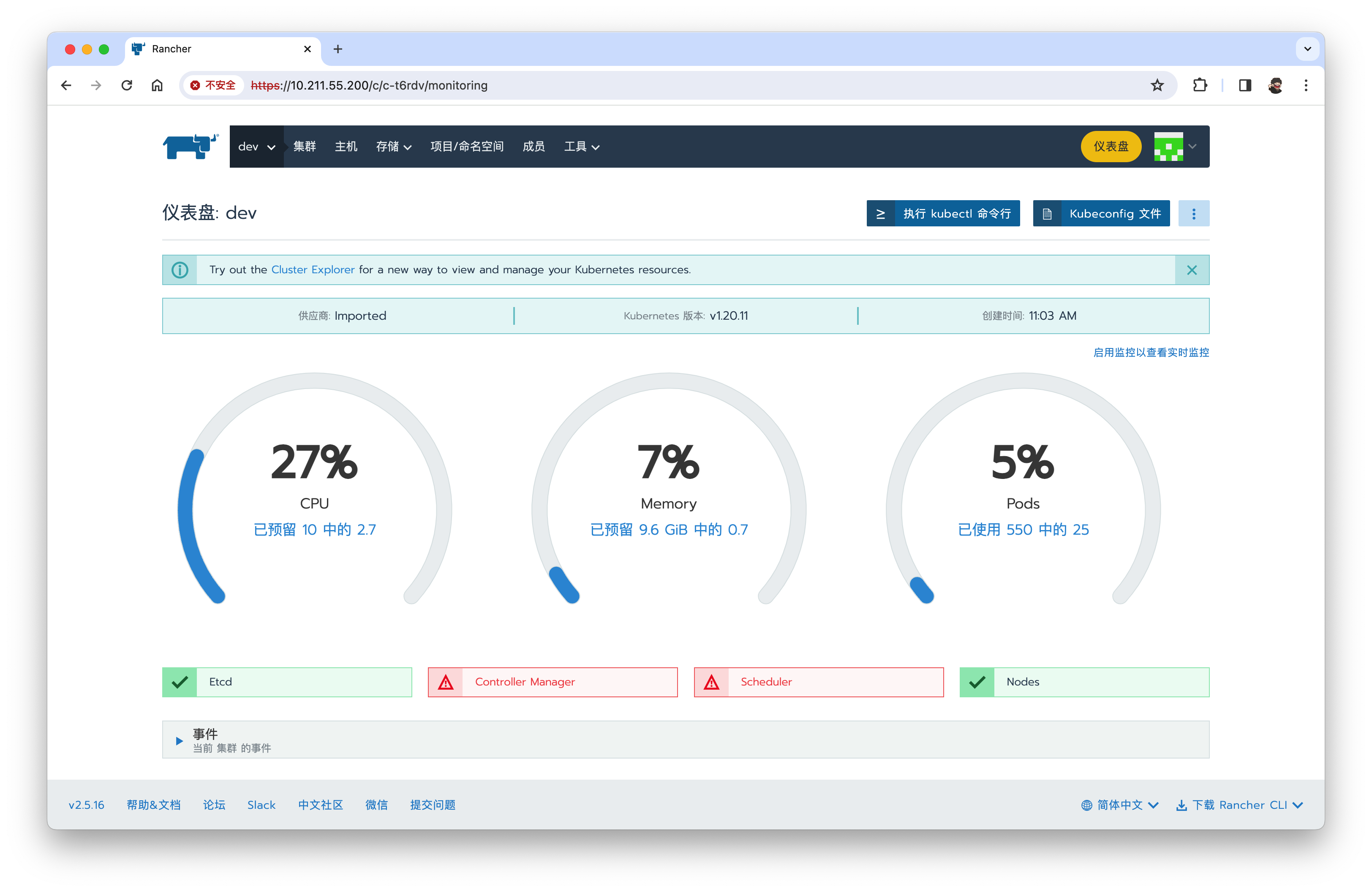
问题解决:
登录到master server机器,修改如下文件
- /etc/kubernetes/manifests/kube-controller-manager.yaml
- /etc/kubernetes/manifests/kube-scheduler.yaml
两个文件中删除 - --port=0 配置项
然后重启kubelete
service kubelet restart
稍等片刻,如果一切顺利,Controller Manager与 Scheduler将恢复健康。
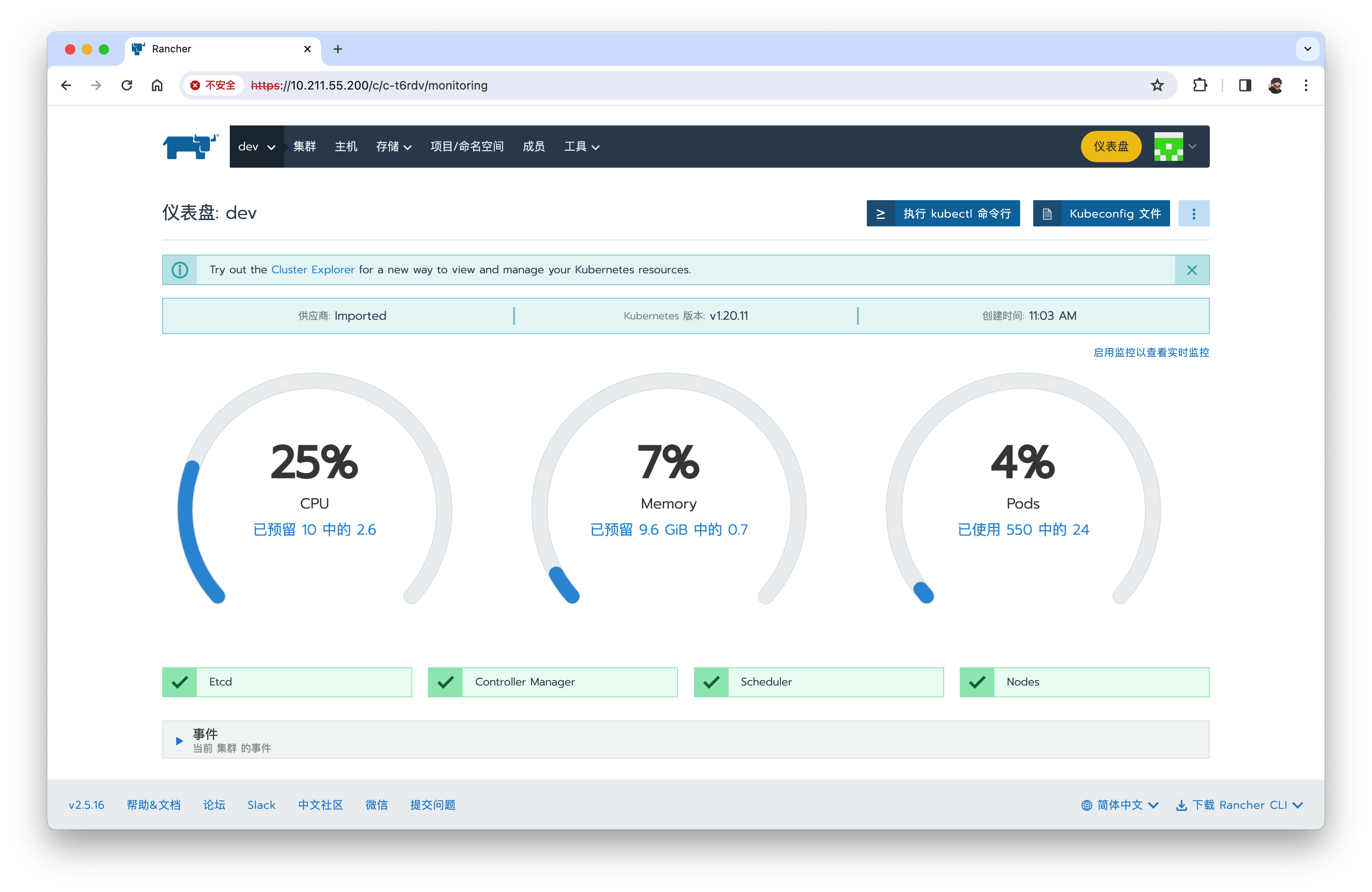
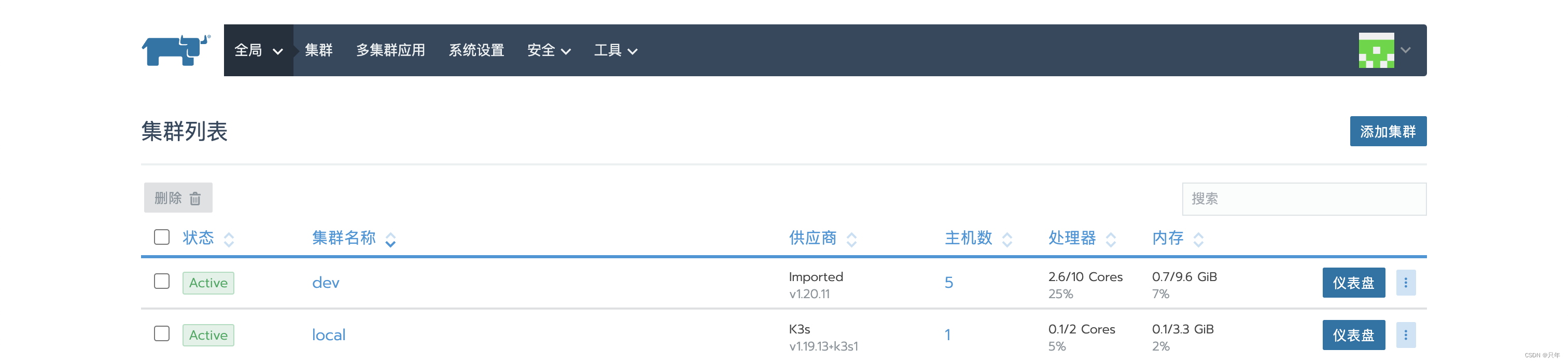
安装成功!
FAQ
# Can't initialize ipvs: Protocol not available
# https://blog.csdn.net/nemo2011/article/details/81219191
# 加载ipvs模块
[root@master03 ~]# lsmod | grep ip_vs
[root@master03 ~]# modprobe ip_vs
[root@master03 ~]# modprobe ip_vs_wrr
[root@master03 ~]# lsmod | grep ip_vs
ip_vs_wrr 20480 0
ip_vs 180224 2 ip_vs_wrr
nf_conntrack 180224 5 xt_conntrack,nf_nat,nf_conntrack_netlink,xt_MASQUERADE,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 16384 4 nf_conntrack,nf_nat,xfs,ip_vs
systemctl restart keepalived && systemctl restart haproxy
# 每次重启机器老这样, 都得按上述链接重新加载
# linux系统启动自动加载模块 ipvs
# sudo vi /etc/sysconfig/modules/ip_vs.modules
# 内容BEGIN
# !/bin/sh
#
# This script will load the necessary kernel modules for IP Virtual Server (IPVS)
modprobe ip_vs
modprobe ip_vs_wrr
# 内容END
sudo chmod +x /etc/sysconfig/modules/ip_vs.modules
sudo systemctl restart network
coredns一直pending
通过kubectl describe pod xxx -n kube-system 查看得知
Warning FailedScheduling 33s (x2 over 33s) default-scheduler 0/5 nodes are available: 5 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate.
# 解决
kubectl taint nodes master01 node.kubernetes.io/not-ready:NoSchedule-
kubectl taint nodes master02 node.kubernetes.io/not-ready:NoSchedule-
kubectl taint nodes master03 node.kubernetes.io/not-ready:NoSchedule-
kubectl taint nodes node01 node.kubernetes.io/not-ready:NoSchedule-
kubectl taint nodes node02 node.kubernetes.io/not-ready:NoSchedule-
时间不同步
# https://www.cnblogs.com/binz/p/16710194.html
# 1.设置系统时区为上海时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 2.安装nptdate
yum install -y ntpdate
# 3.同步网络时间
ntpdate us.pool.ntp.org
参考:
- 安装部署高可用K8S: https://github.com/sskcal/kubernetes/tree/main/vipk8s
- Rancher导入K8S: http://www.bryh.cn/a/639401.html
- SSH如何免密登录服务器: https://blog.csdn.net/u012110870/article/details/122854866
- https://www.ai2news.com/blog/2688548/
- https://blog.csdn.net/nemo2011/article/details/81219191
- https://stackoverflow.com/questions/49112336/container-runtime-network-not-ready-cni-config-uninitialized
- https://blog.csdn.net/weixin_42434700/article/details/134255596
- https://blog.csdn.net/qq_36783142/article/details/102674688
- https://blog.51cto.com/u_16175447/6665202
- https://blog.csdn.net/huz1Vn/article/details/129863806
















 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











