






数据库操作
默认存储路径
desc database myhive;

指定存储路径
create database myhive2 location '/myhive2';![]()
额外的操作:
EXTERNAL,创建外部表
PARTITIONED BY,分区表
CLUSTERED BY 。分桶表
STORED AS,存储格式
LOCATION,存储位置
数据类型:
INT、DOUBLE、STRING、TIMESTAMP、DATA
string用的比varchar多
复杂类型:
ARRAY有序的同类型集合、MAP、STRUCT字段集合、UNION在有限的取值范围内的一个值
表分类
内部表、外部表、分区表、分桶表
内部表:create table
管理表,删除内部表会直接删除元数据(metadata)和存储数据
外部表 create external table location
数据位置不是固定的,删除的时候只删除表的信息,不删除数据本身
create table if not exists stu(
id int,
name string
);
insert into stu values (1,"zhangsan"),(2,"lisi"); -- 是mapreduce
select * from stu;其中插入操作是MapReduce操作,需要一段时间
默认存储在/user/hive/warehouse中

指定分隔符:
create table myhive.stu2(id int,name string) row format delimited fields terminated by '\t';在进行删除stu表之后 查看数据位置,发现数据也已经被删除

外部表:
仅删除元数据表信息,保留数据
创建外部表的时候,分隔符必须存在
create external table test_ext1(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext1'内部表和外部表的转换:
alter table stu set tblproperties('EXTERNAL'='TRUE');数据加载与导出
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] IN TABLE tablename;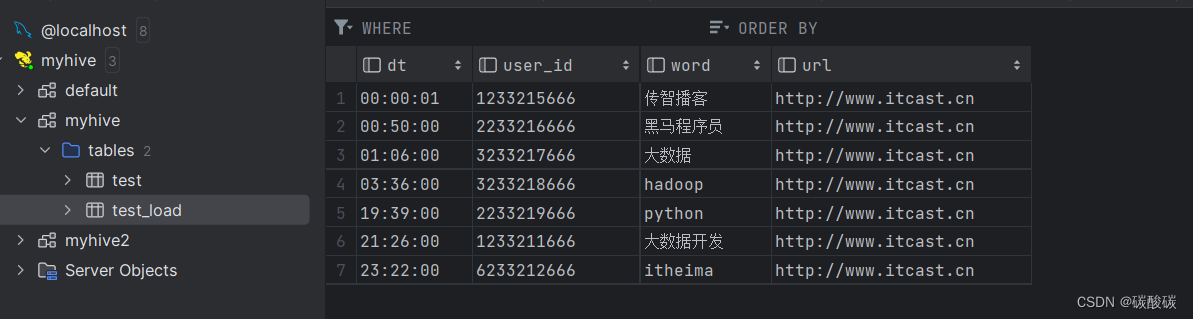
insert overwrite
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
数据导出:
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等
insert overwrite [local] directory ‘path’ select_statement1 FROM from_statement;hive shell
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
分区表
把大的数据划分成多个小分块,
基本语法:
create table tablename(...) partitioned by (分区列 列类型, ......)
row format delimited fields terminated by '';
可以选择字段作为表分区分区其实就是 HDFS 上的不同文件夹分区表可以极大的提高特定场景下 Hive 的操作性能
分桶表
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储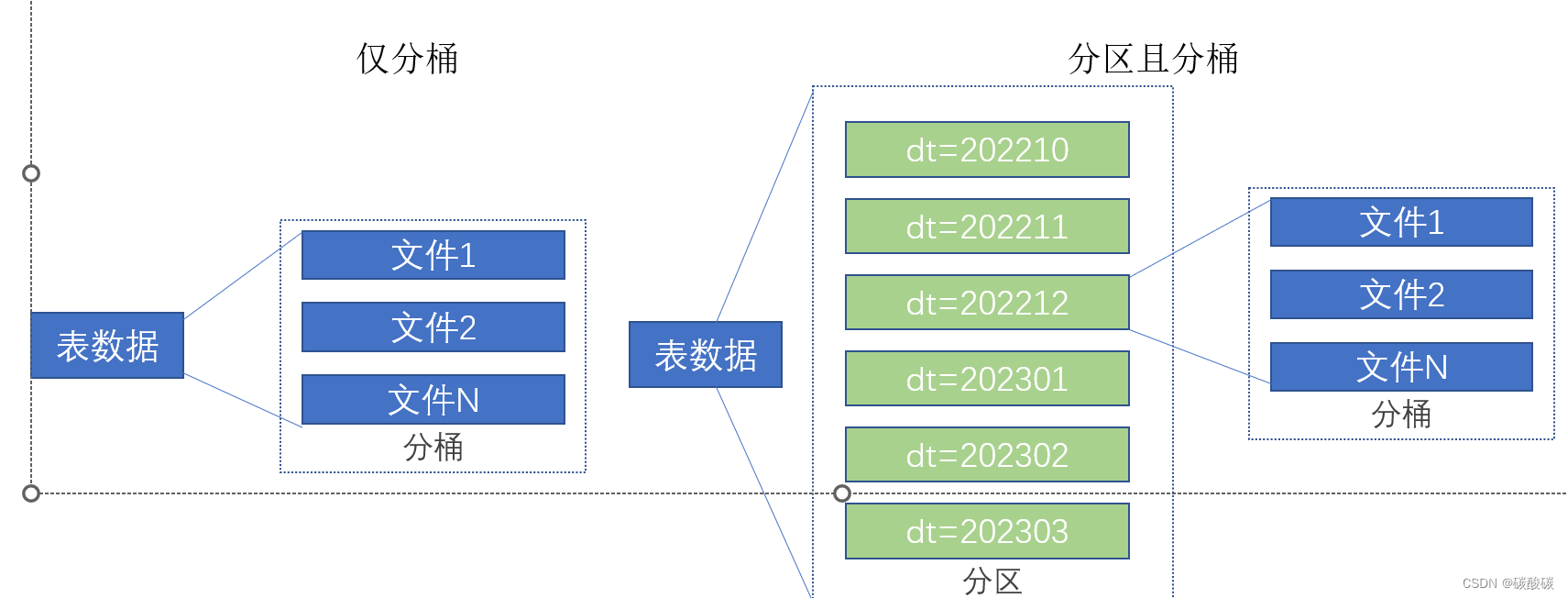
分桶表创建(开启分桶的自动优化,自动匹配reduce task数量和桶一致)
set hive.enforce.bucketing=true;
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
数据加载:
桶表的数据加载通过loaddata无法执行,只能通过insert select















 1399
1399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









