










1 引言
相信很多使用LSTM网络的初学者跟我一样,需要从刚开始不会用,再到只是会用LSTM写模型,最后基本理解LSTM的网络结构及输入输出。
2 对LSTM网络的分析
LSTM网络从概念上讲,主要包括四个门,依次为遗忘门f,输入门i,更新门g(我这里也把它看做一个门,因为这样好说明问题,其实是cell的备选值,但在文章或学术上仍然以其余三个门为准)和输出门o。如下图
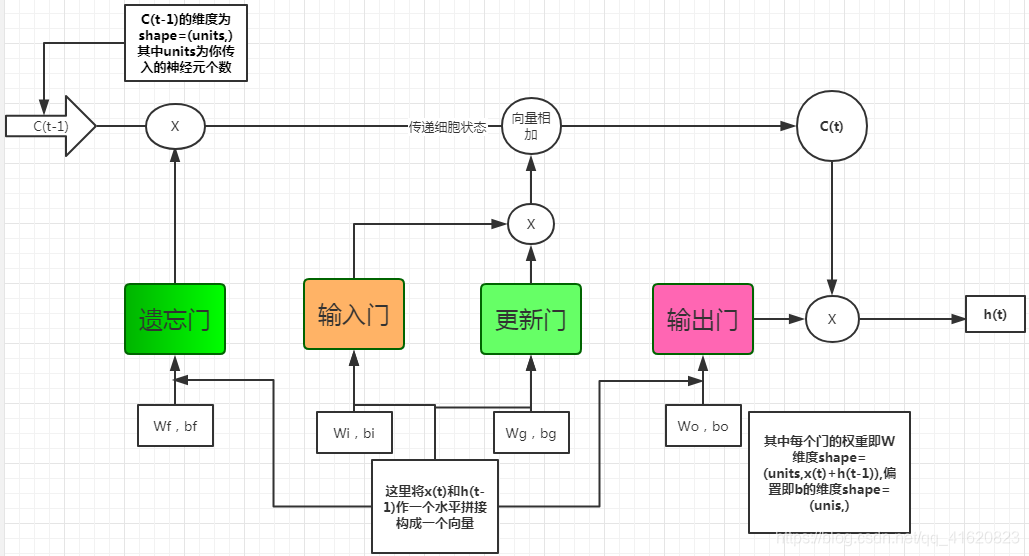
上图对于每一个门有相应的计算方式:
f=sigmoid(Wf(x(t),h(t-1))+bf)
i=sigmoid(Wi(x(t),h(t-1))+bi)
g=tanh(Wg(x(t),h(t-1))+bg)
o=sigmoid(Wo(x(t),h(t-1))+bo)
对于S(t)和h(t)有:
S(t)=f*C(t-1)+i*g
h(t)=tanh(C(t))*o
对于上面的公式可以参考源码:

3 实现细节
1.units表示什么:
所谓units就是你写代码时传入的神经元个数,即下图中的HIDDEN_SIZE。这里的神经元个数表示每一个门里面的神经元个数,即若我设HIDDEN_SIZE=128,那么上面每个门里面的神经元个数均为128,实际上每个门就是一个含128个神经元的前馈神经网络。
![]()
2.关于初始值,也就是对于第一个传入的x1不存在S和h时,可以参考源码,即设为维度为神经元个数的0向量。
![]()

4 举例说明
1.假设经过上层传入LSTM的x1=[1,2,3],那么如果为第一个则初始化h=[0,0,0,0,0](假设神经元个数为5),初始s=[0,0,0,0,0],每个门的权重W矩阵维度为(5,8),偏置b的维度为(5,);
2.执行第一步,拼接x1和h形成一个维度为(8,)的输入,这里暂且记为input;根据上面公式算每个门的值,以遗忘门为例:
f=sigmoid(np.dot(wf,input)+bf)可以得出f的维度为(5,)你会发现f的维度跟初始的C一样,所以可以进行相乘运算;那么我们易知每个门的计算值的维度均为(5,),所以你会发现一切的点乘和相加都能够正常计算;那么我们可以推出h的维度也为(5,)
综上,可以直达在LSTM网络中的S也作C的维度为(神经元个数,),h的维度也为(神经元个数,)
最后,因为本人也是初识LSTM,文中可能有不对的地方,可以多多指教,方便改正。















 2803
2803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









