






最近在复现Sketchmate的时候,RNN分支用到了LSTM和一维卷积,现在梳理一下思路。
目录
一. LSTM长短期记忆网络
LSTM网络可由下图表示:(图源:李沐:动手学深度学习9.2节)
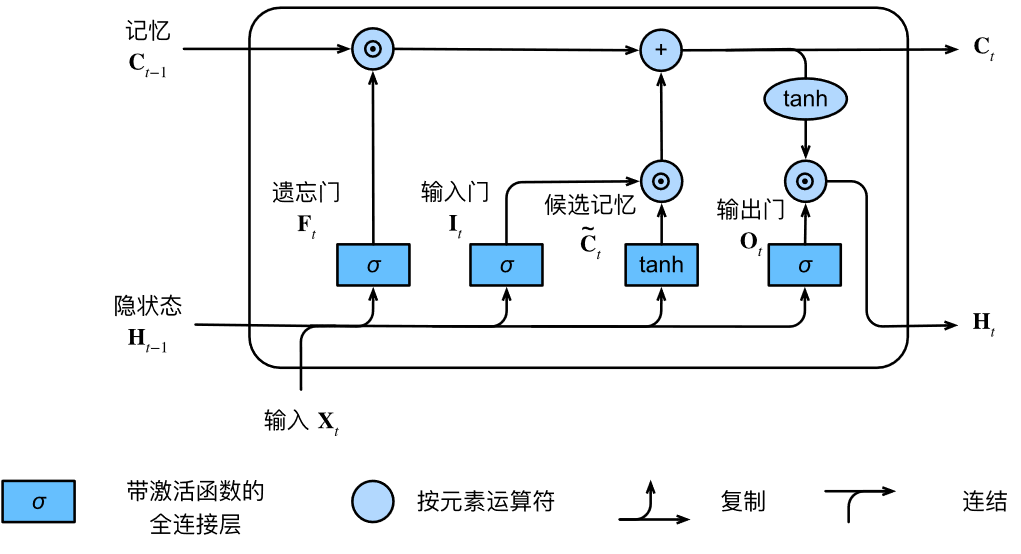
计算过程:
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
关于torch.nn.LSTM(),参数及维度变化说明如下:
(1)输入的参数列表包括:
- input_size: 输入数据的特征维数,通常就是embedding_dim(词向量的维度);
- hidden_size: LSTM中隐层的维度;
- num_layers: 循环神经网络的层数;
- bias: 用不用偏置,default=True
- batch_first: 这个要注意,通常我们输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,所以默认情况下,我们的输入数据送进LSTM之前,需要将batch_size与seq_length这两个维度调换;如果batch_first为True则不需要这个操作;
- dropout: 默认是0,代表不用dropout;
- bidirectional: 默认是false,代表不用双向LSTM;
(2)传给LSTM的数据包括input, (h_0, c_0):
- input: shape = [seq_length, batch_size, input_size]的张量;
- h_0: shape = [num_layers * num_directions, batch, hidden_size]的张量,它包含了在当前这个batch_size中每个句子的初始隐藏状态,num_layers就是LSTM的层数,如果bidirectional = True,则num_directions = 2,否则就是1,表示只有一个方向;
- c_0: 与h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态;
h_0,c_0如果不提供,那么默认是0.
(3)LSTM输出数据包括output, (h_t, c_t):
- output.shape = [seq_length, batch_size, num_directions * hidden_size],它包含的LSTM的最后一层的输出特征(h_t),t是batch_size中每个句子的长度.
- h_t.shape = [num_directions * num_layers, batch, hidden_size]
- c_t.shape = h_t.shape
h_n包含的是句子的最后一个单词的隐藏状态,c_t包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。output[-1]与h_t是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态。
注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息。
二. 一维卷积Conv1d
一维卷积,顾名思义就是在一维空间上进行卷积,通常用来处理时序的数据,卷积的过程如下图。
注意:卷积核不是一维的,一维卷积指的是卷积方向是一维的。

进行卷积的数据形状为:[batch_size,seq_len,embedding_dim];
经过卷积以后变成了:[batch_size,out_channels,sql_len-kernel_size+1]。
在卷积的时候是在最后一个维度进行的。out_channels代表输出通道数,有几个输出通道就有几个卷积核。
三. 代码验证
import torch
import torch.nn as nn
import torch.nn.functional as F
class SketchRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, dropout=0.1, n_layers=1):
super(SketchRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.conv1d_1 = nn.Conv1d(input_size, 48, 5)
self.dropout_1 = nn.Dropout(0.1)
self.conv1d_2 = nn.Conv1d(48, 64, 5)
self.dropout_2 = nn.Dropout(0.1)
self.conv1d_3 = nn.Conv1d(64, 96, 3)
self.dropout_3 = nn.Dropout(0.1)
self.lstm_1 = nn.LSTM(96, hidden_size, n_layers, dropout, batch_first=True, bidirectional=True)
self.fc_mu1 = nn.Linear(hidden_size * 186 * 2, output_size)
# self.fc_mu2 = nn.Linear(128, output_size)
def forward(self, inputs, hidden):
inputs = inputs.transpose(1, 2)
print('inputs:', inputs.shape)
output = self.conv1d_1(inputs)
print('conv1d_1:', output.shape)
output = self.dropout_1(output)
output = self.conv1d_2(output)
print('conv1d_2:', output.shape)
output = self.dropout_2(output)
output = self.conv1d_3(output)
print('conv1d_3:', output.shape)
output = self.dropout_3(output)
output = output.transpose(1, 2) # 交换维度
print('output.transpose:', output.shape)
output, (hidden, x) = self.lstm_1(output, hidden)
output = output.contiguous() # 当调用contiguous()时,会强制拷贝一份tensor,让它的布局和从头创建的一模一样,但是两个tensor完全没有联系。
output = output.view(output.size(0), -1)
output_lstm = self.fc_mu1(output)
# output = self.fc_mu2(output_lstm)
output = F.log_softmax(output_lstm, dim=1)
return output, output_lstm
model = SketchRNN(3, 256, 40, dropout=0.1)
a = torch.rand([512, 186, 96])
lstm_1 = nn.LSTM(96, hidden_size=256, num_layers=1, dropout=0.1, batch_first=True, bidirectional=True)
output, (hidden, x)=lstm_1(a, None)
print(output.shape)
print(hidden.shape)
print(x.shape)
output = output.contiguous()
print(output.shape)
output = output.view(output.size(0), -1)
print(output.shape)
fc_mu1 = nn.Linear(256 * 186 * 2, 40)
output_lstm = fc_mu1(output)
print(output_lstm.shape)
output = F.log_softmax(output_lstm, dim=1)
print(output.shape)输出:
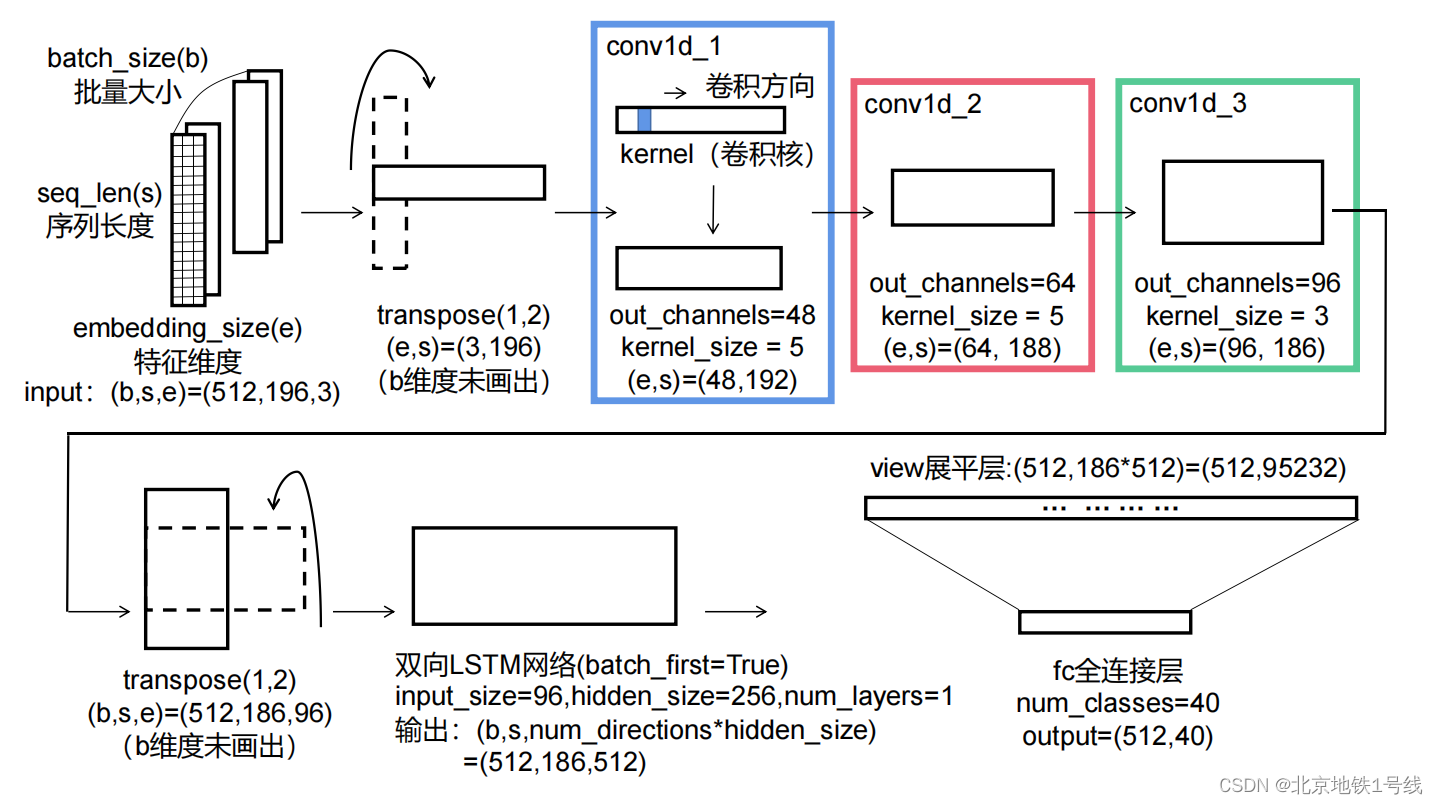
inputs: torch.Size([512, 196, 3])
inputs: torch.Size([512, 3, 196])
conv1d_1: torch.Size([512, 48, 192])
conv1d_2: torch.Size([512, 64, 188])
conv1d_3: torch.Size([512, 96, 186])
output.transpose: torch.Size([512, 186, 96])
# LSTM
output.shape:torch.Size([512, 186, 512])
hidden.shape:torch.Size([2, 512, 256])
x.shape:torch.Size([2, 512, 256])
# contiguous()深拷贝
view:torch.Size([512, 95232]) # 186*512=95232
output_lstm.shape:torch.Size([512, 40])整个维度变化图示如下:
















 5882
5882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











