










一. 对比学习介绍
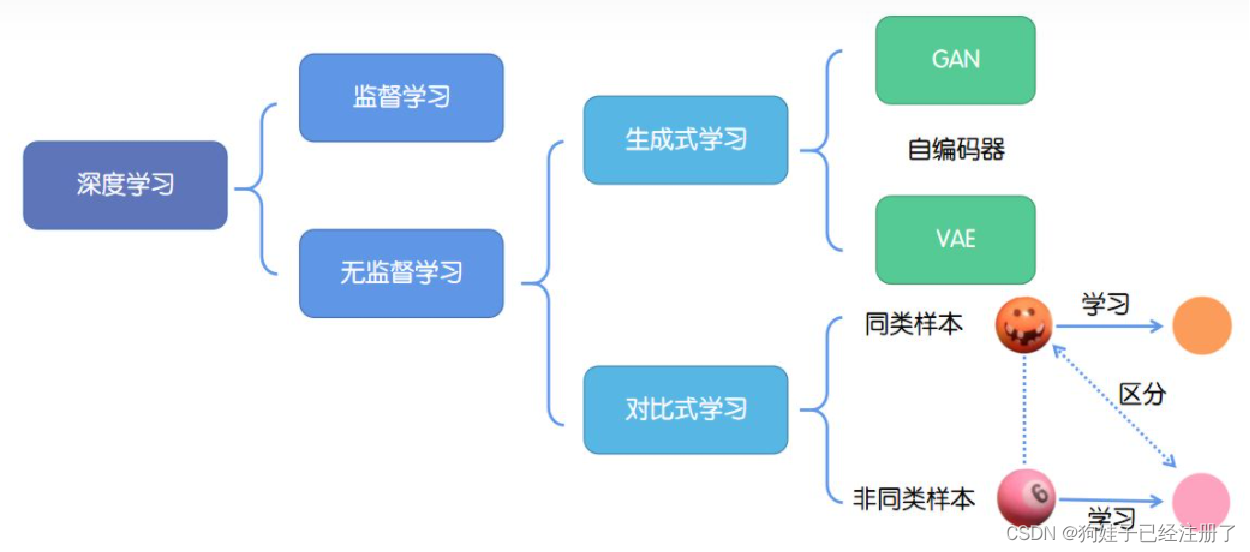
有监督学习技术相对成熟,但是对海量的数据进行标记需要花费大量的时间和资源。而自监督学习(Self-supervised learning)可以避免对数据集进行大量的标签标注。它可以把自己定义的伪标签当作训练的信号,然后把学习到的表示用作下游任务中。
而自监督学习又分为生成式学习和对比式学习。生成式学习以自编码器(例如GAN,VAE等)这类方法为代表,从原始数据出发,生成新的数据,使得生成数据尽可能的还原原始数据。但是生成式学习方法通常模型很复杂,不容易训练。对比学习不要求能够重新生成原始数据,只是要求模型能够区分相似样本与不相似样本,着重于学习相似样本之间的共同特征,因此相对于生成学习来说,对比学习模型更加简单,泛化能力更强。所以近年来国内外研究学者都对对比学习展示了极大的兴趣。对比学习作为自监督学习的杰出代表,已经被广泛应用于自然语言处理(NLP)和机器视觉(CV)领域。
二. 对比学习的主要问题研究
1. 对比学习的目标
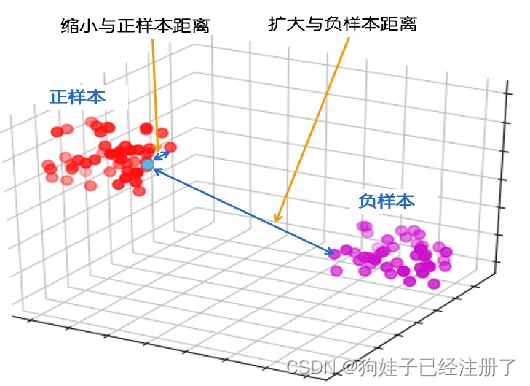
将⼀个原始样本(可作为锚点)增强过的新样本们(正样本)在嵌入空间中尽可能地近,然后让不同的样本(负样本)之间尽可能地相远。
在空间上看对比学习,就是缩小与正样本间的距离,扩大与负样本间的距离,使正样本与锚点的距离远远小于锚点与负样本之间的距离,(或使正样本与锚点的相似度远远大于负样本与锚点的相似度)。
2. 对比学习的两个核心问题
损失函数的设计和正负样本的构造。
3. 主线
拉大正负样本之间的距离。
4. 主要研究问题
4.1 如何构造正负例。引入负样本,实质是引入一种约束,能够防止模型坍塌的情况出现。不同的数据增强方式可以让模型学习到不同的特征表示,不同的表征适用于不同的下游任务。选择合适的数据增强方式,构造合理的正负例,是能否成功提取对下游任务有用表征的关键。
4.1.1 设计负例
对一个 batch 中的图片做数据增强,从增强数据中提取表征向量,再由全连接层和激活层投影到对比损失空间。同一图片的数据增强互为正例,而不同图片之间互为负例。训练的目标是期望同一张图片表征向量近似,不同图片表征向量远离。扩展负样本数量也导致了 batch size过大而造成 GPU 内存溢出,Y.Kalantidis 等通过 Mix-up的方式来得到模型难以识别的负样本,提高对比学习模型的效率。
4.1.2 设计正例
常见的对比学习是设计一个正例与若干个负例,而负例通常是一个 batch 内随机采样得到,在多分类任务中,容易发生错误,从而导致学习效果变差。P.Khosla 等提出了监督对比损失,使用标注的方式,对训练样本考虑多对正例比较。采用两阶段训练,首先标注自监督对比学习的正负例对,然后采用监督方式进行对比学习。
4.1.3 只有正例的对比学习(BYOL,自然语言处理领域)
BYOL 里面所有的图像都是正例,通过最大化“投影”和“预测”特征的相似性,不使用负例,学习表征。首先,有一个网络参数随机初始化且固定的 target network;一个网络参数会变化的 online network;等这个 online network 训练好之后,将 target network 替换为效果更好的网络参数 (比如此时的 online network),然后再迭代一次,也就是再训练一轮 online network,效果是基于上一次的叠加。
4.2 负例的数量。
要想获得良好的对比性能,获取互信息的下界,就需要一个较大的负例与正例的比值,即需要大量的负例。这样一来,给大型数据集带来了潜在的计算问题。如果负样本是容易被分辨的样本,则对模型起不到学习的作用,同时又增加了训练的计算量,得不偿失。 解决这一问题,可以考虑采用恰当的数据增强方法,采样或生成大量模型难以分辨的样本,供模型学习,从而得到更多可区分的特征。例如可以使用对抗生成样本、选取与正样本最邻近的负样本等方法。选取高质量的负样本,可以使得模型学习到概括性特征,又同时降低了训练的计算负担。
4.3 如何构造损失函数。对比学习的研究目标是要学习一个编码器,满足下式:
![]()
其中,s( ) 是相似度度量函数,𝑥为输入样本,x+为正例,x-为负例。要使得输入样本与正例的相似度远大于负例,需要通过损失函数来达到。根据不同的任务来设计不同的损失函数。
5. 对比学习思想
对比学习通过将原始数据分别与正负样本进行对比,来学习样本的特征表示,以最大化原始样本与正样本之间的相似性(互信息)。
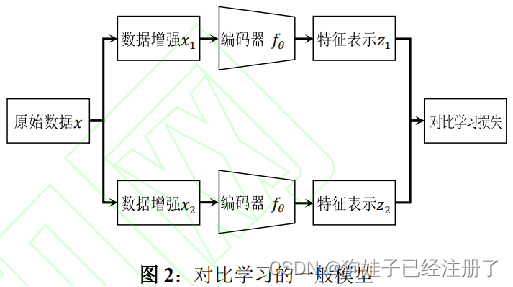
通过对比学习的一般模型可以看到,原始数据经过不同数据增强,再分别经过映射函数(一般是特征提取编码器)学习数据特征表示,将这些特征用于计算对比学习的损失函数,以最小化对比损失。目前,现有的大部分对比学习架构都遵循图 2 的右半部分,模型的不同之处,基本都表现在对原始数据的数据增强方式上,不同的增强方法会带来不同的特征表示,从而影响下游任务的效果。
6. 对比学习中的损失函数
损失函数是用来评估模型的预测值与真实值之间的差别。损失函数的设计,直接影响到模型的性能。对比学习可以看作是一种降维学习方法,通过学习一种映射关系,将样本通过映射函数映射到低维空间,使得同类样本距离拉近,不同类样本距离推远。


















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









