







Neural Networks for Multi-Instance Learning论文阅读笔记
多示例数据的数据集结构与单实例的数据不同,一个样本由一个包表示,一个包中有多个实例,标签被分配给包而不是实例。
定义加载多示例数据集的方法如下,接收输入path为包的路径,
# 加载普通MIL数据集
def Load_data(path, ne_label=0):
data = loadmat(path)['data']
dataset_name = path.split('/')[-1].split('.')[0]
bags, labels = [], []
for i in range(len(data)):
bags.append(data[i][0][:, :-1])
labels.append(data[i][1][0][0])
labels = np.array(labels)
num_bags = labels.shape[0]
if ne_label == -1:
labels = np.where(labels <= 0, -1, 1)
return bags,labels
使用如下代码可以获得数据集的基本信息:
load_data = Load_data(path=data_list[0])
bags = load_data[0]#所有包的集合
labels = load_data[1]#所有标签的集合
feature_num = len(load_data[0][0][0])#特征值数量
bag_num = len(load_data[0])#包的数量
test_index =np.array(getRandomIndex(bag_num,10))#获取测试集的缩影
train_index = np.delete(np.arange(bag_num),test_index)#获取训练集的索引
接下来我们定义Neural Networks for Multi-Instance Learning文中提到的神经网络结构,示意图如下所示,原文中提到了两种结构,我们在这里定义黑色图案表示的网络结构:
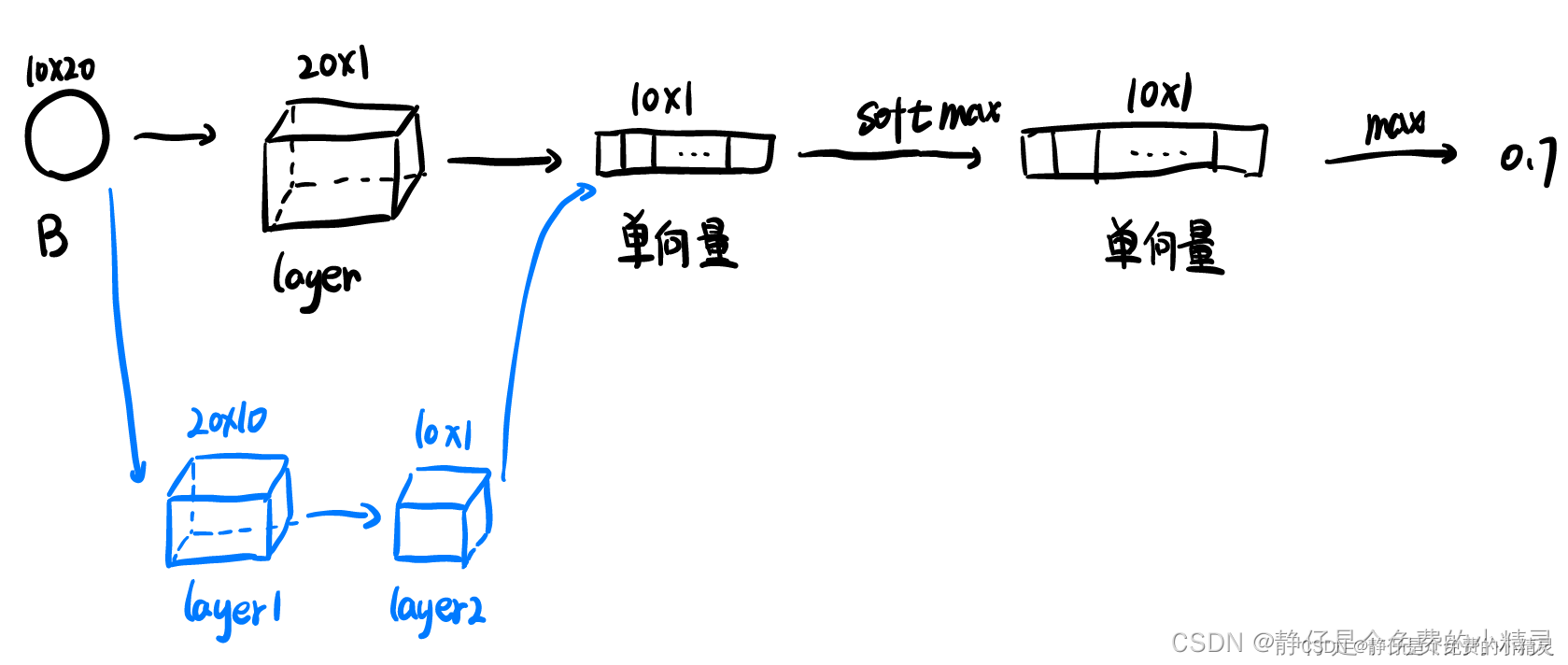
输入数据维度:因为一次将一个包放入神经网络进行训练,所以输入数据维度为:n*feature_num,n表示包中实例个数,feature_num表示特征值个数
#定义神经网络
class Net(nn.Module):
#定义神经网络结构,
def __init__(self,feature_num):
super(Net,self).__init__()
#第1层(全连接层)
self.fc1 = nn.Linear(feature_num,1)#输入维度是特征值数量,输出维度是1
def forward(self,x):#定义数据流向
x = self.fc1(x)#将输入数据传入第一层
x = F.sigmoid(x)#激活函数,将x的值弄到固定范围内
return x
Neural Networks for Multi-Instance Learning的损失函数为:
E
=
∑
i
=
1
N
E
i
=
∑
i
=
1
N
1
2
(
max
1
≤
j
≤
M
j
O
i
j
−
d
i
)
2
E=\sum_{i=1}^{N} E_{i}=\sum_{i=1}^{N} \frac{1}{2}\left(\max _{1 \leq j \leq M_{j}} O_{i j}-d_{i}\right)^{2}
E=i=1∑NEi=i=1∑N21(1≤j≤MjmaxOij−di)2
其中
E
i
E_{i}
Ei表示第
i
i
i个包的损失,
O
i
j
O_{ij}
Oij表示网络对实例
B
i
j
B_{ij}
Bij标签的预测值,
d
i
d_{i}
di表示包
B
i
B_i
Bi的实际标签,即期望输出的预测值。
定义损失函数:注意,这里的损失输出的是 E i E_i Ei, E E E的值还需要在后面再加求和一下
#定义损失函数
def Loss_criterion(out,target):
out_max = max(out)
loss = (out_max-target)*(out_max-target)*0.5
return loss
训练神经网络
epoch_num一次表示将训练集中的所有包都放到神经网络中学习一次
net_1 = Net(feature_num=feature_num)#创建神经网络实例
epoch_num = 50
for epoch_i in range(epoch_num):
loss = 0#初始化损失
#将每一个包依次放入神经网络进行训练
for i in train_index:
out = net_1(torch.tensor(bags[i],dtype=torch.float32))
target = labels[i]
loss_i = Loss_criterion(out,target)
loss = loss+loss_i
#输出损失
#print("loss",loss)
#反向传播
net_1.zero_grad()#清零梯度
loss.backward(retain_graph=True)#自动清零梯度,反向传递
#学习更新
optimizer = optim.SGD(net_1.parameters(),lr =0.0005)#更新学习速率0.01
optimizer.step()
epoch_i= epoch_i+1
获取训练结果:使用bag_prediction_label存储测试集的预测标签
print(len(test_index))
loss = 0
bag_prediction_label= []
for i in test_index:
out = net_1(torch.tensor(bags[i],dtype=torch.float32))
bag_prediction_label.append(max(out).item())
target = labels[i]
print(target)
loss_i = Loss_criterion(out,target)
loss = loss+loss_i
print("loss:",loss)
print("bag_prediction_label",bag_prediction_label)
ps :这个网络结构非常简单,效果也很差,写这个代码主要是为了了解多示例学习下的深度神经网络如何搭建,以及记录一下相应数据如何获取。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









