







Hadoop伪分布式下词频成功案例教程
-
工具准备:JDK(1.8.0)、HADOOP相关(3.0.0)、eclipse(2019)
jdk版本如下:

hadoop工具如下:

-
windows环境配置
jdk配置如下图:

hadoop环境变量配置如下:

注意:选择自己对应安装的路径!!并且配置环境变量时,路径名字不要有空格!!图中仅为本文示例,下面的两图可以相同path中的设置如下:

jdk配置如下:

-
HADOOP配置
解压刚才准备的haoop工具

Hadoop-master里的bin文件复制到hadoop-3.0.0里,替换原文件里的bin
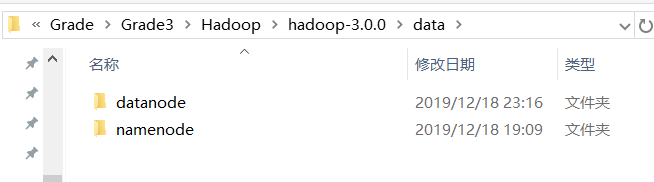
在下面hadoop-3.0.0目录下创建data文件夹
并在data文件夹里分别创建namenode与datanode

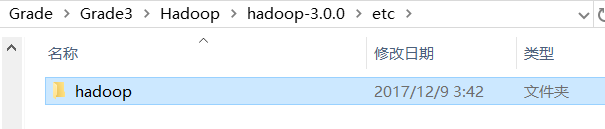
在路径…hadoop-3.0.0\etc\hadoop下修改文件
①core-site.xml(配置默认hdfs的访问端口
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
②hdfs-site.xml(设置复制数为1,即不进行复制。namenode文件路径以及datanode数据路径。)
注:file:/hadoop/data/dfs/namenode修改为自己对应的路径
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>
③将mapred-site.xml.template 名称修改为 mapred-site.xml 后再修改内容(设置mr使用的框架,这里使用yarn)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
④yarn-site.xml(这里yarn设置使用了mr混洗)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
hadoop-env.cmd里的最后加上
set HADOOP_PREFIX=%HADOOP_HOME%
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
- HADOOP测试
在cmd中运行命令 hadoop namenode -format(使用管理员启动cmd)

接着输入start-all,弹出四个窗口如下:

输入jps -
如下为正确显示

- eclipse配置
将此jar放入如下文件夹dropins与plugins里

在Eclipse中设置Hadoop的安装目录
管理员身份启动Eclipse,在主菜单中选择“Window->Preferences”,在弹出的对话框中选择左边的Hadoop Map/Reduce,然后在右边的“Hadoop installation directory”中填入Hadoop的安装目录,如下图所示:

创建并配置Map/Reduce Locations
在主菜单中选择“Window->Show View->Other”,在弹出的对话框中找到并展开“MapReduce Tools”,然后选择“Map/Reduce Locations”,如下图所示:


返回后出现Map/Reduce Locations子窗口,如下图所示:

在“Map/Reduce Locations”子窗口中右键单击,选择“New Hadoop Location”,创建一个新的Hadoop Location。

右键创建文件夹input,再右键refresh,右键上传对应的

**注:**出现如上问题大小为0时,原因是多次格式化
解决办法如下
打开data里的datanode,编辑current里的version,复制clusterID
在打开data里的namenode,编辑current里的version,粘贴刚才的clusterID,保存

重启hadoop,输入stop-all,再start-all,输入jps - 检查是否正确

重启eclipse,重复刚才的步骤,如下:
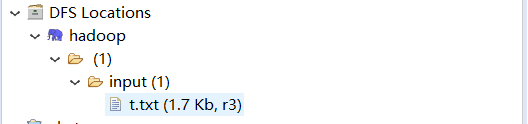
- WordCount代码:
在对应的WordCount工程下建立如下类:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 运行程序
首先,要设置程序的输入参数,右键WordCount.java选择Run As->Run Configurations,如下图所示:

运行成功后,在工程上refresh,得到结果,如下图:

Linux环境可参见如下网址:
https://blog.csdn.net/u011380972/article/details/80787519
















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









