









1、透视表privot_table
当得到一张数据平面表数据时,例如:
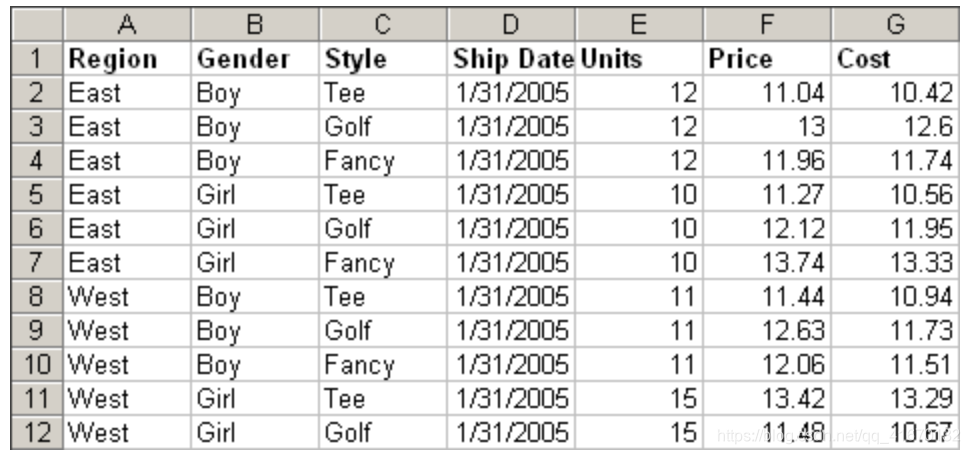
要想实现表中一个变量与其他多个变量之间的关系,可以用pivot_table实现,table.pivot_table(index='变量1',values=[变量2]‘,’变量3‘,....,aggfunc=np.sum)
其中最后的aggfunc指的是要求的是什么,可以是求和sum,或max等等,默认是np.mean求均值
2、删除缺失值dropna
当想删除表中某一行或列中的缺失值,也就是空白值时,使用table.dropna(axit=0,subset=['Price','Cost'])
其中第一个参数可以选择需要删除的行或列,第二个参数选择相应的变量
3、定位loc
当你想查看每个位置的值的时候,使用table.loc[3,'Cost'],表示(第三行,Cost)的值,也可以用loc[0,10]表示打印前十个值
4、按字段排序sort_values
当你想用表中一个字段进行排序,例如用Cost进行排序,用table.sort_values('Cost',ascending='False'),通过修改ascending的T/F选择顺序还是逆序
5、自定义函数apply
当你想把自己定义的函数快速用到数据处理中时,使用apply进行操作
例:def sum_min(column):
........
return summin_item
操作:table.apply(sum_min,axis=1),也就是通过sum_min函数对table进行操作,还可以通过axis选择某一维度进行计算















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









