







1、百度POI数据爬取
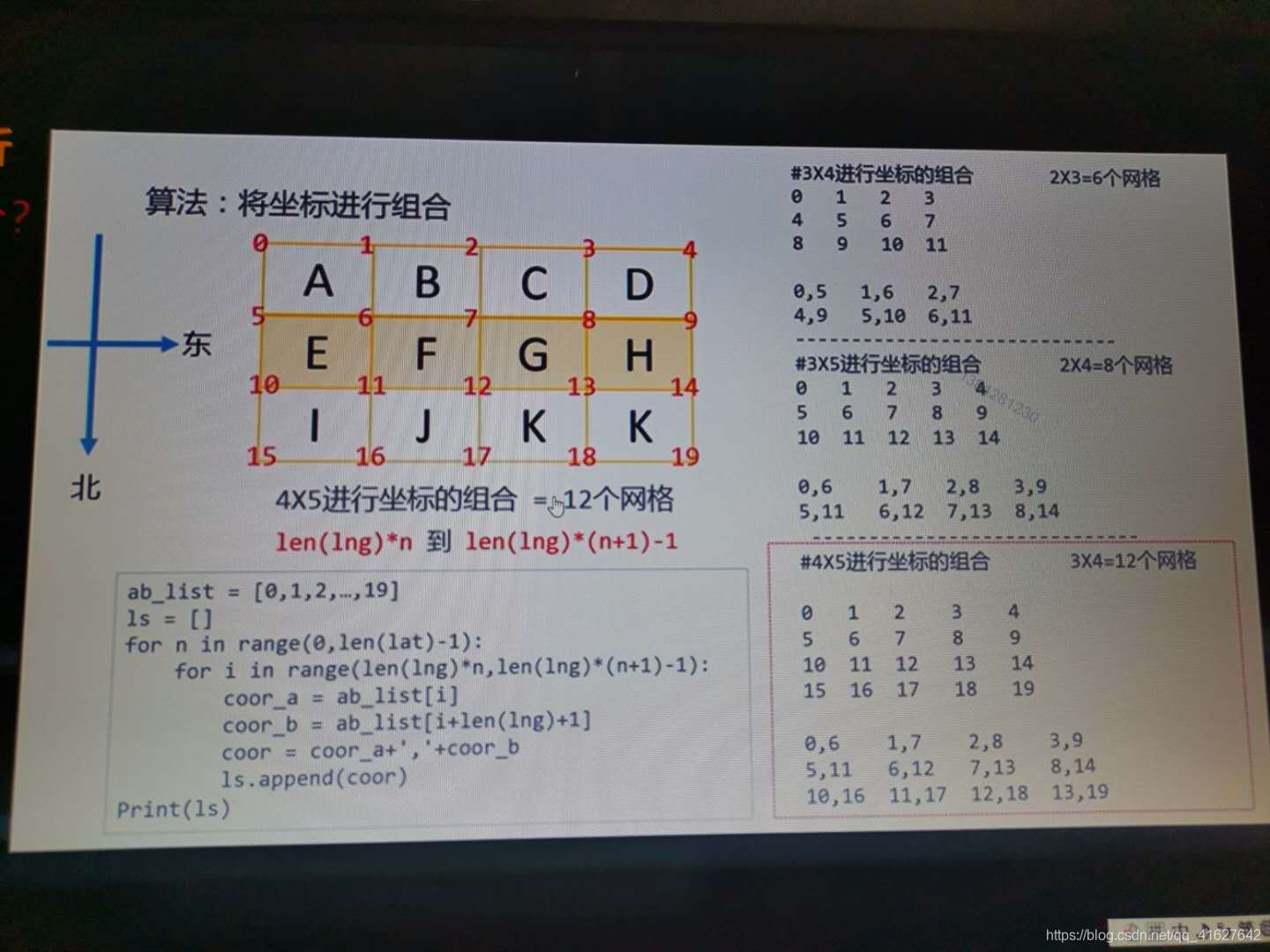
1、网格大小尺寸相关知识

2、矩形区域POI检索
class localDiv():
def __init__(self,loc,div):
self.loc=loc
self.div=div #网格划分的间隔
#1、纬度划分
def lat_div(self):
lat_sm=float(self.loc.split(',')[0])
lat_ne=float(self.loc.split(',')[2])
lat_list=[str(lat_ne)]
while lat_ne-lat_sm>0:
m=lat_ne-self.div
lat_ne=lat_ne-self.div
lat_list.append('%.2f'%m)
return sorted(lat_list)
#2 经度划分
def lng_div(self):
lng_sm=float(self.loc.split(',')[1])
lng_ne=float(self.loc.split(',')[3])
lng_list=[str(lng_ne)]
while lng_ne-lng_sm>0:
m=lng_ne-self.div
lng_ne=lng_ne-self.div
lng_list.append('%.2f'%m)
return sorted(lng_list)
#经纬度组合
def ls_com(self):
lat=self.lat_div()
lng=self.lng_div()
latlnglist=[]
for i in range(len(lat)):
a=lat[i]
for j in range(len(lng)):
b=lng[j]
ab=a+','+b
latlnglist.append(ab)
return latlnglist
def ls_REG(self):
##划分矩形网格
lat=self.lat_div()
lng=self.lng_div()
latlnglist=self.ls_com()
ls=[]
for n in range(0,len(lat)-1):
for i in range(len(lng)*n,len(lng)*(n+1)-1):
coor_a=latlnglist[i]
coor_b=latlnglist[i+len(lng)+1]
coor=coor_a+','+coor_b
ls.append(coor)
return ls
if __name__=='__main__':
loc=localDiv('39.05,114.98,39.15,115.15',0.02)
lat=loc.lat_div()
lng=loc.lat_div()
ls=loc.ls_REG()
print(ls)
3、百度POI数据下载
import pandas as pd
import numpy as np
import requests as re
import json
import time
#def get_jsondata(json_obj):
# for item in url1_json['results']:
# result={}
# result["name"]=item["name"]
# result["lat"]=item["location"]["lat"]
# result["lng"]=item["location"]["lng"]
# yield result #生成器让我们一次执行一条记录
## print(result)
class BaiduPOI(object):
def __init__(self,query,loc):
self.query=query #查询的地名
self.loc=loc#查询的经纬度
#获取数据的全部网页
def get_url(self):
urls=[]
for i in range(20): #百度最多能下载20页
url='http://api.map.baidu.com/place/v2/search?query='+self.query\
+'&bounds='+self.loc+'&page_size=20&page_num='+str(i)+'&output=json&ak=mu49L02KGmvERpLIGQHEkmI9IAuHmKCH'
urls.append(url)
return urls
#获取POI详情数据
def get_data(self):
urls=self.get_url()
for i,url in enumerate(urls):
#异常处理
try:
print(i,url)
url=re.get(url).text #网页版的内容
url_json=json.loads(url)#转换为可以识别的Json数据,数据是一个字典形式
if url_json["total"] !=0:
for item in url_json['results']:
result={}
result["name"]=item["name"]
result["lat"]=item["location"]["lat"]
result["lng"]=item["location"]["lng"]
yield result #生成器让我们一次执行一条记录
else:
print("本页及以后无数据!")
break
except:
print("error")
with open("log.txt",'a') as f:
f.write(url+'\n')
if __name__=="__main__":
poi=BaiduPOI("银行",'39.615,116.404,39.975,116.414')
data=poi.get_data()
print(pd.DataFrame(data))
4、按分块矩形区域下载数据


import pandas as pd
import numpy as np
import requests as re
import json
import time
#def get_jsondata(json_obj):
# for item in url1_json['results']:
# result={}
# result["name"]=item["name"]
# result["lat"]=item["location"]["lat"]
# result["lng"]=item["location"]["lng"]
# yield result #生成器让我们一次执行一条记录
## print(result)
class BaiduPOI(object):
def __init__(self,query,loc):
self.query=query
self.loc=loc
#获取数据的全部网页
def get_url(self):
urls=[]
for i in range(20):
url='http://api.map.baidu.com/place/v2/search?query='+self.query\
+'&bounds='+self.loc+'&page_size=20&page_num='+str(i)+'&output=json&ak=mu49L02KGmvERpLIGQHEkmI9IAuHmKCH'
# url='http://api.map.baidu.com/place/v2/search?query='+self.query\
# +'&bounds='+self.loc+'&page_size=20&page_num='+str(i)+'&output=json&ak=LQ1CU3gi0FZZBQQl8LOIOOOYK4n3g654'
urls.append(url)
return urls
#获取POI详情数据mu49L02KGmvERpLIGQHEkmI9IAuHmKCH
def get_data(self):
urls=self.get_url()
for i,url in enumerate(urls):
#异常处理
try:
print(i,url)
url=re.get(url).text #网页版的内容
url_json=json.loads(url)#转换为可以识别的Json数据,数据是一个字典形式
if url_json["total"] !=0:
for item in url_json['results']:
result={}
result["sort1"]=item["id"]
result["sort2"]=item["v"]
result["name"]=item["name"]
result["name"]=item["name"]
result["lat"]=item["location"]["lat"]
result["lng"]=item["location"]["lng"]
yield result #生成器让我们一次执行一条记录
else:
print("本页及以后无数据!")
break
except:
print("error")
with open("./log.txt",'a') as f1:
f1.write(url+'\n')
class localDiv():
def __init__(self,loc,div):
self.loc=loc
self.div=div
def lat_div(self):
lat_sm=float(self.loc.split(',')[0])
lat_ne=float(self.loc.split(',')[2])
lat_list=[str(lat_ne)]
while lat_ne-lat_sm>0:
m=lat_ne-self.div
lat_ne=lat_ne-self.div
lat_list.append('%.2f'%m)
return sorted(lat_list)
def lng_div(self):
lng_sm=float(self.loc.split(',')[1])
lng_ne=float(self.loc.split(',')[3])
lng_list=[str(lng_ne)]
while lng_ne-lng_sm>0:
m=lng_ne-self.div
lng_ne=lng_ne-self.div
lng_list.append('%.2f'%m)
return sorted(lng_list)
#经纬度组合
def ls_com(self):
lat=self.lat_div()
lng=self.lng_div()
latlnglist=[]
for i in range(len(lat)):
a=lat[i]
for j in range(len(lng)):
b=lng[j]
ab=a+','+b
latlnglist.append(ab)
return latlnglist
def ls_REG(self):
##划分矩形网格
lat=self.lat_div()
lng=self.lng_div()
latlnglist=self.ls_com()
ls=[]
for n in range(0,len(lat)-1):
for i in range(len(lng)*n,len(lng)*(n+1)-1):
coor_a=latlnglist[i]
coor_b=latlnglist[i+len(lng)+1]
coor=coor_a+','+coor_b
ls.append(coor)
return ls
if __name__=='__main__':
pois={"商业":["酒店","购物","金融"],
"公共服务":["生活服务","丽人","运动健身","留学中介机构","培训机构","汽车销售",
"汽车维修","汽车美容","汽车配件","汽车租赁","汽车检测场"],
"行政机构":["政府机构"]
}
print("......开始爬取数据.....................")
loc=localDiv('39.615,116.404,39.975,116.414',0.06)
# loc=localDiv('31.61,118.46,32.29,119.24',0.02)
loc_to_use=loc.ls_REG()
print(loc_to_use)
for id,vl in pois.items():
print("爬取",id)
file_name="Baidu_poi_{}.csv".format(id)
print(file_name)
for l in loc_to_use:
for v in vl:
poi_data=BaiduPOI(v,l)
data=poi_data.get_data()
data=pd.DataFrame(data)
print(data)
if len(data) !=0:
data.to_csv(file_name)
else:
pass
5、坐标系转换
坐标转换模块
采用博客里面的bd09_to_wgs84(lng, lat) # 百度坐标系->WGS84坐标系
6、ArcGIS数据平台数据分析
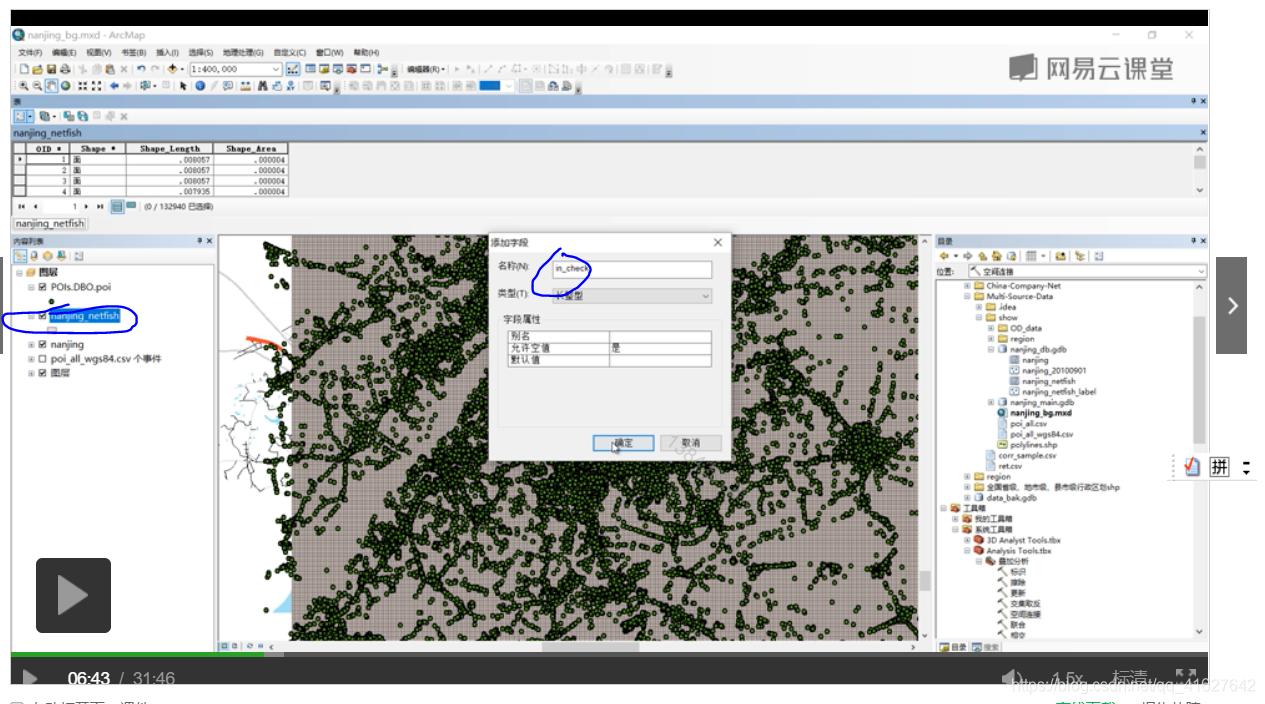
6.1创建渔网,0.002像元大小,1度是111km,添加一个字段In_Check。
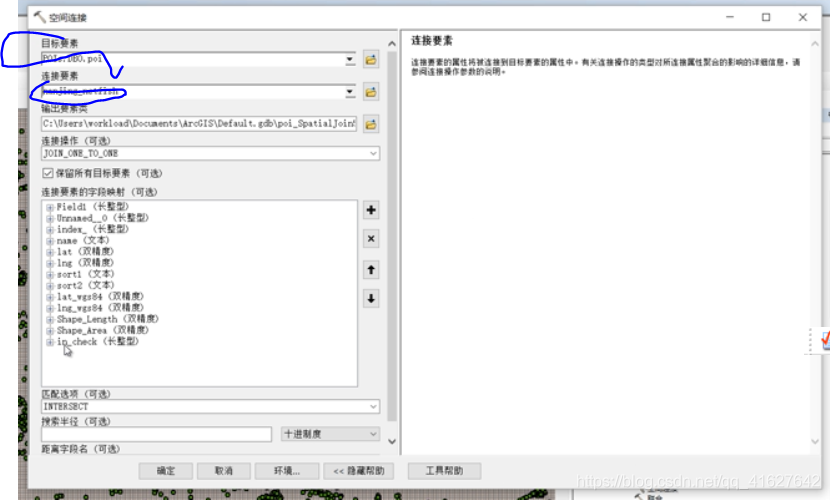
6.2 将渔网和poi进行空间连接
目标是渔网、源是POI,采用一对多。
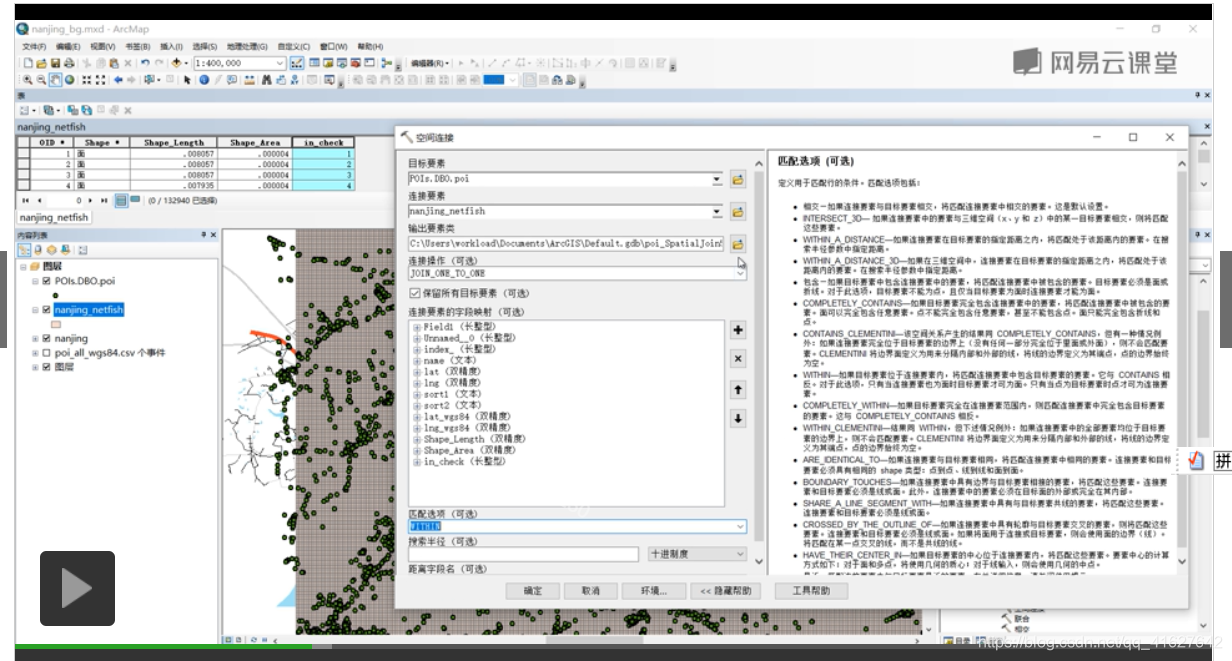
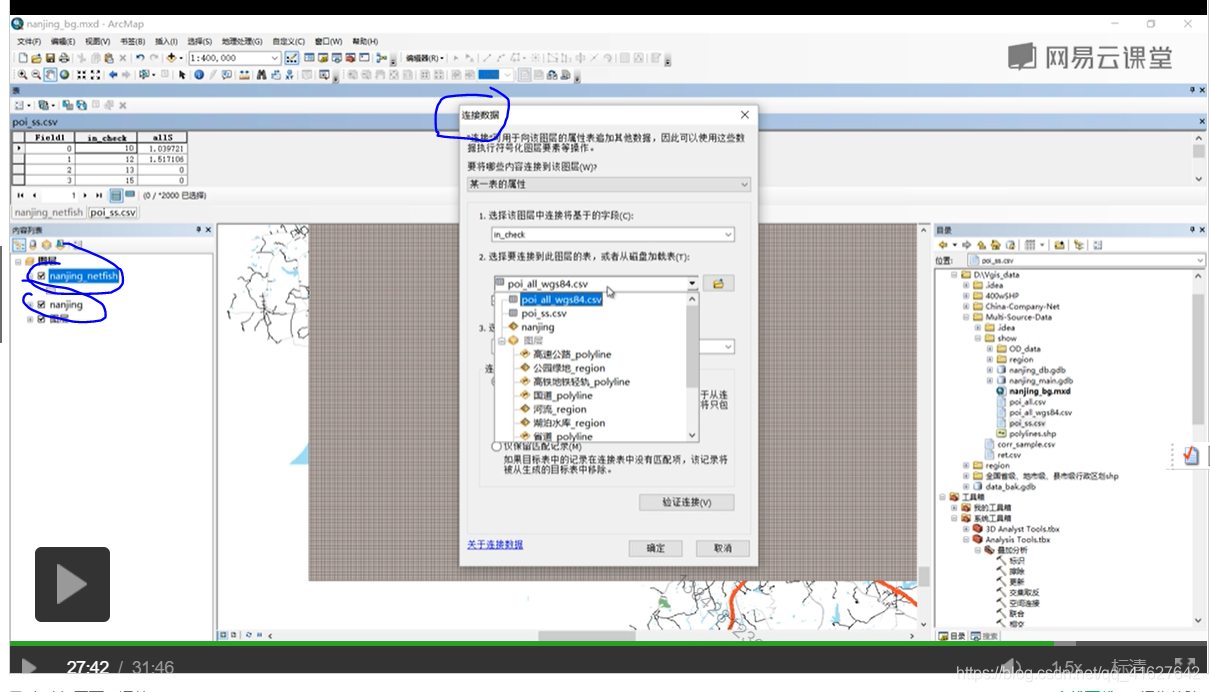
6.3 属性表连接(相同的字段)
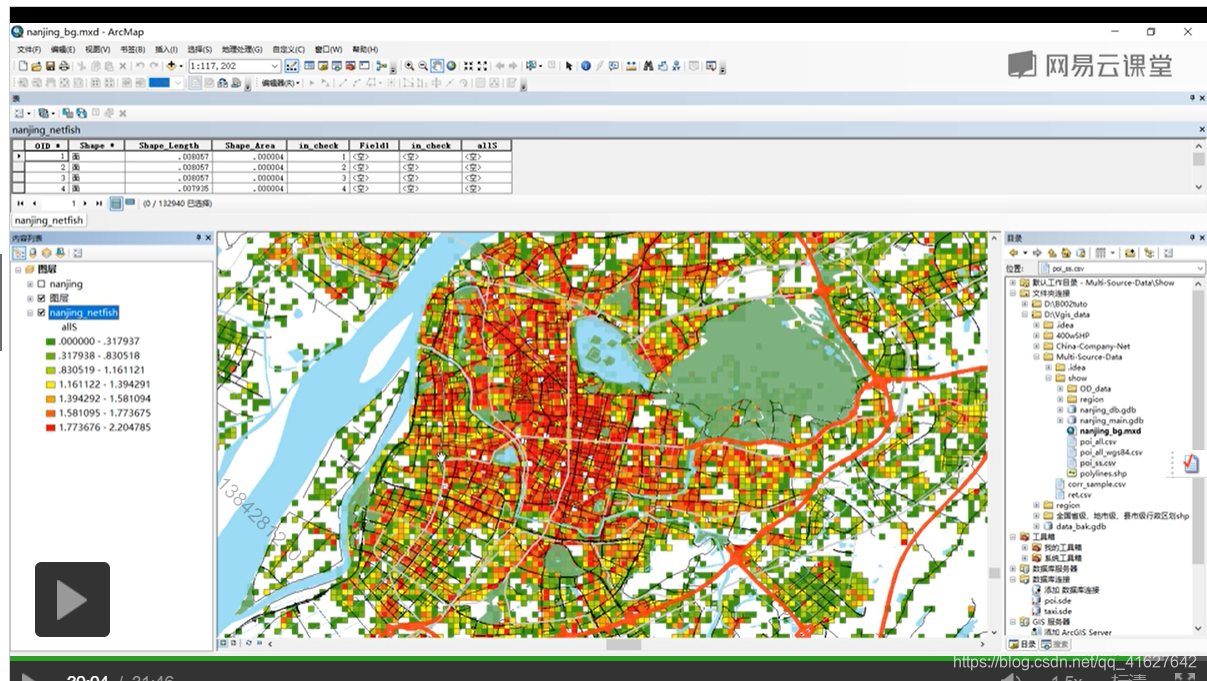
6.4 计算出来的每个渔网的熵
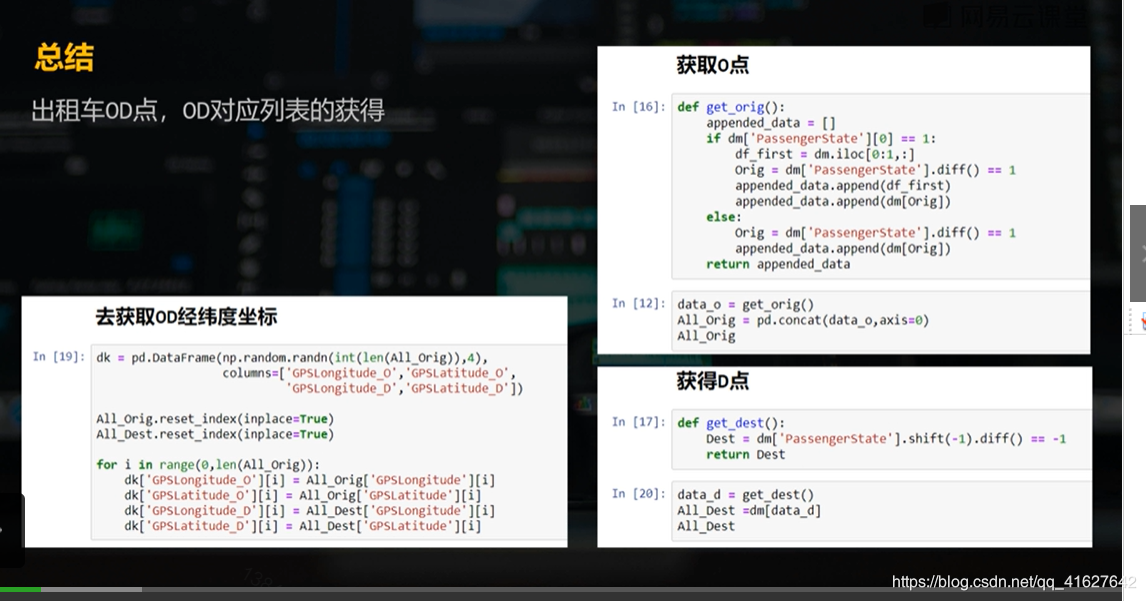
6.5 出租车司机的数据分析
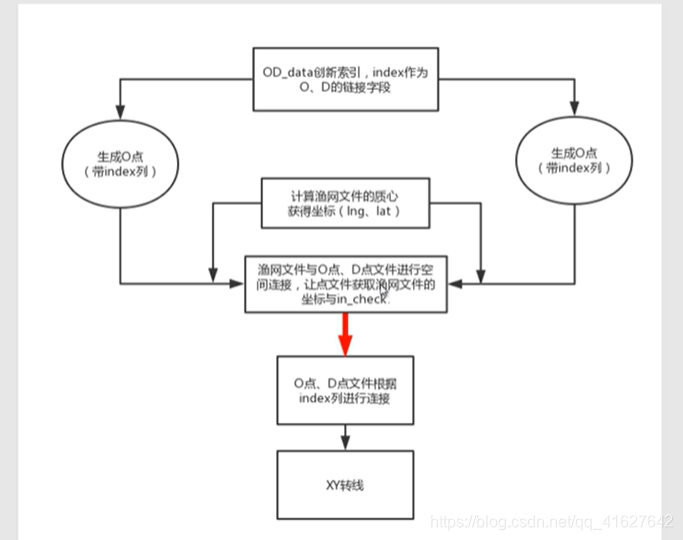
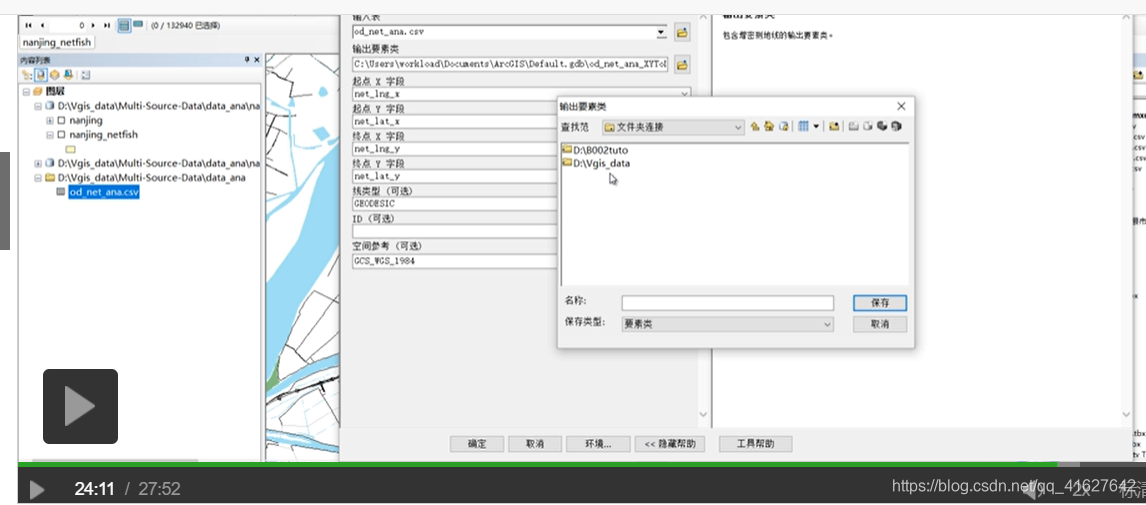
利用arcgis中的工具xy to line工具,可以轻松实现径向流量图
ArcGIS10 XY To Line工具介绍与使用
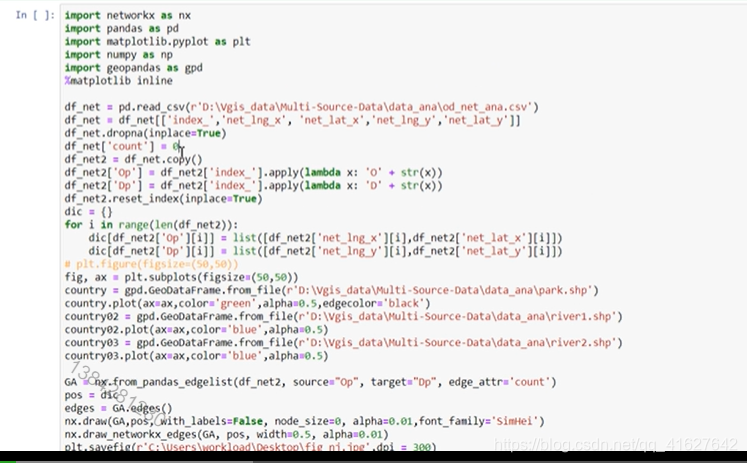
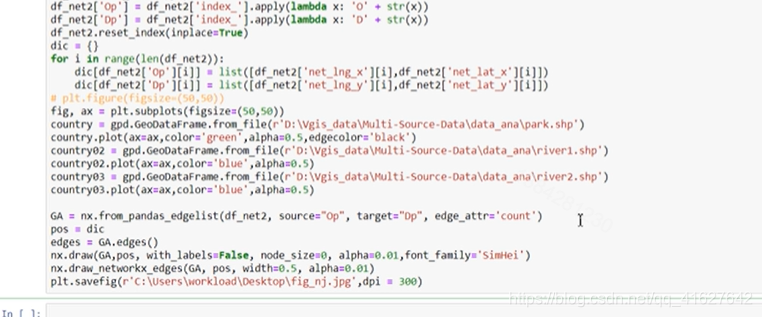


















 2465
2465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









