









1 可分离卷积
可分离卷积包括空间可分离卷积和深度可分离卷积。
1.1 空间可分离卷积(Spatially Separable Convolutions)
空间指的是[height, width] 两个维度;空间可分离卷积将[n*n]的卷积分成[1*n]和[n*1]两步进行计算。举例:
一个3*3的卷积核,在5*5的feature map上进行计算,一共需要3*3*9=81次计算。
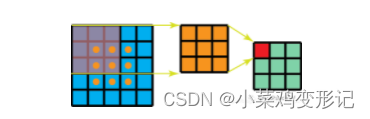
同样,在空间可分离卷积中,采用3*1和1*3的两个卷积核代替3*3卷积核,第一步3*1需要的计算量为15*3*1=45, 第二步 1*3需要的计算量为9*1*3=27,一共需要45+27=72次计算,小于81次。
故,空间可分离卷积能够减少运算次数,降低运算成本。
1.2 深度可分离卷积(Depth Separable Convolutions)
MobileNetV1就是把VGG中的标准卷积换成了深度可分离卷积。
深度可分离卷积的核心思想是将一个完整的卷积运算分为两步进行,分别为逐深度卷积(Depthwise Convolution)与逐点卷积(Pointwise Convolution)。
常规卷积若处理一个大小为64*64,三通道图片,经过包含4个滤波器的卷积层,最终输出4个feature map,且尺寸与输入层相同。可计算出卷积层参数量为4*3*3*3=108.
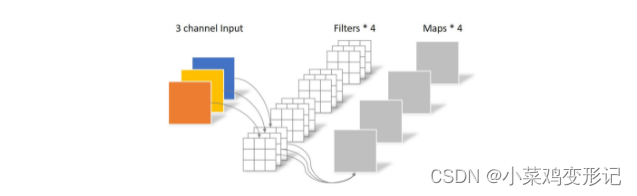
深度可分离卷积的操作,首先进行逐深度卷积,将单个滤波器应用到每一个输入通道,得到3个feature map,参数量为3*3*3=27. 然后进行逐点卷积,用1*1的卷积组合不同深度卷积的输出,得到一组新的输出。这里的卷积会将上一步的map在深度方向进行加权组合,生成新的feature map。 参数计算量为1*1*3*4=12. 总参数量为27+12=39。
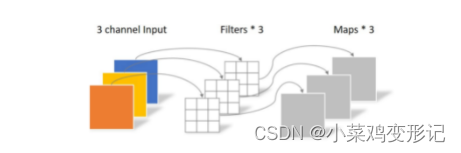
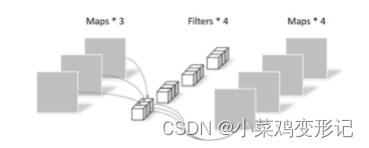
2 分组卷积和深度可分离卷积对比
2.1 分组卷积
分组卷积Group Convolution最早见于AlexNet网络中,是一种降低参数量和计算量的方法。
主要思想:对输入的特征进行分组,分别进行卷积,然后将特征组合起来。分组卷积的总参数量为总参数量的1/G,其中G为划分的组数。
优点:分组卷积除了可以降低参数量,还可以被视为一种结构化稀疏方法,相当于一种正则化方法。
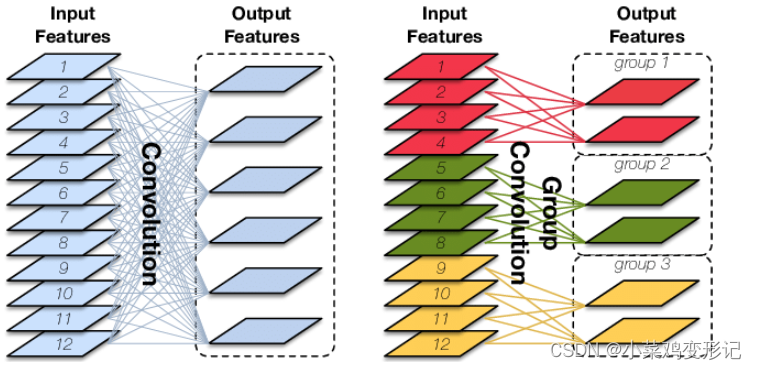
当分组数与输入输出维度相等时,即G=Din=Dout,相当于MobileNet和Xception中的深度卷积;
当分组数与输入输出维度相等,G=Din=Dout,且当卷积核的输入尺度与输入特征维度相等即K=W=H,输入的特征图为C*1*1,在MobileFaceNet中成为Global Depthwise Convolutions(GDC),即全局加权池化。与GAP即全局平均池化不同的是,GDC给每个位置赋予了可学习的权重。
3 MobileNet 系列
3.1 MobileNet_V1
1 创新点
① 提出MobileNet架构,使用深度可分离卷积替代传统卷积操作,减少计算量。
② 引入两个收缩超参数(Shrinking Hyperparameters):宽度乘子(width multiplier)和分辨率乘子(Resoution multiplier),其中宽度乘子主要作用为让网络的每一层变得更薄,改变通道数;分辨率乘子的作用为减少计算量的超参数。
2 存在的问题
深度卷积存在训练后部分信息丢失,导致部分核的权值为0.
3.2 MobileNet_V2
1 创新点
① 修改最后一层RELU6,引入Linear BottleNeck
② 引入特征复用结构,采取Resnet的思想;
③ 采用反向残差块inverted residuals block, 对RELU的缺陷进行回避。
RELU出现死亡神经元问题,而通过Resnet结构的复用,可以很大程度上缓解这种由于特征退化问题。
2 缺陷
① 网络端部最后阶段的计算量很大
3.3 MobileNet_V3
1 创新点
① 互补搜索技术组合:NAS执行模块级搜索,NetAdapt执行局部搜索;
② 网络结构改进:将最后一步的平均池化前移,并移除最后一个卷积层,引入h-swish激活函数。
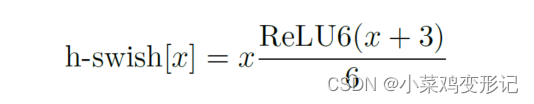
h-swish在保持精度的情况下具有:① 在软硬件框架中容易实现‘② 避免数值精度损失;③ 运行快、
ref.
(11条消息) 【论文学习】轻量级网络——MobileNetV3终于来了(含开源代码)_Lingyun_wu的博客-CSDN博客_mobilenetv3
















 5803
5803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











