






1、决策树概念
官方严谨解释:决策树经典的机器学习算法,是基于树的结构来进行决策的。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
我的理解:就是不断的做“决策”,做出的许多决策形成多个分支,最后变成一个树的形状。如图所示是一个判断用户是否喜欢某电影的决策过程。
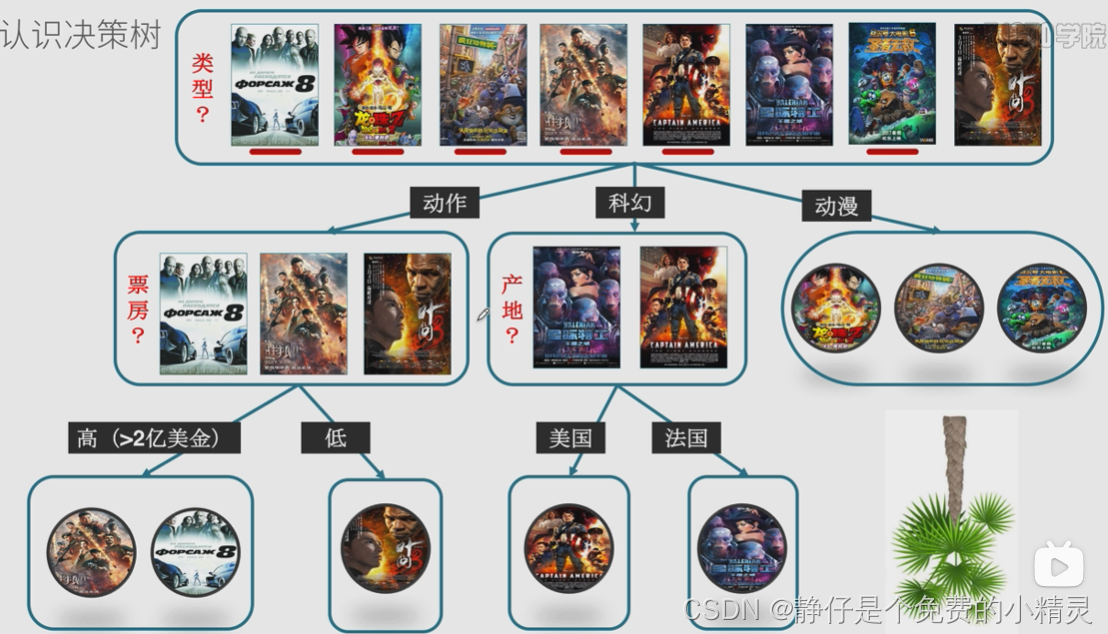
2、熵
信息熵:指系统混乱的程度,信息熵越小,不确定性越小,决策树的分类结点的纯度越高,决策树的分支结点所包含的样本越可能属于同一类别,分类效果越好。
假设当前样本集合
D
D
D中第
k
k
k类样本所占的比例为
p
i
(
i
=
1
,
2
,
.
.
.
,
n
)
p_i(i=1,2,...,n)
pi(i=1,2,...,n),信息熵的定义如下:
H
(
D
)
=
−
∑
i
=
1
n
p
i
log
2
p
i
.
H(D)=-\sum\limits_{i=1}^{n}p_i\log_2p_i.
H(D)=−i=1∑npilog2pi.
结点的“纯度”:决策树的关键是如何选择最优划分属性,一般而言,随着划分过程的不断进行,我们希望决策树的分支节点所包含的样本尽可能尽可能属于同一类别,即结点的“纯度”越来越高。
条件熵:在
X
X
X给定条件下,随机变量
Y
Y
Y的不确定性:
H
(
Y
∣
X
)
=
∑
i
=
1
n
p
i
H
(
Y
∣
X
=
x
i
)
H(Y|X)=\sum\limits_{i=1}^{n}p_iH(Y|X=x_i)
H(Y∣X)=i=1∑npiH(Y∣X=xi)
信息增益:信息增益越大说明利用特征
A
A
A来进行划分所获得的纯度越大
g
(
D
∣
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D|A)=H(D)-H(D|A)
g(D∣A)=H(D)−H(D∣A)
举个例子:
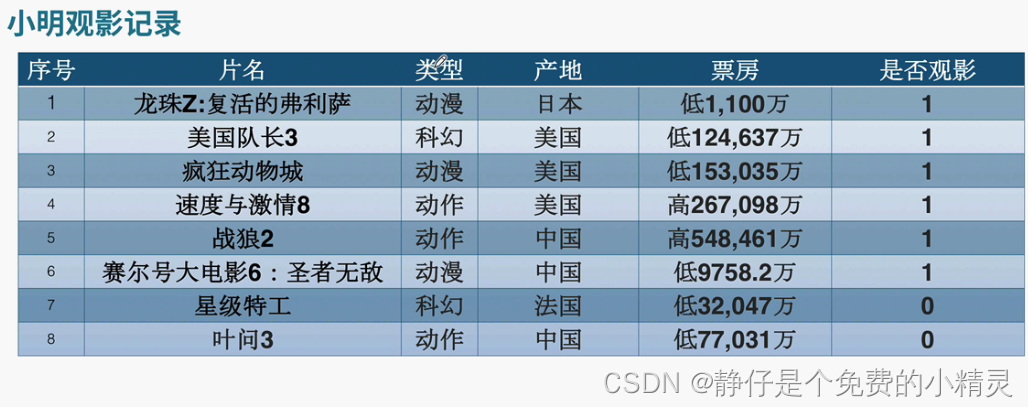

解释说明:
- 算式中出现的 0 1 ∗ ln 0 1 = 0 \frac{0}{1}*\ln\frac{0}{1}=0 10∗ln10=0,乘数是0,而被除数只是趋近于-∞
- 类型的信息增益为 H ( x ) − H 类 型 ( x ) H(x)-H_{类型}(x) H(x)−H类型(x)
- 计算得出产地的信息增益最大,因此将产地作为决策树优先选择的划分依据
决策树代码如下:
#决策树分类
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # 导入DecisionTreeClassifier函数
from sklearn.model_selection import train_test_split
from sklearn import metrics # 分类结果评价函数
data = pd.read_csv('./wm.csv', index_col=False, encoding='gb18030')
print(data)
'''
y x1 x2 x3
0 1 0.697 0.460 0
1 1 0.774 0.376 0
2 1 0.634 0.264 0
3 1 0.608 0.318 0
4 1 0.556 0.215 0
5 1 0.403 0.237 1
6 1 0.481 0.149 1
7 1 0.437 0.211 1
8 0 0.666 0.091 1
9 0 0.243 0.267 2
10 0 0.245 0.057 2
11 0 0.343 0.099 2
12 0 0.639 0.161 0
13 0 0.657 0.198 0
14 0 0.360 0.370 1
15 0 0.593 0.042 2
16 0 0.719 0.103 1
'''
x = data[['x1', 'x2', 'x3']] # 特征
y = data['y'] # 标签
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0, train_size=0.8)
print('训练集和测试集 shape', x_train.shape, y_train.shape, x_test.shape, y_test.shape)
model = DecisionTreeClassifier(criterion="entropy") # 实例化模型DecisionTreeClassifier()
model.fit(x_train, y_train) # 在训练集上训练模型
print(model) # 输出模型
# 在测试集上测试模型
expected = y_test # 测试样本的期望输出
predicted = model.predict(x_test) # 测试样本预测
# 输出结果
print(metrics.classification_report(expected, predicted)) # 输出结果,精确度、召回率、f-1分数
print(metrics.confusion_matrix(expected, predicted)) # 混淆矩阵
auc = metrics.roc_auc_score(y_test, predicted)
accuracy = metrics.accuracy_score(y_test, predicted) # 求精度
print("Accuracy: %.2f%%" % (accuracy * 100.0))















 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









