







Pandas>>pivot_table()函数列转行
DataFrame.pivot_table(
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All')- index:必选参数,用来指定行索引。如果用数组做行索引,数据必须等长。
- columns:必选参数,用来指定列索引。
- values:可选参数,用来做集合的值。默认是显示所有的值。
- aggfunc:聚合函数, pivot_table后新dataframe的值都会通过aggfunc进行运算。在pivot_table会将多重值调用aggfunc函数后放在相应的位置上。默认的aggfunc函数为求平均。
- fill_value:数据为空情况处理,默认填充NAN值。可以修改如果原数据为空,比如设为0
- margins:添加行列的总计,默认不显示。
- dropna:如果整行都为NA值,则进行丢弃,默认丢弃。
- margins_name:在margins参数为ture时,用来修改margins的名称
import pandas as pd
import numpy as np
data_test= pd.DataFrame([
[1,'张三','sex',1],
[1,'张三','height',1.78],
[1,'张三','weight',60],
[2,'李四','sex',1],
[2,'李四','height',1.75],
[2,'李四','weight',59],
[3,'王五','sex',0],
[3,'王五','height',1.72],
[3,'王五','weight',58]
#[3,'王五','weight',58]
],
columns =['id','name','description','description_value']
)
data_test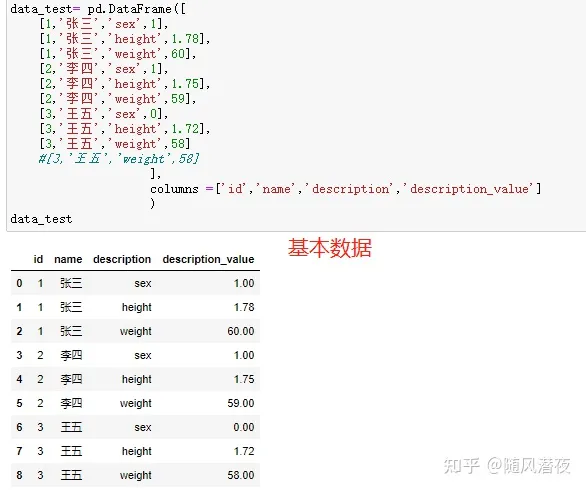
如下将多行转换成一行:
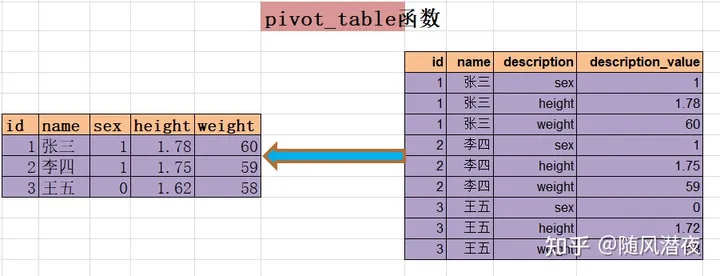
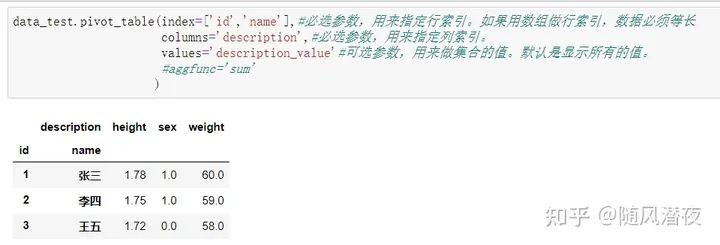
data_test.pivot_table(index=['id','name'],#必选参数,用来指定行索引。如果用数组做行索引,数据必须等长
columns='description',#必选参数,用来指定列索引。
values='description_value'#可选参数,用来做集合的值。默认是显示所有的值。
#aggfunc='sum'
)
aggfunc聚合函数,在什么时候用呢?如下基础数据:
import pandas as pd
import numpy as np
data_test= pd.DataFrame([
[1,'张三','sex',1],
[1,'张三','height',1.78],
[1,'张三','weight',60],
[2,'李四','sex',1],
[2,'李四','height',1.75],
[2,'李四','weight',59],
[3,'王五','sex',0],
[3,'王五','height',1.72],
[3,'王五','weight',58],
[3,'王五','weight',58]
],
columns =['id','name','description','description_value']
)
data_test
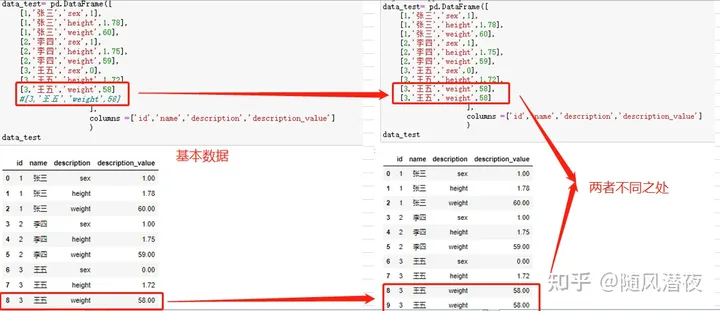
这里也对其进行多行转一行:
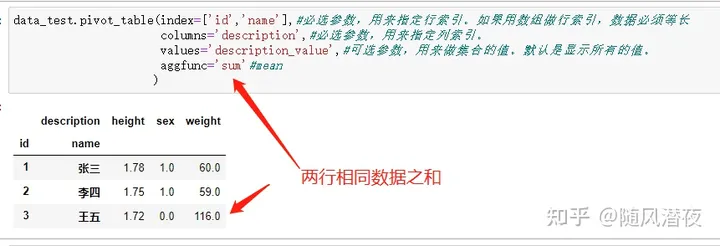
data_test.pivot_table(index=['id','name'],#必选参数,用来指定行索引。如果用数组做行索引,数据必须等长
columns='description',#必选参数,用来指定列索引。
values='description_value',#可选参数,用来做集合的值。默认是显示所有的值。
aggfunc='sum'#mean
)
总结:pd.pivot_table()函数列转行,有必选参数,强调如下:
- index:必选参数,用来指定行索引。如果用数组做行索引,数据必须等长。
- columns:必选参数,用来指定列索引。
- values:可选参数,用来做集合的值。默认是显示所有的值
==================详细版==================================
Pandas的pivot_table函数(数据透视表)
pivot_table() 的特点就是默认显示指定索引列和所有数值列。
索引显示的是唯一值,所以会把对应的数值处理成均值。其他str类型的列都会自动忽略。
当然,使用pivot_table() 时,可以通过添加参数进行计数或求和
示例中账号是int类型,如果是str类型,那么运行结果不会显示[‘账号’]这一列的内容。
import numpy as np
import pandas as pd
df = pd.DataFrame({
'账号':[714466,714466,714466,737550,146832,218895,218895,412290,740150,141962,163416,239344,239344,307599,688981,729833,729833],
'客户名称':['华山派股份有限公司','华山派股份有限公司','华山派股份有限公司','丐帮(北京) 合伙人公司','恶人谷资产管理公司','桃花岛','桃花岛','有间客栈','逍遥子影业','白驼山(上海)影视艺术有限公司','聚贤庄','全真教药业','全真教药业','天地会快递','福寿堂','快手三教育培训有限公司','快手三教育培训有限公司'],
'销售':['令狐冲','令狐冲','令狐冲','令狐冲','江小鱼','江小鱼','江小鱼','段誉','段誉','欧阳克','欧阳克','欧阳克','欧阳克','韦小宝','韦小宝','韦小宝','韦小宝'],
'销售总监':['岳不群','岳不群','岳不群','岳不群','岳不群','岳不群','岳不群','岳不群','岳不群','完颜洪烈','完颜洪烈','完颜洪烈','完颜洪烈','完颜洪烈','完颜洪烈','完颜洪烈','完颜洪烈'],
'产品':['黑玉断续膏','葵花宝典','含笑半步癫','黑玉断续膏','黑玉断续膏','黑玉断续膏','葵花宝典','含笑半步癫','黑玉断续膏','黑玉断续膏','黑玉断续膏','含笑半步癫','葵花宝典','含笑半步癫','黑玉断续膏','黑玉断续膏','如意勾'],
'数量':[1,2,1,3,1,3,1,2,4,2,2,1,3,5,2,3,1],
'价格':[3000,2000,1000,3000,1000,3000,1000,2000,4000,2000,2000,1000,2000,3000,1000,4000,2000],
'状态':['流程中','流程中','待审批','驳回','已完成','流程中','流程中','待审批','驳回','已完成','流程中','待审批','待审批','已完成','已完成','驳回','流程中'],
})

index
指定单索引
索引变成了[客户名称]这一列,values显示的只有数字,而且都处理成均值。
比如:华山三个,数量4/3,价格6000/3,账号就不用说了,三个都一样,均值自然就是其中一个;快手两个,数量4/2,价格6000/2
指定多索引
索引顺序能决定不同的视觉体验,虽然结果是一致的。
| pd.pivot_table(df, index=['销售总监','销售','客户名称']) | pd.pivot_table(df, index=['客户名称','销售','销售总监']) |
|---|---|
 |  |
values
如果不需要显示全部的数值列,可以用Values参数指定
# 显然Values不能随便指定,pivot_table()只能显示数值列
print(pd.pivot_table(df, index=['销售总监','销售'], values=['状态']))
'''
Empty DataFrame
Columns: []
Index: [(完颜洪烈, 欧阳克), (完颜洪烈, 韦小宝), (岳不群, 令狐冲), (岳不群, 段誉), (岳不群, 江小鱼)]
'''

aggfunc
当我们未设置aggfunc时,它默认aggfunc='mean’计算均值。
| 单一参数 | 多个参数 |
|---|---|
| pd.pivot_table(df, index=['销售总监','销售','客户名称'],values=['数量','价格'],aggfunc=np.sum) | pd.pivot_table(df, index=['销售总监','销售','客户名称'],values=['数量','价格'],aggfunc=[np.mean,len,np.sum]) |
 |  |
columns
fill_value
columns参数就是用来显示字符型数据的,和fill_value搭配使用
补充:当 values,aggfunc,columns 的取值只有一个时,有无中括号效果略有不同。
| columns,没有的字段显示NaN | fill_value,用0填充空值 |
|---|---|
| pd.pivot_table(df, index=['销售总监','销售'], values=['价格'],aggfunc=[np.sum],columns=['产品']) | pd.pivot_table(df, index=['销售总监','销售'], values=['价格'],aggfunc=[np.sum],columns=['产品'],fill_value=0) |
 |  |
通过添加参数,还可以显示更多信息。下面这个就花哨多了
pd.pivot_table(df, index=['销售总监','销售','客户名称','产品'],values=['数量','价格'],aggfunc=[np.sum],columns=['状态'],fill_value=0,margins=True)
- 1

以销售总监层面,来看销售状态
(aggfunc的参数使用了字典的方式对每一列做出了不同的计算要求。也可以加多个,比如 ‘价格’:[np.mean,np.sum])
pd.pivot_table(df,index=['销售总监','状态'], values=['数量','价格'], columns=['产品'],aggfunc={'数量':len,'价格':np.sum},fill_value=0,margins=True)
- 1

数据透视表过滤
生成数据后,你可以使用DataFrame的操作方式对其进行过滤。
比如:你只想看某一位销售总监:
data = pd.pivot_table(df,index=['销售总监','状态'], values=['数量','价格'], columns=['产品'],aggfunc={'数量':len,'价格':np.sum},fill_value=0)
data.query("销售总监==['完颜洪烈']")
- 1
- 2

查看所有待审批和驳回的交易
data = pd.pivot_table(df,index=['销售总监','状态'], values=['数量','价格'], columns=['产品'],aggfunc={'数量':len,'价格':np.sum},fill_value=0)
data.query("状态==['待审批','驳回']")
- 1
- 2

转到Excel
pd.pivot_table(df,index=['销售总监','销售','产品'], values=['数量','价格'],aggfunc=[np.sum,np.mean],fill_value=0)
- 1

xs允许我向下钻取数据透视表的一个横截面。我们也可以向下钻取更多级别。
取得「销售总监」为「岳不群」的数据
data = pd.pivot_table(df,index=['销售总监','销售','产品'], values=['数量','价格'],aggfunc=[np.sum,np.mean],fill_value=0)
- 1
| 单一参数 | 多个参数 |
|---|---|
 |  |
xs中的level可以通过get_level_values来获得
例如,我们要查看所有销售总监:
查看所有销售:
试着按「销售总监」进行输出:
写入文件
import numpy as np
import pandas as pd
df = pd.read_csv('F:\\Temp\\datas\\xiaoshou.csv')
data = pd.pivot_table(df,index=['销售总监','销售','产品'], values=['数量','价格'],aggfunc=[np.sum,np.mean],fill_value=0)
writer = pd.ExcelWriter('F:\\Temp\\datas\\output.xlsx')
for name in data.index.get_level_values(0).unique():
temp_df = data.xs(name, level=0)
temp_df.to_excel(excel_writer=writer, sheet_name=name)
writer.save()

我们得到了一个由两个sheet页的Excel文件,sheet_name分别是销售总监「完颜洪烈」和「岳不群」。

















 3153
3153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









