







CVPR2021
Aixuan Li,Jing Zhang,Yunqiu Lv,Bowen Liu,Tong Zhang,Yuchao Dai
https://arxiv.org/abs/2104.02628
一、简介
显著物体检测旨在发现吸引人类注意力的显著物体,而伪装物体检测则旨在发现隐藏在周围的伪装物体。
本文提出了一种利用矛盾信息来增强显著目标检测和伪装目标检测能力的方法。
提出了一种数据扩充策略,将伪装数据集中的简单样本作为显著性检测的困难样本,实现了一个鲁棒的显著性模型。
设计了相似性度量模块来显式地建模两个任务的“矛盾”属性。
在对抗式学习框架下引入第一个联合显著目标检测和伪装目标检测网络,明确建模每个任务的预测不确定性。
二、数据扩充

如图1所示,显著突出的物体和伪装的物体是矛盾的属性。但是也存在既突出又矛盾的对象,如图中的北极熊。
数据扩充可以为SOD框架带来性能上的增益,例如图像翻转、旋转、裁剪等,但是这些并不是专门为SOD任务设计的。SOD作为一项基于上下文的任务,更有效的数据扩充应该是上下文感知的。为此,我们利用COD数据集中的简单正样本作为SOD任务中的困难正样本,以提高SOD模型的鲁棒性。

从COD数据集中选择样本,用训练好的SOD模型计算其MAE,要求MAE最小。
我们选择400张最小MAE的COD数据集图像随机替代SOD数据集中的图像。
三、Contradicting modeling

使用相似测量模块来连接SOD和COD任务。相似性度量模块的基本假设是,用于两个任务的相同图像的激活区域应该不同,导致潜在特征是彼此分离的。
为此,将PASCAL VOC 2007数据集作为连接建模数据集Dp,这些额外图像实现相似性度量,并迫使这两个任务关注图像的不同区域。
。Dc是COD数据集,Ds是数据扩充后的SOD数据集。
对抗建模框架使用“特征编码模块”来提取伪装特征和显著特征,然后使用相似测量模块将两个任务与建模数据集连接起来。
3.1 Feature Encoder
使用两个相同backbone结构的显著性编码器Eαs和伪装编码器Eαc。α表示参数。
使用ResNet50作为backbone,通道为[256, 512, 1024, 2048]。其输出特征用F={f1,f2,f3,f4}表示。
3.2 Similarity measure
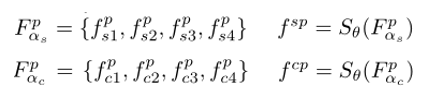
将Fs和Fc中的四个特征两两拼接送到同一个全连接层中,得到显著性潜在特征和伪装潜在特征。维度为700。
我们假定SOD和COD应该关注不同的区域,从而导致不同的特征表示。
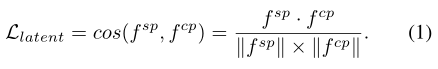
我们选择余弦相似性来测量,潜在空间下,显著性特征和伪装特征的不同。

Figure4展示了来自显著性编码器(第一行)和伪装编码器(第二行)的同一图像的激活区域(经处理的预测)。具体来说,给定相同的图像Xp,我们计算它的伪装图和显著图,并用红色突出显示检测到的前景区域。图4显示,两个编码器聚焦于图像的不同区域,其中显著性编码器更关注从上下文中突出的区域,伪装编码器更关注与背景颜色或结构相似的隐藏对象,这与我们假设这两个任务在总体上相互矛盾是一致的。
四、Uncertainty-aware adversarial learning

如Figure5,对于SOD数据集,不确定性来源于显著性的模糊性。例如a和b,红色框的球是突出的,但是他在背景中。
对于COD数据集,不确定性来源于标注的困难性。例如c和d,橙色区域是伪装对象,但是他与背景过于相似,很难创建准确的注释。
为此,我们引入了一种不确定性感知的对抗性训练策略,在我们的联合学习框架中对特定任务的不确定性进行建模,该框架包括一个“预测解码器”模块来产生与任务相关的预测,一个“置信度估计”模块来估计每个预测的不确定性,以及一个用于鲁棒模型训练的对抗性学习策略。
4.1 Prediction decoder
我们设计了一个共享解码器结构。我们认为,不同的“特征编码器”模块可以为SOD图像和COD图像生成特定任务的特征。然后,“预测解码器”模块旨在将任务特定特征与它们相应的较低级别特征相结合以产生预测。
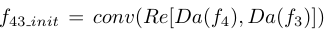
Re是residual channel attention module,它有利于提取更好的特征。
Da是dual attention module,它能够有效地将较高层语义信息与较低层结构信息融合。
conv是3×3的卷积,输出通道数是32。[]是拼接操作。
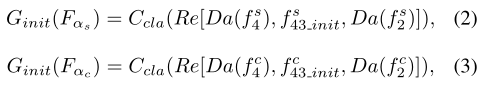
Ccla是3×3的卷积,它为每个任务将特征映射到一个通道预测。
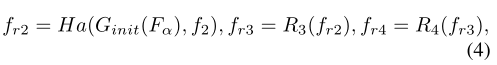
R3和R4是ResNet50的第三阶段和第四阶段。
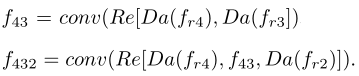
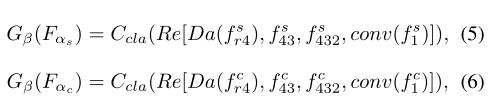
公式(5)和(6)就是最终的预测解码器结构。
4.2 Confidence Estimation
引入置信度估计模块来对网络预测的置信度建模。
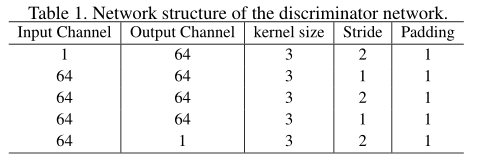
设计了一个完全卷积鉴别器网络D,结构如Table1。
该网络旨在产生与ground truth相同的输出。
4.3 Adversarial Learning
structure-aware loss:

为学习特定任务设计的。
w是边缘感知权重。Lce是交叉熵损失。Liou是边界IOU损失。
adversarial loss:
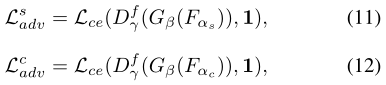
对抗学习,鉴别器以模型预测为输入,试图将其识别为ground truth。
1是都是1的矩阵。
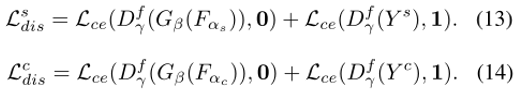
对于置信度估计模块,我们希望它能清晰地区分模型预测和ground truth。
4.4 Objective Function
给定输入连接建模数据集Dp,COD数据集Dc,数据扩充后的SOD数据集Ds。先使用3.2中的公式(1)学习特征编码器和相似性测量模块。
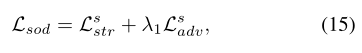
然后我们训练显著性生成器分支(显著性编码器和预测解码器)的对抗性学习。损失函数如公式(15)。λ1=0.01。
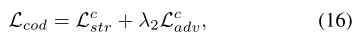
类似地,我们为伪装生成器分支(伪装编码器和预测解码器)训练具有损失函数的对抗学习。损失函数如公式(16)。λ2=0.01。
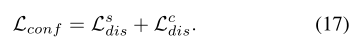
然后我们用公式(16)训练置信度估计模块。

五、实验
对于显著目标检测,我们使用增强的DUTS训练数据集训练我们的模型;对于伪装物体检测,我们使用COD10K训练集训练我们的模型。
编码器使用在ImageNet数据集上训练的ResNet50模型。图片大小为352×352,最大迭代次数为36000。迭代更新三次显著性分支和一次伪装分支。初始学习率为2.5e-5,我们采用“步长”学习率衰减策略,将衰减步长设置为24000次迭代,衰减率为0.1。
5.1 SOD实验

表2显示,除了在SOC测试数据集上,我们实现了5/6的最佳性能。主要原因是在足球比赛中存在纹理图像,这些图像可能被当作伪装的物体,从而影响我们的表现。

在图6中显示了我们和SOTA模型的预测,其中“不确定性”是基于来自鉴别器的预测获得的。具体来说,我们将鉴别器输出的梯度大小定义为不确定性。图6显示了我们产生了准确的预测和合理的不确定性估计,其中不确定性图的较亮区域表示较不确定的区域。
5.2 COD实验


生成的不确定性图清楚地表示了模型对当前预测的信心,从而导致了可解释的预测。
















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











