







ICLR2014
D.P. Kingma,M. Welling
一、简介
变分自编码器(VAE)以概率的方式描述潜在空间的分布。用编码器来描述每个潜在属性的概率分布。

如图,原始数据通过编码器生成一组其潜在属性的概率分布。潜在属性表示为可能值的范围(即概率)。这里的潜在属性实际上就是数据的特征。然后将这组潜在属性的概率分布通过解码器得到生成数据,这个生成数据和原始数据应该是同一个身份标签。
二、方法
假设给一个正态分布的潜在变量z就可以生成一张对应的图片。

上式中,后验概率是指我们只需要看到x就可以推断出z的特征。
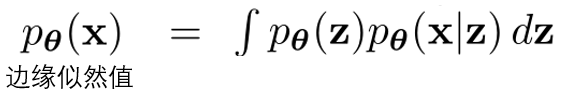
然而,计算边缘似然值是十分困难的。因为该式的积分求解是困难的,x通常是一个复杂的分布。
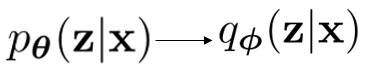
既然上述方式求解后验概率困难,那么我们使用变分推断来估计这个后验概率。使用q来近似p,我们将其定义为具有可伸缩的分布。
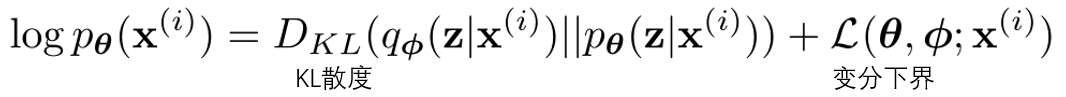
KL散度是两个概率分布的差值。想要p和q相似,可以最小化两个分布之间的KL散度。
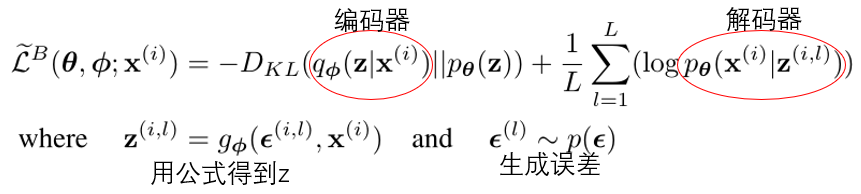
那么实际上训练就是最小化该式。
第一项是确保学习的后验分布q类似于真实的后验分布,这一项实际上也被称为正则化。
第二项是重构误差,即重构的数据的正确性。
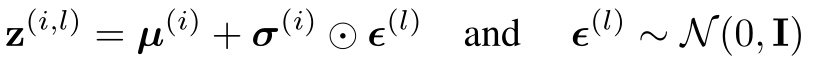
上式就是z的变换公式。
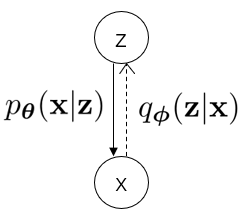
该图就是本方法的模型。其中,x到z是不存在的,只能近似的认为,所以我们用虚线表示。而z到x的过程是可以推导出来的。
三、举例

输入数据x,使用编码器得到输入数据x的潜在属性的均值和方差,然后通过z的变换公式变换得到潜在变量z。
潜在变量z通过解码器最终输出y。
这里的编码器和解码器都是神经网络组成的,都是可以进行梯度下降训练的。
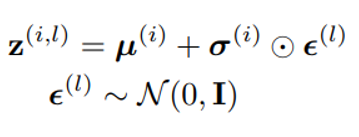
z=均值+方差×噪声。
这里的噪声是标准正态分布。
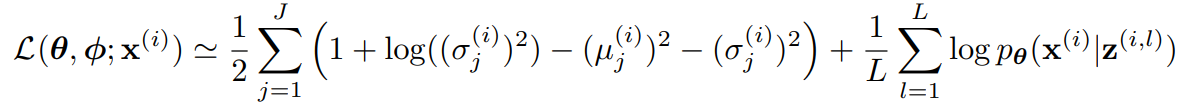
损失函数。第一项是KL散度损失,第二项是交叉熵损失。
四、实验

这是MNIST手写数字图像数据集在二维潜在空间的分布情况,可以看出同类在潜在空间上聚集在了一起。















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











