







写在开头:网络上介绍QEMU原理的资料中大多会提及这份资料,即:QEMU Detailed Study,据笔者调研,这份文档是由cs专业的学生,Renjith Ravindran总结的。但是现在只有第七章流传开来,而其他章节据作者所述,并没有讨论任何关于 QEMU 或翻译过程的内容。 因此,本篇博文focus on第七章QEMU Detailed Study内容的学习。
(一边听着CV景向谁依的歌声,一边写博客,好开森,嘿嘿!)
话不多说,开始记录!
官方文档中给出: “QEMU is a generic and open source machine emulator and virtualizer.”
这里的单词emulator,网络上的翻译有两种,分别是“模拟器”和“仿真器”(模拟器偏多),在本文中将emulator翻译为模拟器,(笔者看到有一些博文专门记录了“模拟器”和“仿真器”的区别,如有必要,后续继续完善)。
目录
7.2.1 开始执行(/vl.c,/cpus.c,/exec-all.c,/exec.c,/cpu-exec.c)
7.2.3 Guest(Target) Specific(/target-xyz/)
7.2.4 Host(TCG)Specific(/tcg/)
7.2.5 总结(/vl.c,/target-xyz/translate.c,/tcg/tcg.c,/tcg/*/tcg-target.c,/cpu-exec.c)
qemu_main_loop_start(...){/cpus.c}:
profile_getclock(...){/qemu-timer.c}:
struct CPUState{/target-xyz/cpu.h}:
struct TranslationBlock {/exec-all.h}:
tb_find_fast(...){/cpu-exec.c}:
cpu_get_tb_cpu_state(...){/target-xyz/cpu.h}:
tb_jmp_cache_hash_func(...){/exec-all.h}:
tb_find_slow(...){/cpu-exec.c}:
cpu_gen_code(...){translate-all.c}:
tcg_gen_code(...){/tcg/tcg.c}:
#define tcg_qemu_tb_exec(...){/tcg/tcg.g}:
7.1 基础术语介绍
QEMU是一个机器模拟器,可以在运行它的机器上模拟给定数量的处理器架构。对于QEMU,模拟的架构称为Target。运行QEMU模拟Target的真实机器称为Host。虚拟机(Target)代码到Host代码的动态转换是由QEMU中称为Tiny Code Generator 或简称TCG的模块完成的。对于TCG,“Target”一词具有不同的含义。TCG创建代码来模拟Target,因此TCG创建的代码称为它的Target。因此,当说到TCG Target时,指的是生成的Host代码。 图7.1阐明了这些不同的术语。

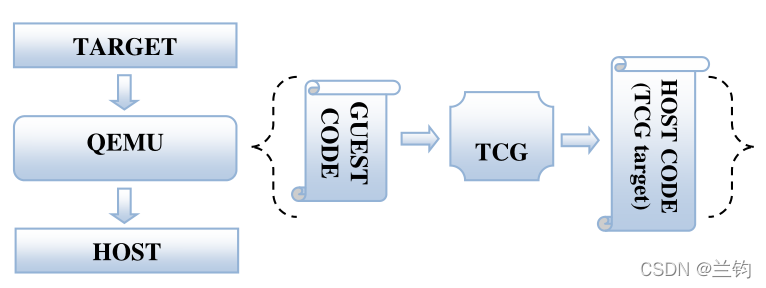
图7.1 QEMU与TCG的Target
因此,可以将模拟器运行的代码(OS + USER TOOLS)称为guest code(客户代码/来宾代码)。QEMU的功能是提取guest code并将其转换为主机特定代码。因此,整个翻译任务由两部分组成:首先,目标代码块(translation block,TB)被转换为TCG ops(一种独立于机器的中间符号),然后,TB的TCG ops被TCG转换为主机架构的Host code(主机代码)。在它们之间可以执行可选的优化过程。
7.2 代码库组织
需要清楚地了解QEMU代码库才能添加新功能,扩展模拟器,将其生成的代码迁移到远程节点中执行。QEMU代码库有1300多个文件,这些文件被组织成特定的部分。本节将介绍QEMU代码库的组织。
在本节中,代码库中最浅的目录深度将由“/”表示,连续的目录深度将遵循通常的Unix文件路径表示方法。
7.2.1 开始执行(/vl.c,/cpus.c,/exec-all.c,/exec.c,/cpu-exec.c)
/中对研究很重要的 C 文件有:/vl.c,/cpus.c,/exec-all.c,/exec.c,/cpu-exec.c。开始执行的“main”函数在/vl.c中定义。该文件中的函数根据给定的虚拟机规格(如RAM大小、可用的设备、CPU数量等)设置虚拟机环境。在主函数中,设置虚拟机后,通过文件:例如/cpus.c、/exec-all.c、/exec.c、/cpu-exec.c来执行分支。
7.2.2 模拟硬件(/hw/)
模拟虚拟机中所有虚拟硬件的代码可以在/hw/中找到。QEMU模拟了大量硬件,但在本研究中不需要详细了解硬件是如何模拟的(如有必要,后续补充)。
7.2.3 Guest(Target) Specific(/target-xyz/)
目前在QEMU中模拟的处理器架构是:Alpha、ARM、Cris、i386、M68K、PPC、Sparc、Mips、MicroBlaze、S390X和SH4。将TB转换为TCG ops所需的特定于这些架构的代码在/target-xyz/中提供,其中xyz可以是上述任何给定的架构名称。因此,特定于i386的代码可以在/target-i386/中找到。这部分可以称为TCG的前端。
7.2.4 Host(TCG)Specific(/tcg/)
用于从TCG ops生成host code的主机特定代码放置在/tcg/中。在TCG中可以找到/xyz/,其中xyz可以是i386、sparc等,其中包含将TCG ops转换为特定体系结构代码的代码。这部分可以称为TCG的后端。
7.2.5 总结(/vl.c,/target-xyz/translate.c,/tcg/tcg.c,/tcg/*/tcg-target.c,/cpu-exec.c)
| /vl.c | 主模拟器循环、虚拟机设置和CPU执行 |
| /target-xyz/translate.c | 提取的guest code(特定于guest的ISA,Instruction Set Architecture,硬件指令集)被转换为独立于架构的TCG ops |
| /tcg/tcg.c | TCG的主代码。 |
| /tcg/*/tcg-target.c | 将TCG ops转换为host code(特定于主机的ISA) |
| /cpu-exec.c | /cpu-exec.c中的函数cpu-exec()查找下一个翻译块(TB),如果没有找到,则调用以生成下一个TB并最终执行生成的代码。 |
7.3 TCG-动态翻译
历史:在0.9.1版本之前的QEMU中的动态翻译是由DynGen执行的。DynGen将TB转换为C代码,GCC(GNU C编译器)将C代码转换为主机特定代码。该过程的问题在于DynGen与GCC紧密耦合,并在GCC演变时出现了问题。为了消除翻译器与GCC的紧密耦合,提出了一个新程序:TCG。
动态翻译在需要时转换代码。这样做的目的是在执行代码生成的同时,尽可能多地花时间执行生成的代码。每次从TB生成代码时,都会在执行之前存储在代码缓存(code cache)中。大多数情况下,由于局部访问性,会重复需要相同的TB,因此,与其重新生成相同的代码,不如保存它。图7.2总结了相应的情况。一旦代码缓存满了,为简单起见,整个代码缓存都会被刷新,而不是使用LRU算法。

7.2 跳转到代码缓存(code cache)
知识点补充
编译与反编译:
编译是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(通常为低级语言或机器语言)的翻译过程。然而,也存在从低级语言到高级语言的编译器,这类编译器中用来从由高级语言生成的低级语言代码重新生成高级语言代码的又被叫做反编译器。
编译器:
编译器就是将“一种语言(高级语言)”翻译为“另一种语言(低级语言)”的程序。
一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。
对于C#、VB等高级语言而言,此时编译器完成的功能是把源码(SourceCode)编译成通用中间语言(MSIL/CIL)的字节码(ByteCode)。最后运行的时候通过通用语言运行库的转换,变成最终可以被CPU直接计算的机器码(NativeCode)。
编译器负责从源代码生成目标代码。为了为函数调用生成目标代码,像GCC这样的编译器会生成特殊的汇编代码,这些代码在调用函数之前和函数返回之前执行必要的操作。生成的这种特殊汇编代码称为函数序言(Function Prologue)和尾声(Epilogue)。
函数序言和尾声只是一组指令,它在函数调用时为函数设置上下文,并在函数返回时进行恢复。
如果体系结构有一个基指针和一个堆栈指针,函数序言通常会执行以下操作:
•将当前的基指针压入堆栈,以便以后可以恢复
•用当前堆栈指针替换旧基址指针,以便在旧堆栈的顶部创建新堆栈
•将堆栈指针沿堆栈进一步移动,以便在当前堆栈帧中为函数的局部变量腾出空间
函数尾声反转函数序言的操作,并将控制权返回给调用函数。它通常会执行以下操作:
•将堆栈指针替换为当前的基指针,因此堆栈指针将恢复到其在序言之前的值
•将基指针从堆栈中弹出,使其恢复到序言之前的值
•通过从堆栈中弹出前一帧的程序计数器并跳转到它,返回调用函数
TCG本身可以被视为是一个可以动态生成目标代码的编译器。TCG生成的代码存储在缓冲区(代码缓存)中。如图7.3所示,执行控制(execution control)通过TCG的非常重要的Prologue和Epilogue传入和传出代码缓存。

图7.3 函数序言和尾声的使用
下图(7.4–7.7)说明了TCG的函数。下一节将简要介绍图中所示的函数。

图7.4 动态翻译的整体流程

图7.5 动态翻译-guest code

图7.6 动态翻译-TCG ops

图7.7 动态翻译-显示生成的host Code(为了可读性,用汇编语言显示)
7.4 TB的链接
从代码缓存返回静态代码(QEMU代码)并跳回代码缓存通常比较慢。为了解决这个问题,QEMU将每个TB链接到下一个TB。因此,执行完一个TB后直接跳转到下一个TB,不返回静态代码。当TB返回到静态代码时,就会发生块的链接(chaining of block)。因此,当TB1返回(因为没有链接)到静态代码时,下一个TB TB2,就会被找到、生成并执行。当TB2返回时,它会立即链接到TB1。这样可以确保下次执行TB1时,TB2会跟随它而不返回静态代码。下页中的图7.8(a-c)说明了TB的链接。

7.5 执行追踪
本节尝试追踪踪QEMU的执行过程,并具体指出特定文件的位置和调用的函数的声明。本节将主要关注QEMU的TCG部分,因此将是查找生成Host code的代码部分的关键。充分理解QEMU中的代码生成对于完善QEMU以实现EVM(超轻量物联网虚拟机)是必要的。
文件/文件夹路径符号与前面“代码库”部分中使用的符号相同,但为了指定函数声明和定义语句的位置,需要增加相同的符号。
因此,func1(...){/folder/file.c}意味着func1()的声明在/folder/file.c中,与#define symbol_name{/folder/file.c},var var_name { /folder/file.c}相同。
类似地,为了突出显示特定的代码段,使用了以下约定。
表示‘int max=MAX;’在相应文件的第346行

main(..){/vl.c}:
main函数解析启动时传递的命令行参数,并根据RAM大小、硬盘大小、引导盘等参数设置虚拟机(VM)。一旦虚拟机设置完毕,main()就会调用main_loop()
main_loop(...){/vl.c}:
函数main_loop首先调用qemu_main_loop_start(),然后在条件为vm_can_run()的do-while内无限循环cpu_exec_all()和profile_getclock()。无限for循环继续检查一些VM停止情况,如qemu_shutdown_requested(),qemu_powerdown_requested(),qemu_vmstop_requested()等。这些停止情况将不再进一步研究。
qemu_main_loop_start(...){/cpus.c}:
函数qemu_main_loop_start设置变量 qemu_system_ready = 1并调用qemu_cond_broadcast(),该函数主要处理重启所有等待条件变量的线程。这里不再进一步研究。请查看 /qemu-thread.c了解更多详情
cpu_exec_all(...){/cpus.c}:
函数cpu_exec_all主要轮询VM中可用的CPU(内核)。QEMU最多可以有256个内核。但是所有这些内核都将以循环方式执行,因此不能完全模拟所有内核并行运行的多核处理器。一旦选择了下一个CPU,就会找到它的状态(CPUState *env),并将该状态传递给qemu_cpu_exec(),以便在检查条件cpu_can_run()之后,从当前状态继续执行所选CPU。
profile_getclock(...){/qemu-timer.c}:
函数profile_getclock主要处理时序(CLOCK_MONOTONIC),这里不做进一步研究。
struct CPUState{/target-xyz/cpu.h}:
structure CPUState 是特定于架构的,主要保存CPU状态,如标准寄存器、段、FPU状态、异常/中断处理、处理器功能和一些模拟器特定的内部变量和标志。
qemu_cpu_exec(...){/cpus.c}:
函数qemu_cpu_exec主要调用了cpu_exec().
cpu_exec(...){/cpu-exec.c}:
函数cpu_exec被称为“主执行循环”。这里第一次初始化翻译块TB (TranslationBlock *tb),然后代码主要继续处理异常。在两个嵌套的无限for循环的深处,可以找到tb_find_fast()和tcg_qemu_tb_exec()。tb_find_fast()为Guest启动下一个TB的搜索,然后生成Host code。然后通过 tcg_qemu_tb_exec() 执行生成的Host code。
struct TranslationBlock {/exec-all.h}:
Structure TranslationBlock包含以下内容; PC,CS_BASE,与此TB对应的标志Flags,tc_ptr(指向此TB的翻译代码的指针),tb_next_offset[2],tb_jmp_offset[2](均用于查找链接到此TB的TB。即,此TB后面的TB)、*jmp_next[2]、*jmp_first(指向跳转到此TB的TB)。
tb_find_fast(...){/cpu-exec.c}:
函数tb_find_fast 调用 cpu_get_tb_cpu_state() ,它从CPUState(env)中获取程序计数器(PC)。这个PC值被传递给一个哈希函数以获取tb_jmp_cache[](一个hash表)中TB的索引。使用此索引可以从tb_jmp_cache中找到下一个TB。

tb = env->tb_jmp_cache[tb_jmp_cache_hash_func(pc)](上图中少了个t)
因此,可以发现,一旦找到TB(对于特定的PC值),它就会存储在tb_jmp_cache中,以便以后可以使用哈希函数(tb_jmp_cache_hash_func(pc))找到的索引从tb_jmp_cache中重用它。然后代码检查找到的TB的有效性,如果找到的TB无效,则调用tb_find_slow()。
cpu_get_tb_cpu_state(...){/target-xyz/cpu.h}:
函数cpu_get_tb_cpu_state主要是从当前的CPUState(env)中找到PC、BP、Flags。
tb_jmp_cache_hash_func(...){/exec-all.h}:
这是一个哈希函数,使用PC作为key在tb_jmp_cache中查找TB的偏移量。
tb_find_slow(...){/cpu-exec.c}:
当tb_find_fast()失败时使用函数tb_find_slow。这次尝试使用物理内存映射来查找TB。

phys_pc应该是Guest OS的PC的物理内存地址,它用于通过哈希函数查找下一个TB。
:147

上面的ptb1是下一个TB,它的有效性在后面的代码中检查。如果没有找到有效的TB,则通过TB_gen_code()生成新的TB;否则,如果找到有效TB,则将其快速添加到tb_jmp_cache中,tb_jmp_cache_hash_func() 找到的索引处。

tb_gen_code(...){/exec.c}:
函数tb_gen_code从分配(tb_alloc())一个新的TB开始,使用get_page_addr_code()从CPUState的PC中找到TB的PC。

完成此操作后,调用cpu_gen_code(),然后调用tb_link_page(),这将添加一个新TB并将其链接到物理页表
cpu_gen_code(...){translate-all.c}:
函数cpu_gen_code启动实际代码生成。其中有一系列后续函数调用,如下所示。
gen_intermediate_code(){/target-xyz/translate.c}->
gen_intermediate_code_internal(){/target-xyz/translate.c->
disas_insn(){/target-xyz/translate.c}
函数disas_insn通过target(Guest)指令的长 switch case和最终将TCG ops 添加到code_buff的对应函数组,将 Guest code 实际转换为 TCG ops。生成TCG ops后,将调用tcg_gen_code
tcg_gen_code(...){/tcg/tcg.c}:
函数tcg_gen_code将TCG ops 转换为主机特定代码。查看上一节“TCG- Dynamic Translator”
#define tcg_qemu_tb_exec(...){/tcg/tcg.g}:
一旦获得下一个TB,通过上述所有过程,需要执行TB。TB通过/exec-cpu.c 中的 tcg_qemu_tb_exec() 执行。

实际上,tcg_qemu_tb_exec() 是在 /tcg/tcg.h 中定义的宏函数


要理解上述代码行,需要对函数指针有很好的了解。以下几行将详细阐述对这一点的理解。
众所周知,(int)var会将变量显式转换为 int 类型。在相同意义上(long REGPARM(*)(void*))是一种类型--指向一个函数的指针,该函数接受void*参数并返回一个long。这里的REGPARAM(*)是一个GCC编译器指令,它使函数的参数通过寄存器传递而不是堆栈传递。
如果函数名出现在 ((long REGPARM (*func_name)(void *)) 中,那么 ((long REGPARM (*)(void *)) 的意图就很清楚了。但是这里使用它时没有函数名(但起到了作用)。当使用数组名时,将获得数组基址,从而指向(指针)数组。因此(function_pointer)array_name将数组指针转换为函数指针。
函数通过其指针调用(*pointer_to_func)(args),因此((long REGPARM (*)(void *))code_gen_prologue)(tb_ptr) 进行函数调用。可以看到,上述函数调用中缺少一个“*”,但可以测试一下(*pointer_to_func)(args)和(pointer_to_func)(args)是否等效。
因此,上面的解释说明了code_gen_prologue这个数组,被强制转换为函数并执行。code_gen_prologue中包含一个二进制形式的函数,该函数接受一个参数tc_ptr,并返回一个long,即下一个TB。code_gen_prologue中的函数是函数序言,它将控制权转移到tc_ptr指向的生成的主机代码。














 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









