






分布式SQL计算平台
Hive:将SQL语句翻译成MapReduce程序运行 分布式SQL计算的能力
{
用户只编写sql语句
Hive自动将sql转化为MapReduce程序并提交运行
处理位于HDFS上的结构化数据
}
需要:
1.元数据管理功能:SQL解析器
数据位置
数据结构
等对数据进行描述
2.SQL解析器:SQL分析,SQL到MapReduce程序转换,提交MapReduce程序运行并收集结果
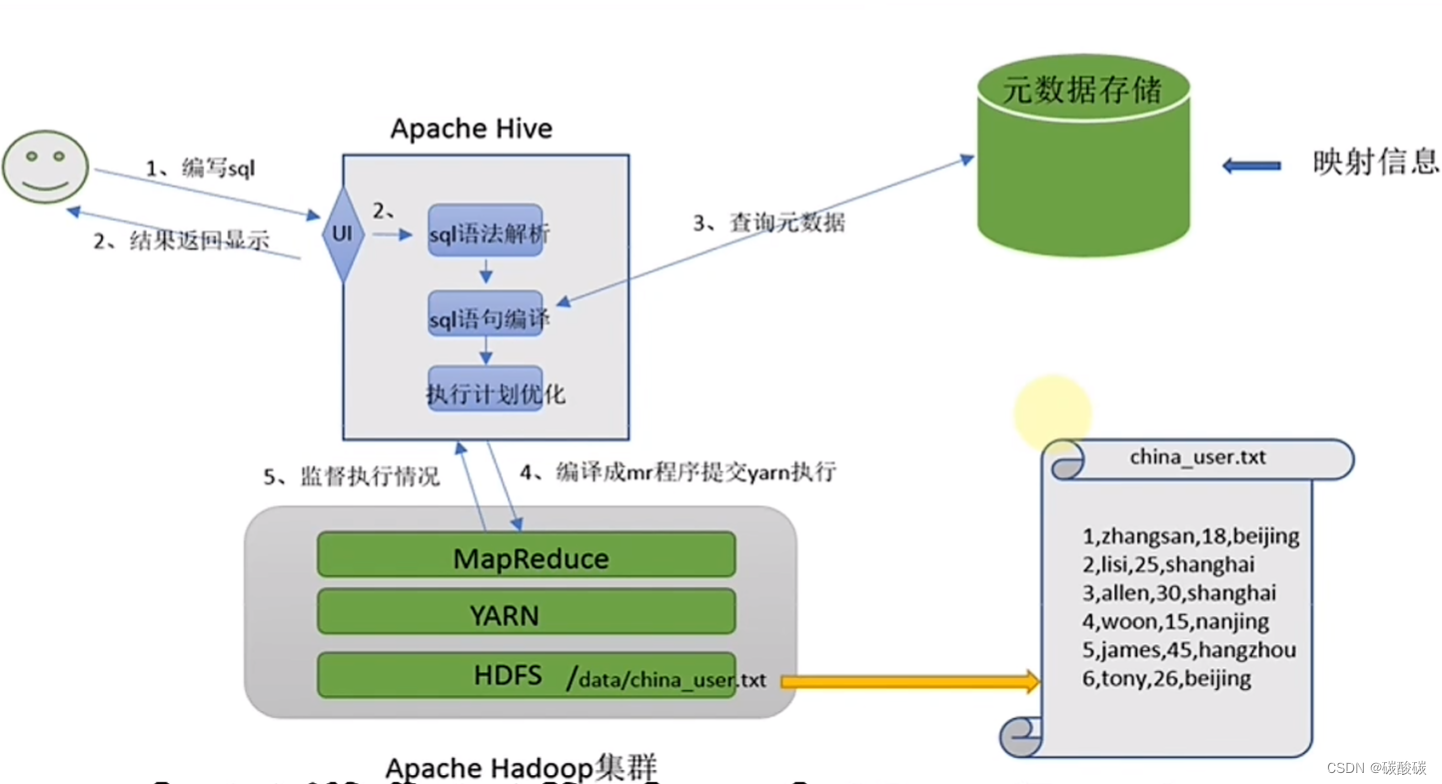
Hive基础架构
提供Metastore提供元数据管理功能
Driver驱动程序,包括语法解析器、计划编译器,优化器,执行器
用户接口
Hive部署
是单机工具,只需要部署在一台服务器中,可以提交分布式的MapReduce
需要部署:Hive本体,元数据服务需要的关系数据库(MySQL)
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
yum install -y mysql-community-server
systemctl start mysqld
systemctl enable mysqld
systemctl status mysqld
cat /var/log/mysqld.log | grep 'password'
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=4;
alter user 'root'@'localhost' identified by '12341234';
grant all privileges on *.* to root@"%" identified by '12341234' with grant option;
flush privileges;Hive 客户端

HiveServer2 & Beeline
启动hive的时候,除了必备的Metastore服务之外,还可以用HiveServer2
是一个内置的ThiftServer服务,提供Thift端口供其他客户端连接
SQL部分:
可以通过bin/hive直接写SQL用
也可以通过Beeline、DataGrip、DBeaver连接hiveserver2使用
#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
启动集群步骤和流程:
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
bin/hive
bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &启动Beeline
bin/beeline
! connect jdbc:hive2://node1:10000结果如下
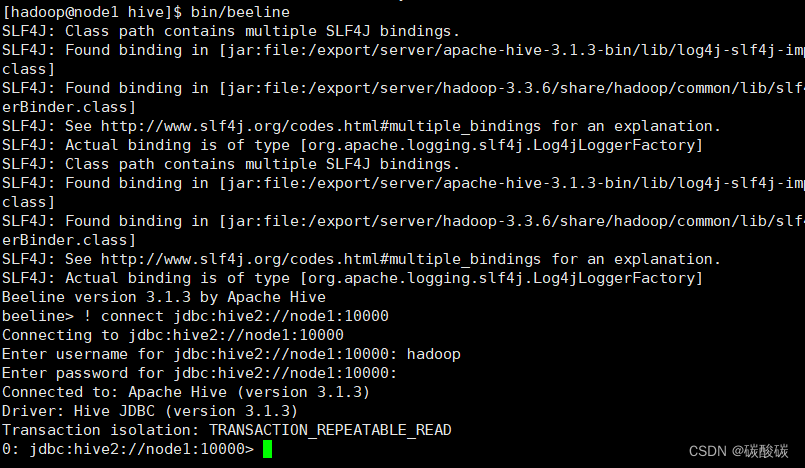
这样就可以执行SQL语句了,使用Beeline比直接启动bin/hive要方便,但是不可以直接启动,比较麻烦
DataGrip
第三方客户端连接到hive,图形化界面
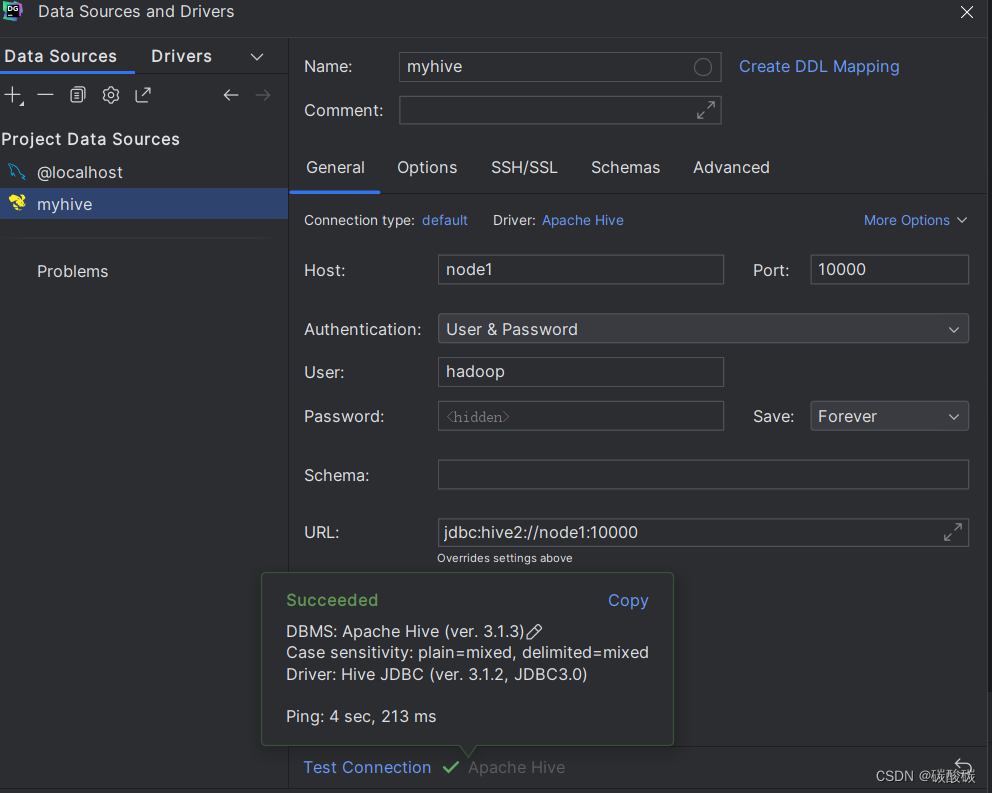
就可以以使用MySQl的方式使用Hive















 16
16











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









