






简单request对象爬取练习
#爬取百度首页的页面数据
import requests
if __name__ == "__main__":
#指定url
url = "https://www.baidu.com/"
#发起请求,成功之后会返回响应对象
response = requests.get(url=url)
#获取响应数据,用一个response对象去接收
#text返回的是字符串形式的响应数据
page_text = response.text
print(page_text)
#持久化存储
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print('爬取结束')
结果
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç¾åº¦ä¸ä¸ class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ°é»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å°å¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§é¢</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç»å½</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">ç»å½</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ´å¤äº§å</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å³äºç¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç¨ç¾åº¦åå¿è¯»</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æè§åé¦</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
RE模块正则匹配表达练习
content = '''
01 web安全的关键点1
02前端基础12
03前端黑客之xss 72
04前端黑客之csrf 83
05前端黑客之界面操作劫持97
06 漏洞挖掘123
07漏洞利用206
08 html5安全277
09 web蠕虫293
10关于防御336
'''
import re
pattern = re.compile(r'前端.*')#匹配所有前端字符,*的意思是后面是任意的字符,创建的patten相当于一个对象
print(pattern.findall(content))#pattern是一个列表类型,打印列表类型需要for循环
for line in pattern.findall(content):
print(line)
结果
"E:\Pycharm\SimpleRev\Learning Machine\Scripts\python.exe" "E:/Pycharm/Learning Machine/Re练习.py"
['前端基础12', '前端黑客之xss 72', '前端黑客之csrf 83', '前端黑客之界面操作劫持97']
前端基础12
前端黑客之xss 72
前端黑客之csrf 83
前端黑客之界面操作劫持97
Process finished with exit code 0
content = '''
01 web安全的关键点1
02前端基础12
03前端黑客之xss 72
04前端黑客之csrf 83
05前端黑客之界面操作劫持97
06 漏洞挖掘123
07漏洞利用206
08 html5安全277
09 web蠕虫293
10关于防御336
'''
#正则匹配
import re
#想要抓取章节号 \d:抓取数字 *代表哦抓取全部数字 ^表示从开头开始匹配
re.MULTILINE表示开启多行模式
patten = re.compile(r'^\w*' , re.MULTILINE)
for line in patten.findall(content):
#print(line)
结果
"E:\Pycharm\SimpleRev\Learning Machine\Scripts\python.exe" "E:/Pycharm/Learning Machine/Re练习.py"
01
02前端基础12
03前端黑客之xss
04前端黑客之csrf
05前端黑客之界面操作劫持97
06
07漏洞利用206
08
09
10关于防御336
Process finished with exit code 0
content1 = '''
aaaaabbbbb
aaaabbbb
aaabbb
aabb
a
'''
import re
#a*b*表示a出现任意次,b出现任意次 a*b+表示b必须出现至少一次
#a{3}b{3}$表示a出现3次b出现3次,从结尾开始匹配
patten = re.compile(r'a{3}b{3}$',re.MULTILINE)
for line in patten.findall(content1):
print(line)
结果
"E:\Pycharm\SimpleRev\Learning Machine\Scripts\python.exe" "E:/Pycharm/Learning Machine/Re练习.py"
aaabbb
Process finished with exit code 0
简单模拟登录注册
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
'referer': 'https://hgame.vidar.club/login'#从哪一个页面来的
}
def login():
data = {
'password': "991206wxyWXY",
'uid': "910196400@qq.com"
}
response = requests.get('https://hgame.vidar.club/api/user/sign-in',data=data,headers=headers)
print(response)
print(response.url)
#response.url查看最终请求的URL
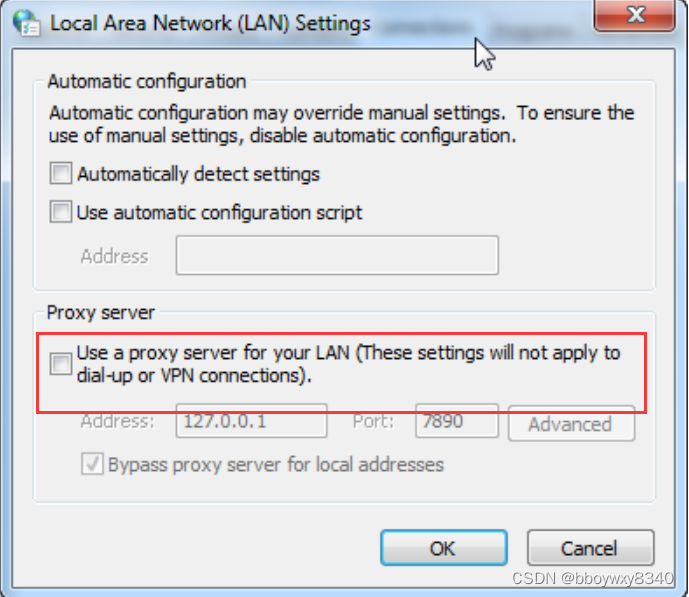
login()会出现requests.exceptions.ProxyError: HTTPSConnectionPool(host='hgame.vidar.club',目标主机拒绝连接问题
解决办法
Python requests.exceptions.ProxyError的解决办法
json数据表单

关掉















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









