







摘要
分析行星规模的卫星影像和机器学习是一种梦想,但一直受到难以获取具有高度代表性高分辨率影像的成本限制。为了解决这一问题,我们在此介绍 WorldStratified 数据集。该数据集是目前最大且最为多样的公开可用数据集,采用 Airbus SPOT 6/7 卫星的最高 1.5 米/像素高分辨率影像,由欧洲航天局(ESA)Phi-Lab 提供支持,作为 ESA 资助的 QueryPlanet 项目的一部分。我们精选了近 10,000 平方公里的独特地点,确保全球各类土地利用类型的分层代表性:从农业用地到冰盖,从森林到多种城市化密度区域。我们还对机器学习数据集中通常代表性不足的地点进行了丰富标注:人道主义关注地点、非法采矿地点以及弱势人群聚居地。我们将每幅高分辨率影像与多幅来自免费获取的 Sentinel-2 10 米/像素低分辨率影像进行时间匹配。我们为该数据集提供了一个开源 Python 包,可用于:重建或扩展 WorldStrat 数据集、训练和推断基线算法,并通过丰富的教程进行学习,所有工具均兼容流行的 EO‑learn 工具箱。我们希望借此促进机器学习在卫星影像上的广泛应用,并可能使免费公共的低分辨率 Sentinel‑2 影像拥有与昂贵的私有高分辨率影像相同的分析能力。我们通过在多帧超分辨率任务上训练并发布若干高效计算的基线模型来证明这一点。许可方面,高分辨率 Airbus 影像采用 CC‑BY‑NC,标签、Sentinel‑2 影像和训练权重采用 CC‑BY,源代码和预训练模型采用 BSD,以便最大范围的使用和传播。该数据集可在 https://zenodo.org/record/6810792 获取,软件包可在 https://github.com/worldstrat/worldstrat 获取
引言
1.1 问题概述
计算机视觉与卫星影像可谓天作之合。几十年来,遥感和地球观测领域一直在探讨如何自动处理日益增长的影像数据。能够“看见”整个星球并对其进行大规模分析的吸引力,少有能及。过去三十年间,已有诸多尝试。民用可获得的影像分辨率不断提高,过去十年机器学习和计算机视觉的进步,也带来了许多有力的工具。其中一些科研成果十分瞩目,例如 Jean 等人在 2016 年的工作(Jean et al., 2016)。不少深度学习领域的创新者,早在硕士阶段就已在卫星影像上进行试验,比如 Mnih 和 Hinton 在 2010 年的研究(Mnih and Hinton, 2010)。Google Earth 等知名工具让所有人都能访问高分辨率航空影像(尽管并非全部来自卫星),激发了人们的想象。这个梦想根深蒂固。
然而,要真正发挥这两大领域的全部潜力,却受到多重因素的制约,尤其是数据获取难度及其成本。
对于黑客而言,让最前沿技术更易获取是一种乐趣:某些卫星影像实际上任何架设了天线的业余爱好者都能接收——第一作者在本科时就搭建过一套廉价接收、存储和处理低分辨率 Meteosat 第二代影像的系统(Beaudoin et al., 2005),成本仅为当时商用系统的十分之一。有趣而刺激。但对于高精度数字影像,这类“劫持”式接收站已不可行。自 2015 年以来,欧洲“哨兵—2”号卫星每五天提供一次全球范围内 10 米/像素的中分辨率免费影像,任何掌握访问方法的人均可获取。
然而,1 米/像素的高分辨率或亚米级的超高分辨率影像,仍然难以触及。在与国际特赦组织合作、检测冲突区被毁村庄的研究中(Cornebise et al., 2018),我们发现,即便给慈善组织提供慷慨折扣,采购相当于 Google Earth 最大缩放级别的整个达尔富尔地区的单一超高分辨率影像拼接,也要耗资 400 万美元。这使得进行高分辨率计算机视觉实验本身就是极大挑战。
即便撇开成本不谈,假设(正如一些人所期望的)发射技术的飞速发展能以更低价位带来海量高分辨率影像,机器学习真正需要的核心素材——用于训练的精心策划数据集——依然严重不足。即使是 Sentinel‑2 影像,访问也需掌握一定领域知识,而天然图像几乎可随处获取,门槛截然不同。开放的高分辨率卫星影像数据集仍十分稀缺,现有少数数据集往往规模小、覆盖区域有限、选址随意,或仅针对特定应用。SpaceNet 挑战数据集(Van Etten et al., 2018)或许是最广为使用的卫星影像数据集,其覆盖总面积略超 10,000 平方公里,与 WorldStrat 规模相当,但主要聚焦城市结构与建筑/道路检测等特定任务,数据供应商和分辨率各异,且无配对的多时相低分辨率影像。
我们特别提及“配对低分辨率”影像,因为另一种应对影像获取受限的思路是超分辨率:期望从多次免费低分辨率卫星重访影像中,重建出相当于一次高分辨率卫星拍摄的洞见。我们希望构建可用于广泛应用的数据集,而使其适用于超分辨率任务,则能带来更多附加价值。
在这方面,ESA Kelvin’s PROBA-V 数据集(Märtens et al., 2019)及其竞赛推动了多帧超分辨率研究,但其仅提供单波段且分辨率极低(300 米/像素和 100 米/像素),且不具备地理参考或时间参考。然而,它促成了我们高性能 HighRes‑Net 多帧超分辨率算法的研发(Deudon et al., 2020)。尽管自然图像和视频领域已有大量多帧超分辨率文献,卫星影像方向的研究相对较少——我们将在第 4.1 节详述。
Michel 等人于 2022 年发布的新数据集支持单幅图像超分辨率,但仅覆盖 29 个地点、806 平方公里,分辨率 5 米/像素。每个地点提供 9 次重访,并为每次重访配对一幅低分辨率与一幅高分辨率影像。这虽颇具潜力,但仍不够广泛。
据我们所知,尚无任何数据集试图通用性覆盖全球各类土地利用;更少有数据集专为将学习迁移至高可得的低分辨率数据而设计。Sentinel‑2 低分辨率影像虽可手动添加,但代价是额外的工作与专业知识。
1.2 我们的贡献
我们旨在推动面向卫星影像的机器学习在广泛应用场景中的发展:从生态与气候监测,到城市化研究,到社会学,到灾害预警,再到农业等。为此,在构建此数据集及其基准测试与软件包时,我们的重点是:
最大化所有潜在感兴趣特征的覆盖,以支持最广泛的用例。
实现全球范围内的合理代表性——特别是在机器学习公平性、责任性与透明性(日益关注数据集对全球西方的偏倚)背景下尤为重要。
提供一条可让他人轻松复现并在追加预算时可扩展的流程。
最终,我们的“World Stratified 数据集”(简称 WorldStrat)(Cornebise et al.)覆盖 10,000 平方公里、4,000 个精心挑选的地点,以实现最高的多样性。如图 2 所示,我们将影像采集预算分为三部分:
城镇聚居区——按人口密度进一步分层:首先基于 ESA CCI LandCover 产品(ESA, 2017)过滤出全球聚居区(该产品依据 CCI 数据政策 v1.1 无限制授权),再依据全球人类聚居层 SMOD 产品(Florczyk et al., 2019)的城市密度等级(CC-BY 授权)进行子分层。
非聚居区——对 ESA CCI LandCover 产品的土地覆盖分类系统标签(及其按 IPCC 类别汇总)进行分层抽样与类别重平衡。
常规数据集通常欠缺的用例——我们从以下来源获取兴趣点:联合国难民署(UNHCR)(CC-BY-IGO 授权)的人群关注点,国际特赦组织的人权关注地点(获授权),以及 ESA ASMSpotter 的非法采矿点(获授权)。
在每个地点,除标签外,我们提供:
一幅 Airbus SPOT 6/7 的高分辨率多光谱影像(基于 ESA TPM 付费扩展许可,可在 CC-BY-NC 下再分发),包括 RGB 波段(6 m/像素)、近红外波段(6 m/像素)和全色波段(1.5 m/像素),图像尺寸 1054×1054 像素。
16 幅 Copernicus Sentinel‑2 的低分辨率重访影像(根据 Copernicus Sentinel 数据法律声明和服务信息无阻碍授权),与高分辨率影像在时间上匹配——最接近的在前后 5 天内。覆盖全部 12 个光谱波段,分辨率最高可达 10 m/像素。
文章其余部分组织如下:
第 2 节介绍我们如何策划全球各“感兴趣区”(AOI),以实现对世界和多种用例的最大代表性。
第 3 节描述了每个 AOI 上可用的低/高分辨率配对影像的特征,以及如何轻松扩展。
第 4.1 节以多帧超分辨率任务为例,利用多种架构给出基线并强调计算效率;同时介绍与流行 EO‑learn 工具包集成的代码库,便于使用、复现与扩展。
第 5 节总结了沿途尝试与弃用的想法,并讨论了未来可能的扩展方向。
2 策划高度代表性区域
JIF 数据集覆盖近 10,000 平方公里。每个基础感兴趣区(AOI)面积为 2.5 平方公里,即边长 1,581 米,这是高分辨率影像提供商 Airbus 允许的最小连续订购面积,从而在预算范围内最大化 AOI 数量。
2.1 世界分层抽样
我们使用数据集的前半部分来尝试对世界进行系统的分层覆盖。问题在于:如何在与应用无关的前提下,为超分辨率任务选出“最佳”位置?
60% 的样本取自 ESA CCI LandCover 产品中的“聚居区”类别,然后根据全球人类聚居层 SMOD 产品的城市密度类型进行子分层,边缘分布与真实分布的立方根成比例——保持类别顺序但减小整体不平衡。
40% 的样本取自所有其他 IPCC 类别(即非聚居区),先按(非聚居区)IPCC 类别分层,边缘分布与真实分布立方根成比例;然后在每个(非聚居区)IPCC 类别内,再根据 LCCS 细植被类型进行分层,依然采用立方根比例。
2.2 为什么按土地利用分层
在完全针对超分辨率优化的抽样中,我们或许会首先对卫星影像进行潜在空间特征聚类(如 Jean et al., 2019),再参考经典的方差最小化实验设计(Atkinson et al., 2007),按语义聚类中超分辨率难度进行抽样。但这要么依赖于具体算法,要么需要先解决超分辨率问题,均不令人满意;且仅为超分辨率优化,而我们目标更广。
统计实验设计中常用的代理方法是按特征方差对每个语义类进行抽样,但视觉特征的“方差”并无明确定义,研究“语义方差”本身就是一个深刻而超出本项目范围的方法学课题。
更务实的做法是确保每种土地类型都被代表,从而同等支持城市研究、冰盖监测、湖泊学研究等。
直接在 WGS84 椭球体上对陆地区域 POI 做均匀采样(如拒绝采样),再过滤 SPOT 可用性,会使各土地利用类型及其比例无法得到精细控制;大数定律虽能保证渐近按真实世界比例呈现,但当样本数“远未达到渐近”时,随机波动难以控 制,且无法保证稀有类别的代表性。
因此,我们利用现有的土地利用/覆盖分类先验,将其作为分层依据。
ESA 气候变化倡议土地覆盖产品(ESA CCI LCP)(ESA, 2017)基于联合国粮农组织(FAO)土地覆盖分类系统(LCCS)分级体系(Di Gregorio, 2005),并在更粗粒度上采用 IPCC 建议的分类(ESA, 2017[第30页]),契合气候研究需求。
2.2.1 非城市区域采样
我们在非聚居区域采样 2,000 平方公里,选取 800 个 POI,并使用 ESA CCI 2019 数据集中的 IPCC 分类进行分层,再用立方根重要性采样重平衡类别,例如有意降低地衣/苔藓覆盖地的过高比例。采样点中额外加入冰盖区域,因原始分类中明显缺失冰盖,但冰盖对气候分析、地缘政治及新航路具有核心意义。
采用立方根重要性采样的理由在于:
我们希望提高稀有类别的代表性,避免超分辨率模型忽视这些“罕见”对象;
同时不希望完全均匀采样,而应承认自然界中高比例出现的类别也需一定代表性。
立方根在提升稀有类别的同时,保持了类别间的单调顺序。结果如图 3 所示
3 影像数据
3.1 高分辨率:单次 SPOT 6/7 影像
每个 AOI 有一次 SPOT 6/7 高分辨率影像采集,覆盖五个波段。全色(Pan)波段分辨率为 1.5 m/像素,对应每个 2.5 km² AOI 得到一幅 1,054×1,054 像素的图像。红、绿、蓝和近红外波段分辨率均为 6 m/像素。采集日期在 2017–2019 年间随机选自云量低于 5% 的场次。由于 AOI 远小于整个 SPOT 影像场,实际 AOI 区域内云量往往更低,甚至可能无云,为超分辨率重建提供了理想目标。影像示例见图 1。

3.2 低分辨率:多次 Sentinel‑2 重访
针对每次高分辨率 SPOT 采集,我们获取 16 次 Sentinel‑2 重访,重访日期以 SPOT 采集日为中心。若需超过 16 次重访,可通过 SentinelHub 获取。重访间平均间隔约 5 天。每次重访均提供全部 12 个光谱波段,分辨率从 RGB 的 10 m/像素到其他波段的 60 m/像素不等。
我们刻意不按云量过滤 Sentinel‑2 重访影像,旨在使低分辨率训练分布贴近真实场景——用户往往希望在某地某时重建影像,算法需学习忽略云区,仅从无云部分重建视图。
3.3 时序匹配:对齐 AOI、高分与低分影像
与 Sentinel‑2 全天候定期观测不同,SPOT 仅在受任务指派的时间和地点采集。由此产生两个问题:
我们采样的 POI 在何时何地可获得 SPOT 高分影像?
对于每次 SPOT 采集,在该日期前后多大时间窗口内可获得 Sentinel‑2 重访?
图 4 展示了 22 个国际特赦组织 POI(按纬度排序)中,每个 POI 的 SPOT 采集日(X 轴 0 点)前后最多 ±6 个月窗口内,不同时间窗长度(彩色曲线)下可获得 Sentinel‑2 重访次数(Y 轴)。可见,不同 POI/时间窗组合下,Sentinel‑2 可用次数存在差异,有的曲线明显更高。
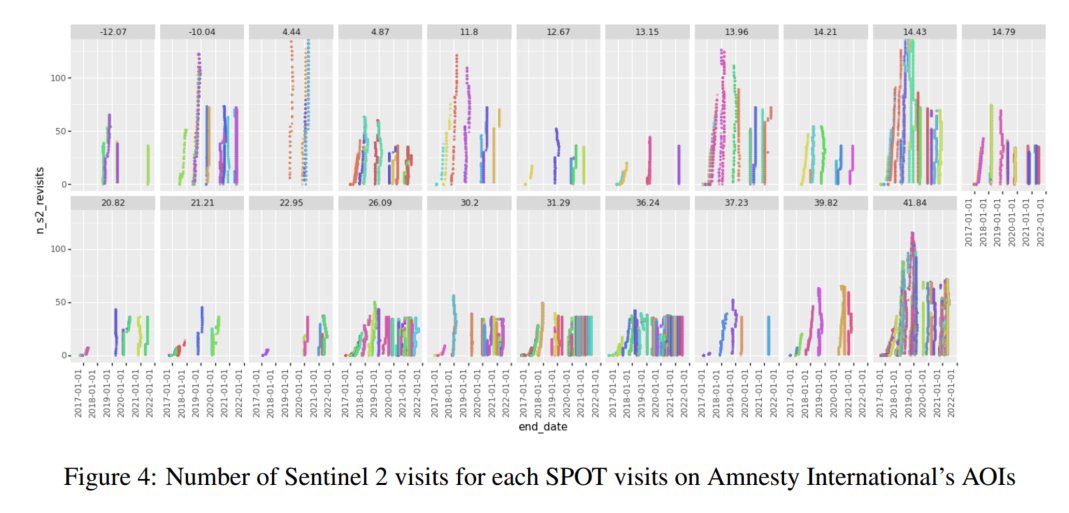
理论上可据此为每个 POI 优选 SPOT 采集时间,以最大化同一时间窗内的 Sentinel‑2 重访数量,丰富训练样本。但这会引入难以解读的隐性偏差。我们还观察到,在同一 POI 内,不同 SPOT 重访间的 Sentinel‑2 可用性差异虽存在,但较为合理——多次 SPOT 重访通常提供相似的 S2 重访量。
若按 Sentinel‑2 可用性偏置采样,则等同于按云量偏置,这并不公平地反映真实用例,会将模型训练导向错误目标。
因此,我们再次决定迎接比“最优策划”更艰难的挑战,以更贴近现实:在同一 POI 内,均匀随机选择一 个 SPOT 采集作为参考。
当然,仍有一处偏差:那些从未被 SPOT 客户指派过的 POI 将无高分辨率影像。虽有遗憾,但除非改用其他高分影像源,否则无法规避。我们对两点因素抱有信心,可部分缓解此偏差:
SPOT 影像宽幅覆盖的不仅仅是单个 AOI,因此涵盖的区域可能比单一点更具多样性。
SPOT 任务指向的 POI 本身对客户具有足够吸引力,虽与我们开源包的用户兴趣不尽相同,但这些显著特征具有可迁移性。因此,这种隐性采样反而有助于确保影像富含有价值的场景和特征。
应用示例:基线模型、基准测试与源代码
4.1 超分辨率基准测试
我们在超分辨率任务上演示该数据集的应用。尽管多帧超分辨率领域近期已有显著进展(参见 Salvetti et al. (2020);Valsesia 和 Magli (2022);Bhat et al. (2021);Molini et al. (2020)),但本工作并非穷尽式基准评测,仅侧重三种架构:
单幅图像超分辨率架构 SRCNN (Dong et al., 2015);我们将多次重访影像按通道拼接后,对 SRCNN 的多帧扩展;
针对多光谱数据改造的 HighResNet (Deudon et al., 2020),类似于 Razzak et al. (2021) 的多波段处理方式。我们通过将原架构中的可学习 ShiftNet 替换为简单的缓存对齐搜索,加速了该模型。
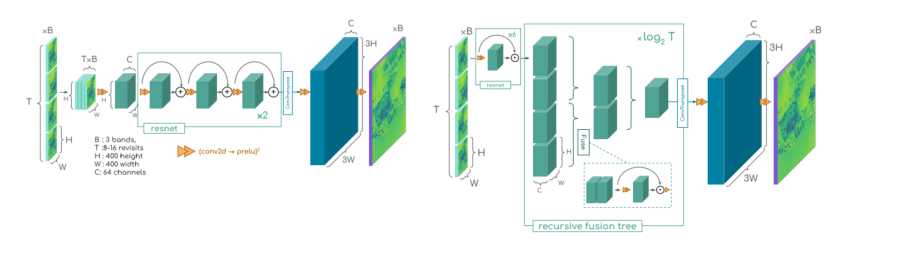
图 5 展示了(多帧)SRCNN 与 HighResNet 两大核心架构的结构示意图。
4.2 工具箱与 EO‑Learn 插件
除了数据集,我们还开源了一个易用的 Python 包,集成到流行的 EO‑Learn 管道中,并提供丰富的教程笔记本。该包覆盖数据收集、所有基线模型的训练与推断,统一采用 PyTorch Lightning 接口,并支持按需采样新训练数据。我们特别关注高效训练:借助快速缓存机制,实现单块 V100 GPU 上 30 分钟内完成 HighResNet 训练,GPU 利用率平均达 95%。
5 讨论
潜在社会影响:计算机视觉与遥感的社会影响可著书立说。就本工作而言,唯一敏感数据为 UNHCR 关注点,但这些数据已由 UNHCR 自行公开。
已知局限与未来工作:尽管我们希望训练模型能支持广泛应用,但 Sentinel‑2 重访频率(每 5 天一次)限制了我们只能处理变化较慢的结构,如建筑或土地占用,无法覆盖作物等高时变场景。
我们尚未在数据集中加入河流/港口及沿海边缘区域,可通过水道地图选点来补充。
分层策略可进一步细化。例如,我们曾考虑但最终放弃使用世界城市数据库(Stewart 和 Oke, 2012)中的本地气候区(LCZ)进行分层。LCZ 可识别局部建筑类型,覆盖欧洲、美洲及部分贡献区(Demuzere et al., 2021),但其贡献区覆盖率不及全球人类聚居层(GHSL)。
UNHCR 关注点数据并非极为精确:其 POI 更可能位于实际聚居地“附近”。我们通过覆盖 2.5 km² 区域来缓解此问题,并考虑到临时聚居地与周边聚居地往往相似,从而保证代表性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









