






学习来源:日撸 Java 三百行(61-70天,决策树与集成学习)
- 决策是人类天天干的事情,如中午吃啥,股票买啥。
- 决策树是为决策构建的树,决策树的核心是确定当前数据使用哪个属性来分割。不同的算法可能使用不同的属性。
- 条件熵计算公式:
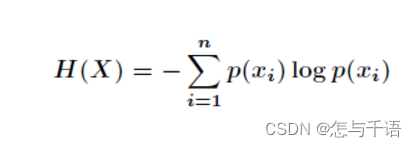
数据集:
@relation weather
@attribute Outlook {Sunny, Overcast, Rain}
@attribute Temperature {Hot, Mild, Cool}
@attribute Humidity {High, Normal, Low}
@attribute Windy {FALSE, TRUE}
@attribute Play {N, P}
@data
Sunny,Hot,High,FALSE,N
Sunny,Hot,High,TRUE,N
Overcast,Hot,High,FALSE,P
Rain,Mild,High,FALSE,P
Rain,Cool,Normal,FALSE,P
Rain,Cool,Normal,TRUE,N
Overcast,Cool,Normal,TRUE,P
Sunny,Mild,High,FALSE,N
Sunny,Cool,Normal,FALSE,P
Rain,Mild,Normal,FALSE,P
Sunny,Mild,Normal,TRUE,P
Overcast,Mild,High,TRUE,P
Overcast,Hot,Normal,FALSE,P
Rain,Mild,High,TRUE,N
代码:
package machinelearning.decisiontree;
import weka.core.Instance;
import weka.core.Instances;
import java.io.FileReader;
import java.util.Arrays;
public class ID3 {
/**
* The data.
*/
Instances dataset;
/**
* Is this dataset pure (only one label)?
*/
boolean pure;
/**
* The number of classes. For binary classification it is 2.
*/
int numClasses;
/**
* Available instances. Other instances don't belong this branch.
*/
int[] availableInstances;
/**
* Available attributes. Other attributes have been selected in the path
* from the root
*/
int[] availableAttributes;
/**
* The selected attribute
*/
int splitAttribute;
/**
* The children nodes.
*/
ID3[] children;
/**
* My label. Inner nodes also have a label. For example, <outlook = sunny,
* humidity = high> never appear in the training data, but <humidity = high>
* is valid in other cases.
*/
int label;
/**
* The prediction,including queried and predicted labels.
*
*/
int[] predicts;
/**
* Small block cannot be split further.
*/
static int smallBlockThreshold = 3;
public ID3(String paraFilename) {
dataset = null;
try {
FileReader fileReader = new FileReader(paraFilename);
dataset = new Instances(fileReader);
fileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraFilename + "\r\n" + ee);
System.exit(0);
}// of try
dataset.setClassIndex(dataset.numAttributes() - 1);
numClasses = dataset.classAttribute().numValues();
availableInstances = new int[dataset.numInstances()];
for (int i = 0; i < availableInstances.length; i++) {
availableInstances[i] = i;
}// of for i
availableAttributes = new int[dataset.numAttributes() - 1];
for (int i = 0; i < availableAttributes.length; i++) {
availableAttributes[i] = i;
}// of for i
//Initialize.
children = null;
//Determine the label by simple voting.
label = getMajorityClass(availableInstances);
// Determine whether or not it is pure.
pure = pureJudge(availableInstances);
}// of the first constructor
public ID3(Instances paraDataset,int[] paraAvailableInstances, int[] paraAvailableAttributes) {
//Copy its reference instead of clone the availableInstances.
dataset = paraDataset;
availableInstances = paraAvailableInstances;
availableAttributes = paraAvailableAttributes;
// Initialize.
children = null;
// Determine the label by simple voting.
label = getMajorityClass(availableInstances);
// Determine whether or not it is pure.
pure = pureJudge(availableInstances);
}
/**
* Compute the majority class of the given block for voting.
* @param paraBlock the block
* @return The majority class
*/
private int getMajorityClass(int[] paraBlock) {
int[] tempClassCounts = new int[dataset.numClasses()];
for (int i = 0; i < paraBlock.length; i++) {
tempClassCounts[(int)dataset.instance(paraBlock[i]).classValue()]++;
}
int resultMajorityClass = -1;
int tempMaxCount = -1;
for (int i = 0; i < tempClassCounts.length; i++) {
if (tempMaxCount < tempClassCounts[i]) {
tempMaxCount = tempClassCounts[i];
resultMajorityClass = i;
}// of if
}// of for i
return resultMajorityClass;
}// of getMajorityClass
/**
* Is the given block pure?
* @param paraBlock the block.
* @return True if pure.
*/
private boolean pureJudge(int[] paraBlock) {
pure = true;
for (int i = 0; i < paraBlock.length; i++) {
if (dataset.instance(paraBlock[i]).classValue() != dataset.instance(paraBlock[0]).classValue()) {
pure = false;
break;
}// of if
}// of for i
return pure;
}// of pureJudge
/**
* Select the best attribute
* @return The best attribute index.
*/
public int selectBestAttribute() {
splitAttribute = -1;
double tempMinimalEntropy = 10000;
double tempEntropy;
for (int i = 0; i < availableAttributes.length; i++) {
tempEntropy = conditionalEntropy(availableAttributes[i]);
if (tempMinimalEntropy > tempEntropy) {
tempMinimalEntropy = tempEntropy;
splitAttribute = availableAttributes[i];
}// of if
}// of for i
return splitAttribute;
}//of selectBestAttribute
/**
* Compute the conditional entropy of an attribute.
* @param paraAttribute the given attribute.
* @return The entropy
*/
private double conditionalEntropy(int paraAttribute) {
//Step 1. Statistic
int tempNumClasses = dataset.numClasses();
int tempNumValues = dataset.attribute(paraAttribute).numValues();
int tempNumInstances = availableInstances.length;
double[] tempValueCounts = new double[tempNumValues];
double[][] tempCountMatrix = new double[tempNumValues][tempNumClasses];
int tempClass, tempValue;
for (int i = 0; i < tempNumInstances; i++) {
tempClass = (int)dataset.instance(availableInstances[i]).classValue();
tempValue = (int)dataset.instance(availableInstances[i]).value(paraAttribute);
tempValueCounts[tempValue]++;
tempCountMatrix[tempValue][tempClass]++;
}// of for i
//Step 2
double resultEntropy = 0;
double tempEntropy, tempFraction;
for (int i = 0; i < tempNumValues; i++) {
if(tempValueCounts[i] == 0) {
continue;
}// of if
tempEntropy = 0;
for (int j = 0; j < tempNumClasses; j++) {
tempFraction = tempCountMatrix[i][j] / tempValueCounts[i];
if(tempFraction == 0) {
continue;
}
tempEntropy += -tempFraction * Math.log(tempFraction);
}// of for j
resultEntropy += tempValueCounts[i] / tempNumInstances * tempEntropy;
}// of for i
return resultEntropy;
}// of conditionalEntropy
/**
* Split the data according to the given attribute.
* @return The blocks.
*/
public int[][] splitData(int paraAttribute) {
int tempNumValues = dataset.attribute(paraAttribute).numValues();
int[][] resultBlocks = new int[tempNumValues][];
int[] tempSizes = new int[tempNumValues];
//First scan to count the size of each block.
int tempValue;
for (int i = 0; i < availableInstances.length; i++) {
tempValue = (int)dataset.instance(availableInstances[i]).value(paraAttribute);
tempSizes[tempValue]++;
}// of for i
//Allocate space
for (int i = 0; i < tempNumValues; i++) {
resultBlocks[i] = new int[tempSizes[i]];
}// of for i
//Second scan to fill.
Arrays.fill(tempSizes,0);
for (int i = 0; i < availableInstances.length; i++) {
tempValue = (int)dataset.instance(availableInstances[i]).value(paraAttribute);
//Copy data.
resultBlocks[tempValue][tempSizes[tempValue]] = availableInstances[i];
tempSizes[tempValue]++;
}// of for i
return resultBlocks;
}// of splitData
/**
* Build the tree recursively
*/
public void buildTree() {
if (pureJudge(availableInstances)) {
return;
}// of if
if (availableInstances.length <= smallBlockThreshold) {
return;
}// of if
selectBestAttribute();
int[][] tempSubBlocks = splitData(splitAttribute);
children = new ID3[tempSubBlocks.length];
//Construct the remaining attribute set.
int[] tempRemainingAttributes = new int[availableAttributes.length - 1];
for (int i = 0; i < availableAttributes.length; i++) {
if (availableAttributes[i] < splitAttribute) {
tempRemainingAttributes[i] = availableAttributes[i];
}else if (availableAttributes[i] > splitAttribute){
tempRemainingAttributes[i - 1] = availableAttributes[i];
}// of if
}// of for i
// Construct children.
for (int i = 0; i < children.length; i++) {
if ((tempSubBlocks[i]) == null || (tempSubBlocks[i].length == 0)) {
children[i] = null;
continue;
} else {
children[i] = new ID3(dataset,tempSubBlocks[i],tempRemainingAttributes);
// Important code: do this recursively
children[i].buildTree();
}// of if
} // of for i
}//of buildTree
/**
* Classify an instance
* @param paraInstance
* @return
*/
public int classify(Instance paraInstance) {
if (children == null) {
return label;
}// of if
ID3 tempChild = children[(int) paraInstance.value(splitAttribute)];
if (tempChild == null) {
return label;
}// of if
return tempChild.classify(paraInstance);
}
/**
* Test on a testing set.
* @param paraDataset The given testing data.
* @return The accuracy.
*/
public double test(Instances paraDataset) {
double tempCorrect = 0;
for (int i = 0; i < paraDataset.numInstances(); i++) {
if (classify(paraDataset.instance(i)) == (int)paraDataset.instance(i).classValue()) {
tempCorrect ++;
}// of i
}// of for i
return tempCorrect / paraDataset.numInstances();
}// of test
/**
* Test on the training set
* @return the accuracy
*/
public double selfTest() {
return test(dataset);
}// of selfTest
public String toString() {
String resultString = "";
String tempAttributeName = dataset.attribute(splitAttribute).name();
if (children == null) {
resultString += "class = " + label;
} else {
for (int i = 0; i < children.length; i++) {
if (children[i] == null) {
resultString += tempAttributeName + " = "
+ dataset.attribute(splitAttribute).value(i) + ":" + "class = " + label
+ "\r\n";
} else {
resultString += tempAttributeName + " = "
+ dataset.attribute(splitAttribute).value(i) + ":" + children[i]
+ "\r\n";
} // Of if
}// of for i
}// of if
return resultString;
}// of toString
public static void id3Test() {
ID3 tempID3 = new ID3("D:\\研究生学习\\测试文件\\sampledata-main\\weather.arff");
ID3.smallBlockThreshold = 3;
tempID3.buildTree();
System.out.println("The tree is: \r\n" + tempID3);
double tempAccuracy = tempID3.selfTest();
System.out.println("The accuracy is: " + tempAccuracy);
}// of id3Test
public static void main(String[] args) {
id3Test();
}
}// of class ID3
运行结果:
The tree is:
Outlook = Sunny:Humidity = High:class = 0
Humidity = Normal:class = 1
Humidity = Low:class = 0
Outlook = Overcast:class = 1
Outlook = Rain:Windy = FALSE:class = 1
Windy = TRUE:class = 0
The accuracy is: 1.0















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









