







目录
Abstract
在过去的十年中,专用图形处理单元 (GPU) 已成为高性能计算工作负载的架构。最近,研究人员还关注专用 GPU 的隔离特性,并提出了基于 GPU 的安全计算环境以及一些有前景的应用。然而,尽管之前的研究进行了安全分析,但尚不清楚在存在内核特权攻击者的情况下是否可以将专用 GPU 用作安全处理器。在本文中,我们首先通过对 GPU 执行上下文信息的综合研究来证明专用 GPU 的安全性。该论文表明,具有内核特权的攻击者可以操纵 GPU 上下文来重定向内存访问或在运行的 GPU 内核上执行任意 GPU 代码。基于安全分析,本文提出了一种新的专用GPU片上执行模型以及支持片上执行安全的新型防御机制。通过全面评估,本文确保所提出的解决方案能够有效隔离片上存储中的敏感数据,并防御来自特权攻击者的已知攻击向量,支持商用 GPU 可以用作安全处理器。
ITRODUCTION
图像处理单元 (GPU) 最初是为图形数据处理而设计的,但现在 GPU 上的通用计算 (GPGPU) 允许利用 GPU 的并行计算能力进行高性能和数据密集型计算。密码学 [1]、[2]、[3]、[4] 和深度学习 [5]、[6] 等各种应用已在专用 GPU 上进行了加速,以提供更好的性能。由于安全敏感的应用程序利用 GPU 计算,GPU 执行的安全性变得至关重要。为了支持 GPU 上的可信执行环境,引入了 GPU 架构更改 [7] 或 Intel SGX 和 PCI Express (PCIE) [8] 扩展的方法。此类方法能够提供独立的 GPU 执行,但需要大量的硬件修改,而这些修改目前不适用于商用 GPU 和系统。
为了在商用 GPU 上安全地处理特定安全应用程序的工作负载,研究人员开始关注专用 GPU 中片上存储的隔离特性。 PixelVault [9] 和 OBMI [10] 提出了一种密钥隔离机制,以安全地隔离 GPU 片上存储中的加密密钥。 GPU安全发起加密操作后,攻击者无法检索密钥,即使具有内核特权。 GRIM [11] 使用专用 GPU 实现内核完整性监视器,并检测内核对象的恶意修改。最近探索用于安全目的的专用 GPU 的研究表明,它们在安全性和性能方面都超越了现有方法的优势:(i) 它们不依赖于安全的虚拟机管理程序或操作系统 (OS),并且 (ii) 它们支持高性能利用专用 GPU 核心和内存进行计算。
然而,之前基于GPU的安全解决方案[9]、[10]、[11]对其安全假设有严重的限制,因为底层安全分析是在有限的资源和接口上进行的。他们只关注统一计算设备架构 (CUDA) 应用程序编程接口 (API) 等公共编程接口以及由程序员显式生成的 GPU 代码和数据等程序资源。除了这些资源之外,GPU还有一些隐藏资源,例如页表和控制寄存器,但之前基于GPU的解决方案并没有解决这些资源的安全问题。
本文首先研究了专用 GPU 中 GPU 上下文操作的潜在威胁,并展示了即使使用现有的基于 GPU 的解决方案,运行的 GPU 内核也会面临现实威胁。最近,研究人员利用控制寄存器和最新调试器的更新功能 [12] 表明,PixelVault [9] 的安全假设存在不良漏洞。在本文中,通过在最新的 GPU 架构上添加进一步的逆向工程工作,我们表明更通用和更强大的攻击是可能的,这些攻击允许攻击者将任何地址或控制流重定向到任意数据或代码。
针对上下文操作带来的威胁,本文提出了一种新颖的片上执行模型,该模型在设备内存中没有任何关键的上下文信息。片上执行上下文仅驻留在 GPU 片上存储中,例如转换后备缓冲区 (TLB)、寄存器和高速缓存。与之前的片上执行模型[9]、[10]、[11]不同,GPU设备内存中的关键上下文信息被清零。新的片上执行模型称为 ZEROKERNEL,可防止依赖设备内存中上下文信息的攻击导致任何片上数据泄漏。
然而,即使从设备内存中消除了关键的 GPU 内核上下文,潜在的漏洞仍然存在。具有内核权限的攻击者可以恶意地在设备内存中重建任意 GPU 上下文。然后,可以通过重新加载 TLB 和指令缓存(I-Cache)将 GPU 内核执行重定向到注入的代码。为了防止通过上下文重建进行此类攻击,ZEROKERNEL 提出了两种额外的防御技术; 1) 页表内存位置的随机化,以及 2) 通过专用监视线程的连续值监视来检测页表基地址。通过这两种防御技术,恶意上下文重建变得极其难以部署,并且被检测到的机会非常高。
通过全面的评估,我们验证了 ZEROKERNEL 能够为轻量级任务提供安全的 GPU 执行,其中关键 GPU 上下文适合 GPU 片上存储的容量。 ZEROKERNEL 可防御所有现有的攻击向量,同时性能下降相对较小。在我们的方法中,不需要修改硬件或 GPU 驱动程序,并且它独立于额外的硬件抽象层(例如管理程序或微内核)。我们论文的主要贡献如下。
Contributions
我们执行逆向工程任务来找出与 GPU 上下文相关的内部机制,并根据研究结果提出针对专用 GPU 的新攻击方法。
我们提出了 ZEROKERNEL,这是一种新的片上执行模型,无需在设备内存中存储任何关键上下文信息。任何通过利用设备内存中的关键上下文来访问秘密的尝试都会被破坏。
我们提出了一种专为 ZEROKERNEL 设计的新颖防御机制,可防止 CPU 驻留攻击者进行恶意上下文重建。即使在 CPU 端特权攻击下,它也可以保持 ZEROKERNEL 的短暂性。
BACKGROUND
Secure Execution on Dedicated GPUs
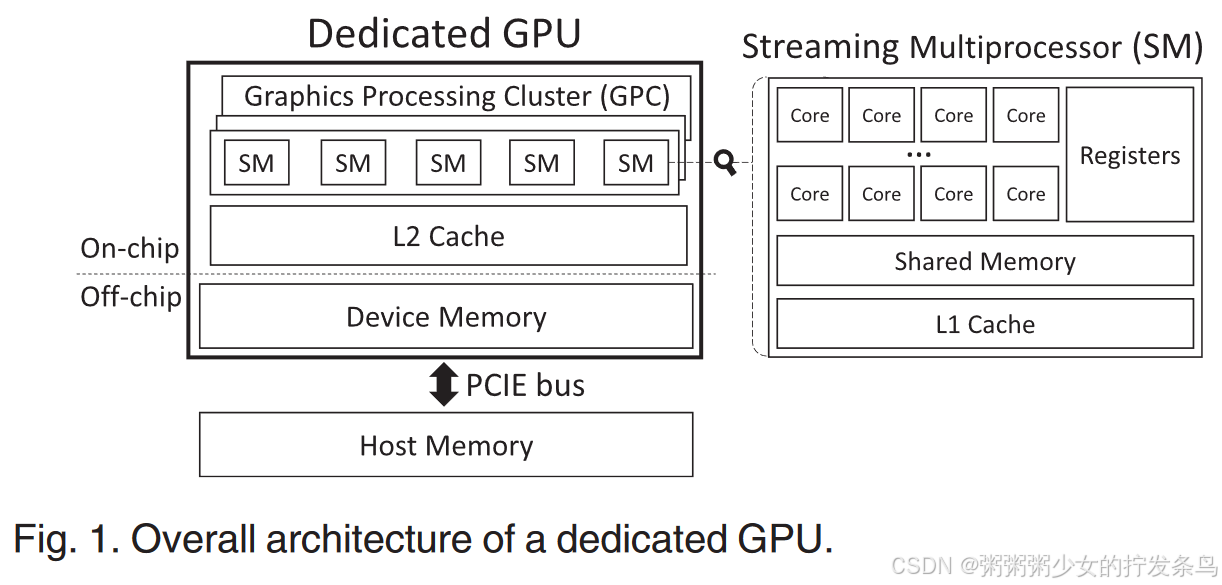
专用GPU的总体架构如图1所示。专用GPU通过PCIE插槽连接到主板,其直接内存访问(DMA)引擎可以访问主机内存而无需CPU的干预。图1中,专用 GPU 包括由 5 个流式多处理器 (SM) 组成的多个图形处理集群 (GPC)。在每个SM中,多个线程在其所有核心上执行相同的指令,并且被调度在一起的线程单元称为warp。有一个专用的设备内存,它是 GPU 的主内存。在 GPU 内核执行之前,GPU 代码和数据会加载到设备内存上。利用缓存和寄存器来减少设备内存访问的延迟。先前的安全 GPU 执行方法 [9]、[10]、[11] 利用 GPU 的缓存和寄存器来安全地将敏感数据和代码与内核特权攻击者隔离。
研究人员提出了在存在内核特权攻击者的情况下在这种专用 GPU 上执行安全任务的安全计算环境 [9]、[10]、[11]。 PixelVault [9] 和 OBMI [10] 支持安全加密操作。 GRIM [11] 是一个基于快照的内核完整性监视器,它利用 GPU 的 DMA 引擎。它们的安全保证基于专用 GPU 的片上存储,具有内核特权的攻击者无法直接访问该存储。 GPU代码上传后仅在ICache中执行。敏感数据被上传到寄存器[9]、[11]或常量数据缓存(C-Cache)[10]中。敏感数据以加密方式驻留在设备内存中或被删除。之前的工作[9]、[10]、[11]声称攻击者只能终止安全隔离的GPU内核,但不能修改GPU代码或泄露敏感数据。
最近,朱等人。 [12]针对PixelVault进行攻击,并对专用GPU上的安全计算提出质疑。他们发现了隐藏的 MMIO 命令,该命令使 I-Cache 中的所有代码无效,并表明具有内核特权的攻击者可以使用附加的调试器读取正在运行的 GPU 内核的寄存器值。在本文中,我们研究了控制正在运行的 GPU 内核的更通用方法,并表明具有内核特权的攻击者可以操纵 GPU 上下文来重定向内存访问或执行任意 GPU 代码。
为了保护 GPU 执行免受特权攻击者的攻击,最近的研究工作 [7]、[8] 提出了基于硬件的解决方案。通过将GPU上下文管理卸载到GPU的命令处理器并保护GPU通过 GPU PCIE 引擎,Graviton [7] 提供安全的 GPU 上下文隔离。此外,在不改变 GPU 架构的情况下,HIX [8] 扩展了 Intel SGX 和 PCIE 基础设施的功能,以允许 enclave 独占 GPU MMIO 访问。这两种解决方案都可以提供安全的GPU执行,而不限制GPU任务的执行。然而,它们需要对 GPU、系统架构和软件堆栈进行重大的硬件和软件更改。本文提出了一种新的安全执行模型ZEROKERNEL,用于安全目的的轻量级任务,无需修改包括GPU和GPU驱动程序软件在内的任何硬件。
Threat Model and Assumption
我们使用与之前基于 GPU 的安全解决方案相同的威胁模型 [9]、[10]、[11],并假设攻击者具有内核权限。这样,攻击者就可以自由访问为GPU控制寄存器保留的MMIO空间以及GPU内核上下文所在的设备内存。此外,攻击者还可以修改CUDA API和GPU驱动程序,从而改变GPU的管理,例如GPU内核的初始化。
为了安全地初始化 GPU 内核,之前基于 GPU 的安全解决方案在 GPU 内核初始化期间假设安全启动 [9]、[11],或者建议利用 CPU 的系统管理模式(SMM)进行安全启动过程验证 GPU 状态 [10]。在上述所有解决方案中,GPU代码和敏感数据被隔离在GPU缓存或寄存器内,并且初始化的GPU内核独占GPU设备。我们还假设在安全初始化期间所有 SM 都分配给单个 GPU 内核,并且单个 GPU 内核持续运行。
GPU CONTEXT ANALYSIS
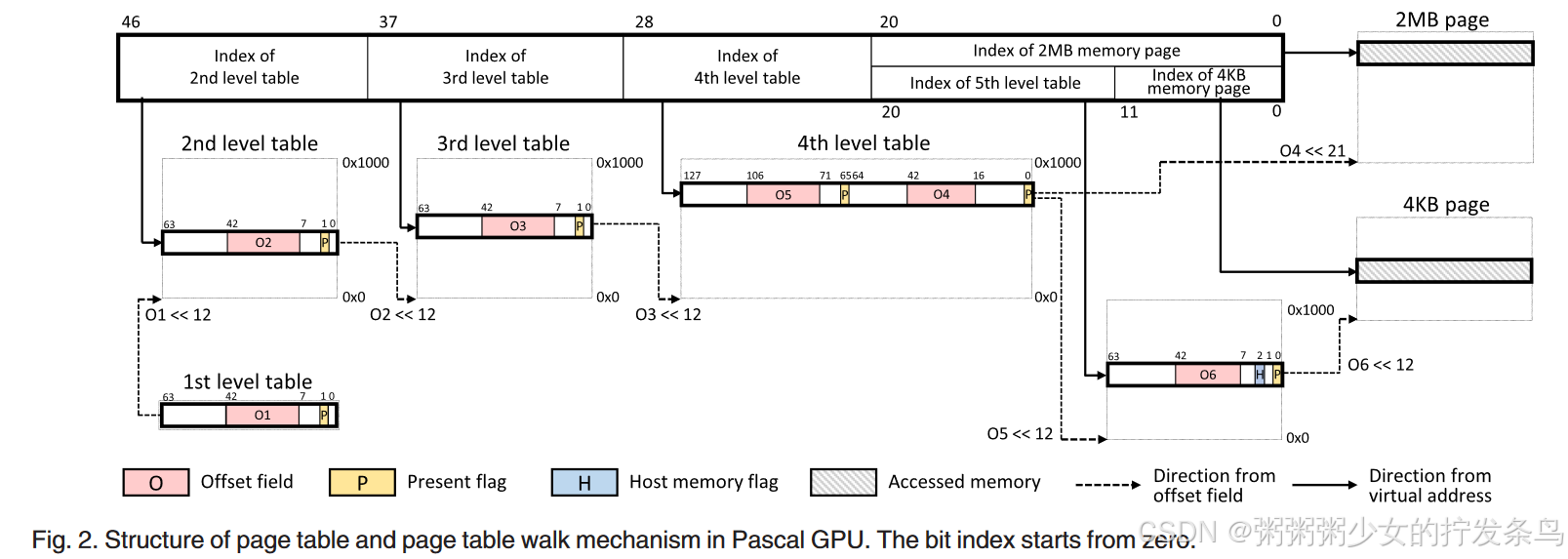
GPU Page Table
Structure of Page Table
Page Table Manipulation
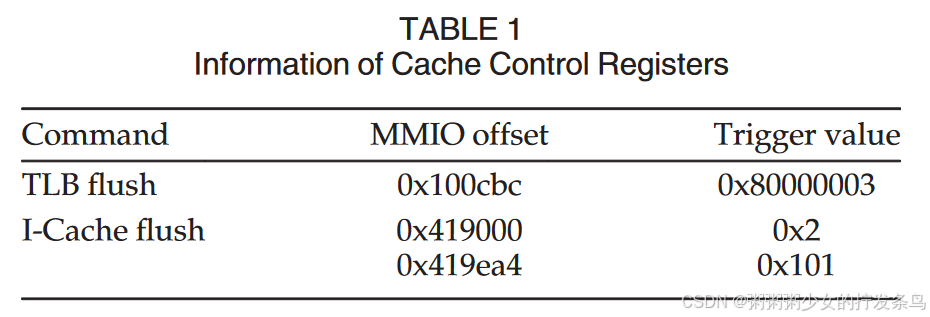
Context Update Command
GPU CONTEXT MANIPULATION
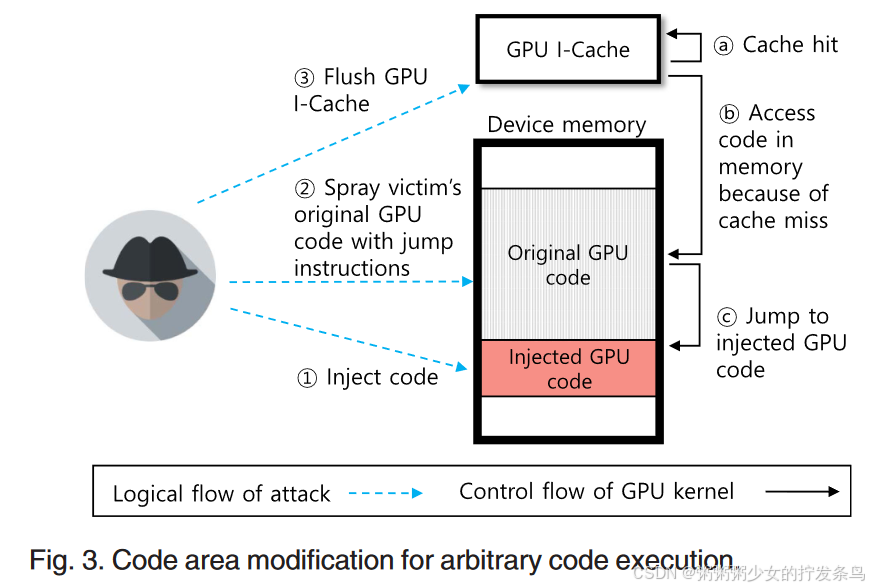
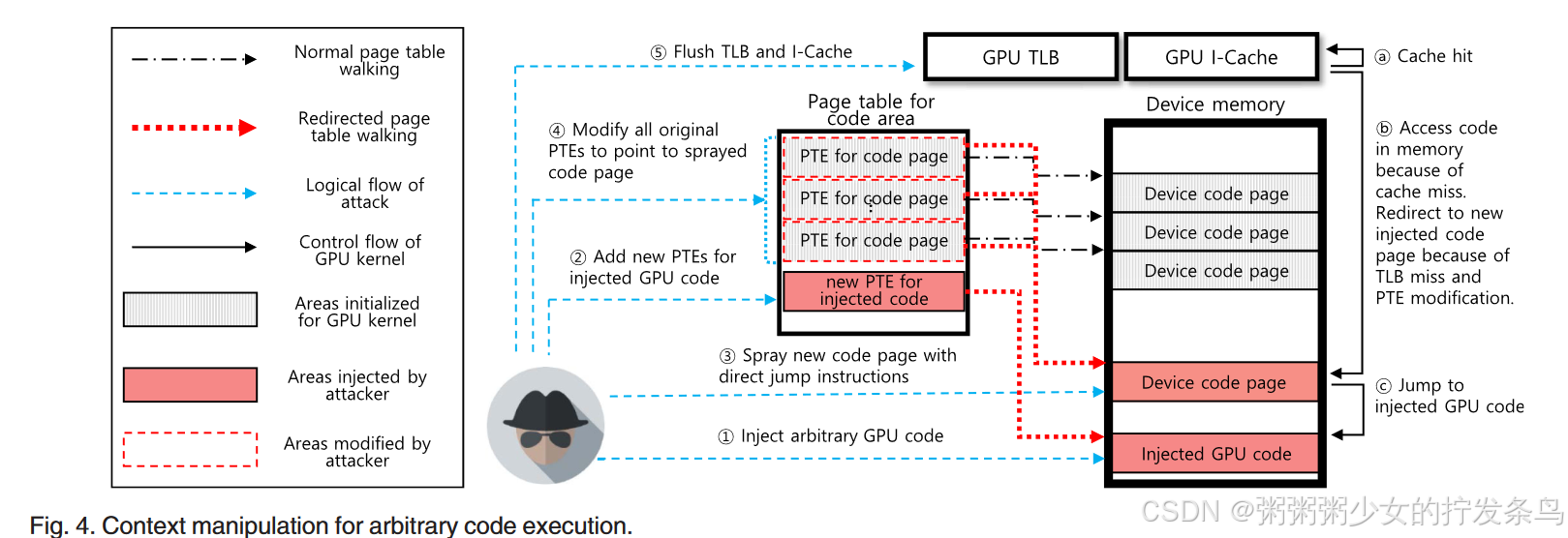
Access Redirection
Arbitrary Code Execution
Attacks on GPU-Based Systems
Key Leakage against Secure Cryptographic Operation
Bypass of Kernel Integrity Monitor
Malfunction of Deep Learning Computation
ZEROKERNEL DESIGN
本节介绍 ZEROKERNEL,它为 GPU 上下文适合片上存储的轻量级任务提供安全的 GPU 执行。 ZEROKERNEL 不仅包括安全设计的 GPU 内核,还包括支持防御机制,以防止 GPU 内核引导后出现任何安全漏洞。
Overview
商用 GPU 上安全执行的基本要求是隔离 GPU 内不可访问的片上存储上的关键上下文,这也是最近提案[9]、[10]、[11]对其安全保证的要求。然而,正如我们在上一节中所描述的,即使具有片上隔离,特权攻击者也能够操纵受害 GPU 内核的上下文。
基于我们对 GPU 内核执行和底层 GPU 架构的逆向工程工作,我们总结了商用 GPU 上安全执行的必要条件如下。
无法访问的片上存储上的上下文隔离:关键秘密和内核上下文必须驻留在片上寄存器、缓存和 TLB 中。
上下文隐藏执行:必须从设备内存中清除任何上下文信息。
不可篡改的内核代码:一旦在安全引导期间将代码加载到 ICache 中,该代码就不能被篡改。
GPU页表的保护:从设备内存中删除上下文后,不得重建GPU页表来操作上下文。
安全终止GPU内核:一旦检测到攻击,必须立即终止GPU内核,不留下任何秘密。
无限执行:引导安全 GPU 执行后,GPU 内核必须连续运行才能安全终止。
满足上述所有条件的ZEROKERNEL可以阻碍攻击者的上下文操纵尝试,并防止片上存储中处理的敏感数据泄露。在本节中,我们将详细描述每个条件。
Isolation of Contexts on Inaccessible On-Chip Storages
Context-hidden Execution on Commodity GPUs
Untampered GPU Kernel Code
Protection of the GPU Page Table
Safe Termination
Infinite Execution
EVALUATION
Implementation
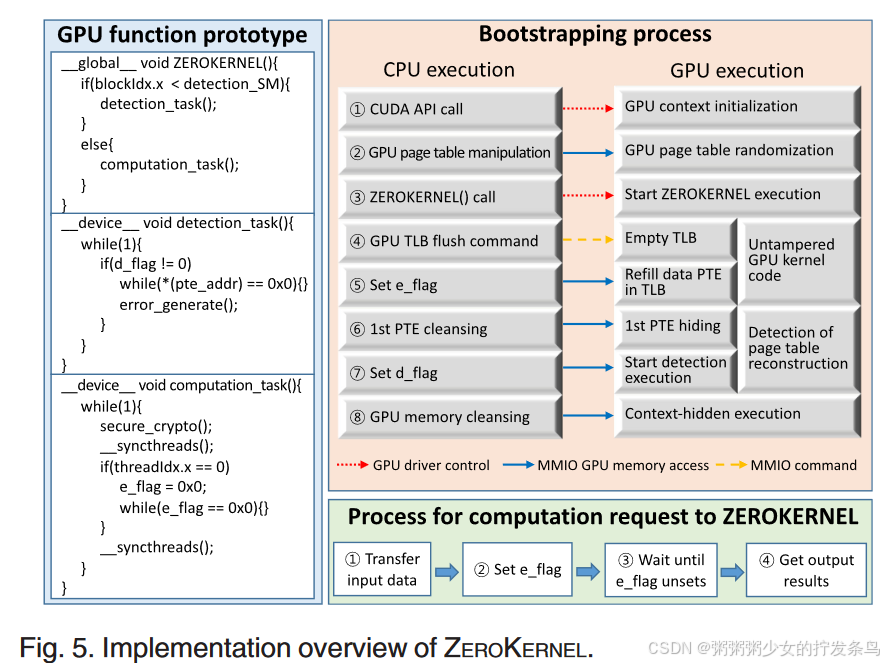
Security Analysis
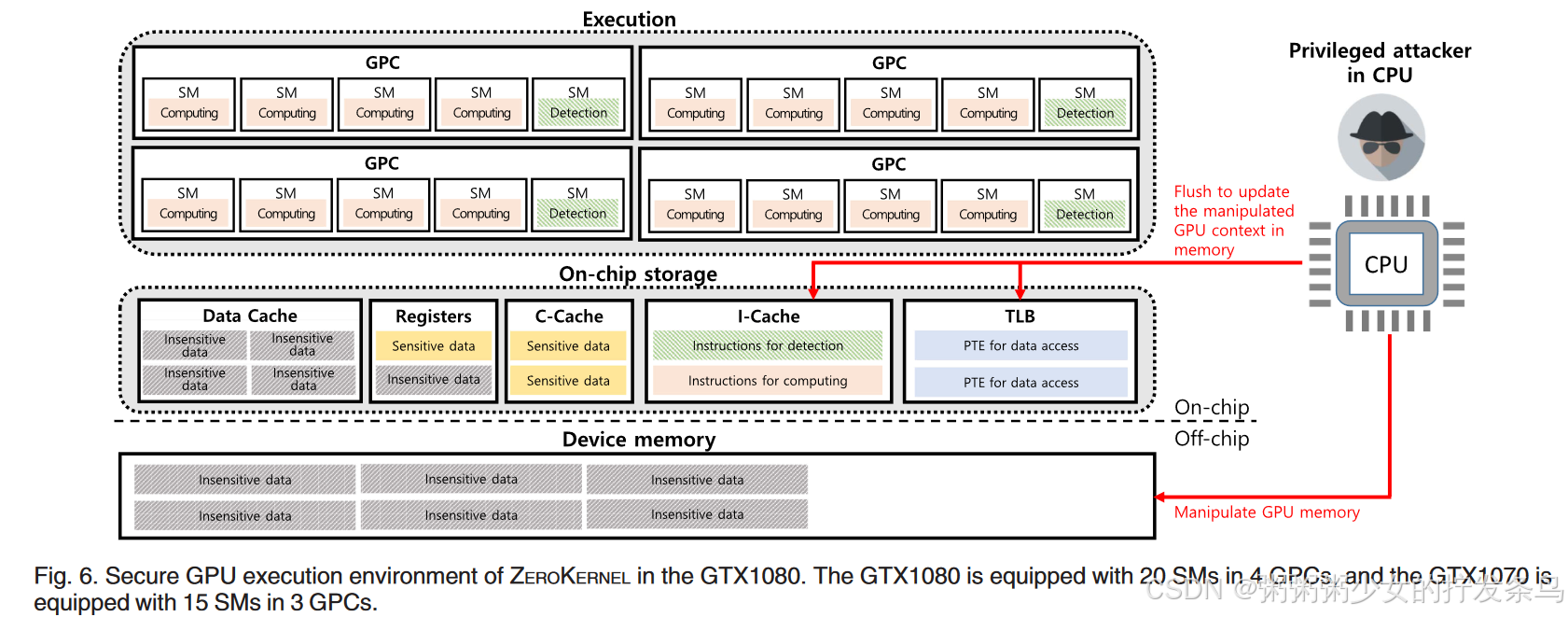
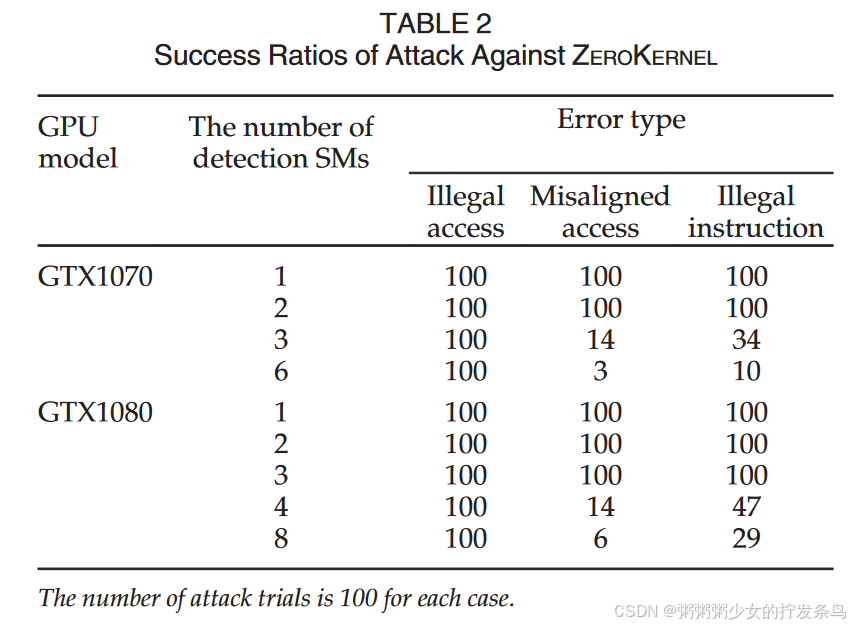
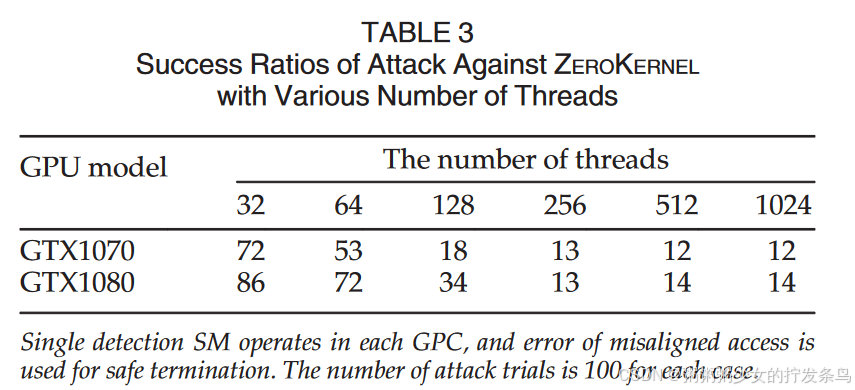
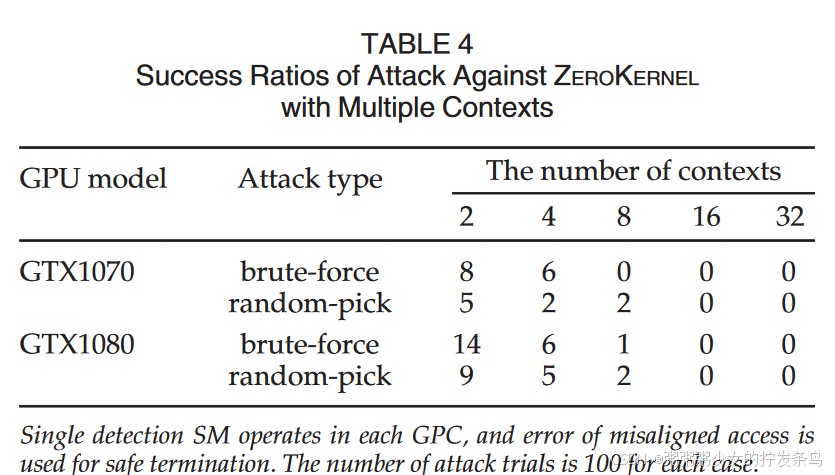
On-Chip Capacity for Context Isolation
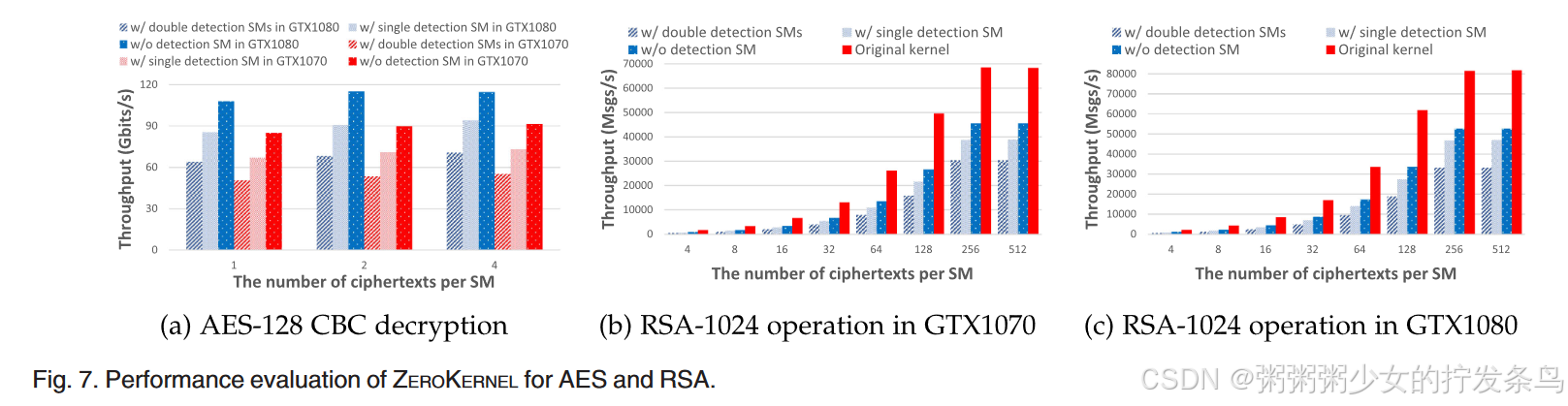
Performance Evaluation
RELATED WORK
Reverse-Engineering on GPU
Nvidia 发布了一些与其专用 GPU 相关的文档和参考文献 [14]、[15]、[16]、[30]、[31]、[32]。然而,他们只关注高层概念。正因为如此,人们付出了很多努力来发现 GPU 的隐藏功能。例如,有研究找出GPU中的微架构[27]、内存请求处理方法[33]、[34]和内存层次结构[23]。此外,一些作品试图揭示GPU的MMIO空间[26]、[35]。对 Nvidia 的闭源驱动程序进行逆向工程也做出了许多努力 [24]、[25]、[36]。在本文中,我们研究了能够控制正在运行的 GPU 内核的资源。通过对资源的分析,我们揭示了一些可被恶意利用的GPU内部机制。
Security of GPU
随着GPU被用于越来越多的计算应用中,最近的一些研究工作集中在GPU的安全性上。 GPU内核终止后,设备内存和共享内存中的内容仍然保留,因此攻击者可以利用剩余数据推断有用信息[21],[22],[37]。为了防止 GPU 处理的数据泄露,Hayes 等人。 [38]提出了一种 GPU 上的污点跟踪系统。莫里斯等人。 [20]处理了虚拟化环境中与 GPU 相关的安全问题,并表明可以通过 MMIO 空间恶意访问设备内存。此外,GPU代码中的缓冲区溢出漏洞已经被研究[39]、[40]、[41],最近的工作[42]、[43]、[44]已经证明了在GPU代码中存在侧通道和隐蔽通道。 GPU。在本文中,我们介绍了 GPU 上下文操作的新漏洞,该漏洞在之前的研究中尚未考虑到。
On-Chip Execution in CPU
为了构建安全的计算环境,之前的一些工作利用了CPU的寄存器[45]、[46]、[47]或缓存[48]、[49]。此外,最近的一项研究 [50] 提出了一种利用 Intel CPU 中事务同步扩展 (TSX) 原子性特征的解决方案。在上述先前的工作中,敏感数据仅在CPU的片上存储中进行处理,并免受一些内存泄露攻击,例如冷启动攻击[51]和总线窥探攻击[52]。这些工作假设操作系统的完整性得到保证,因为修改或注入的操作系统二进制文件可以在CPU中执行任何操作。然而,操作系统的完整性可以通过复杂的 DMA 攻击 [53] 进行修改或由特权攻击者注入可加载内核模块(LKM)来破坏。最近的工作 [54] 利用缓存和 ARM TrustZone [55] 来保护安全应用程序免受冷启动攻击和操作系统受损。
DSCUSSION
尽管我们证明了我们的安全 GPU 执行模型可以防御来自 CPU 驻留特权攻击者的 GPU 上下文操纵,但其安全性的形式验证需要进一步澄清专用 GPU 的未知行为。在本节中,我们讨论可能的攻击,并检查是否有可能颠覆 ZEROKERNEL 执行。此外,我们还讨论了 ZEROKERNEL 的局限性以及如何扩展其功能。
Hidden Resources on Device Memory
在本文中,我们分析了位于设备内存中的隐藏 GPU 上下文,并揭示了可被恶意攻击者利用的 GPU 页表的详细信息。除了页表之外,设备内存中的其他关键资源可能会为基于 GPU 的安全执行模型带来额外的攻击向量。为了检查可能影响 GPU 内核片上执行的资源,我们在启动 GPU 内核后用零覆盖整个 GPU 设备内存。然而,即使设备内存全部填零,GPU 片上执行也不会出现错误。此结果表明 ZEROKERNEL 可以隐藏设备内存中的任何易受攻击的资源,并且对设备内存的操作不足以发现新的攻击向量。此外,即使设备内存中存在其他关键资源,ZEROKERNEL中的检测SM也可以监控该资源所在的设备内存区域。
Hidden Control Registers of GPU
可能存在利用其他 GPU 控制寄存器的其他攻击向量。例如,虽然可能性很小,但如果存在控制寄存器,可以暂停 GPU 内核的执行而不终止它,并在操作设备内存后恢复暂停的 GPU 执行而没有任何致命异常,则攻击者可能能够触发执行注入的 GPU 上下文,同时绕过 ZEROKERNEL 的检测。另一个关键的攻击渠道是直接操纵正在运行的 GPU 内核的页表基地址。如果攻击者能够通过控制寄存器对其进行修改,则攻击者可以在设备内存中的任何位置注入新的页表。然而,据我们所知,任何研究人员或逆向工程社区都没有发现这样的控制寄存器。此外,通过 GPU 的小幅更新(例如固件更新)就可以轻松防止此类攻击。我们可以确保固件不会被恶意攻击者更改,因为自 Maxwell 架构以来 GPU 固件的验证是可能的[56]。
GPU Side Channel Attack
之前的几项研究最近提出了针对 GPU 的侧通道攻击。例如,论文[42]表明,通过采样百万条痕迹可以完全泄露AES密钥。这种定时攻击还可用于破坏 ZEROKERNEL 中的加密操作。然而,目前GPU侧通道攻击的研究主要针对AES(ECB)的特定模式,并不普遍适用于其他实现。最近的另一篇论文[44]表明,在多个 GPU 内核并发执行期间,另一个间谍 GPU 内核可能会泄露受害 GPU 内核的信息。然而,如果攻击者在ZEROKERNEL执行期间启动另一个GPU内核,则ZEROKERNEL将立即终止,因为ZEROKERNEL用于上下文切换的信息在引导时已经在设备内存中被擦除。
Limitations
与通用 GPU 内核执行环境相比,由于第 5 节中介绍的要求,ZEROKERNEL 支持有限的执行。主要原因是一旦 ZEROKERNEL 启动,它必须仅在片上隔离上下文的情况下连续运行。因此,它无法支持上下文超出片上容量的复杂任务执行。通过我们的评估,我们确认 GTX 系列 Pascal GPU 可以支持 32KB 的缓存,用于代码和敏感数据存储。然而,Tesla系列GPU比GTX系列GPU配备了更多的计算资源,具有2MB至4MB的I-Cache和C-Cache[57]。因此,ZEROKERNEL能够在Tesla系列GPU上执行更复杂的任务。
此外,ZEROKERNEL 不支持多个 GPU 内核执行,例如计算抢占的时间片执行和 CUDA MPS [58] 的并发执行,因为所有 GPU 上下文信息都在设备内存中被擦除。在 CUDA MPS 中,多个 GPU 内核的每个上下文被合并为单个 GPU 上下文,然后多个 GPU 内核同时运行在共享 GPU。设备内存中没有任何上下文的 ZEROKERNEL 无法支持与其他 GPU 内核的上下文集成。然而,Volta GPU [59]中的MPS支持多个GPU内核的并发执行,无需上下文集成。 ZEROKERNEL 的改进以支持新 GPU 模型中的多个 GPU 内核执行是我们未来的工作。
Generality
众多的GPU产品已经被开发出来,GPU架构也在不断发展。由于商业厂商没有公开其GPU产品的内部结构,因此很难证明我们的攻击和防御方法的通用性。然而,我们使用 Fermi、Kepler、Maxwell 和 Pascal 四种不同的 GPU 架构在真实 GPU 模型上进行了逆向工程和实验。我们的攻击方法依赖于对通用 GPU 上下文信息(包括页表和代码)的操作。我们的防御方法利用了 GPU 架构中的一般功能。因此,我们相信我们的攻击和防御方法对于各种 Nvidia 专用 GPU 是通用的。
集成 GPU 与 CPU 位于同一芯片上或集成到主板中,与 CPU 共享系统内存。因此,运行在集成GPU上的GPU内核的GPU上下文存在于系统内存中,并且它也可以被CPU驻留特权攻击者操纵。 Intel集成GPU中的L1-L2缓存和共享本地内存[60]不与系统内存和CPU缓存保持一致性。因此,它们可用于隔离 GPU 上下文信息。然而,作为专用GPU,集成GPU的TLB和缓存也可以被特权攻击者控制,因此仅上下文隔离并不能保证GPU执行的安全性。由于集成 GPU 位于同一芯片上并共享系统内存,因此与通过 PCIE 总线访问的专用 GPU 相比,它可以更快地受到 CPU 的控制。因此,我们预计即使采用ZEROKERNEL的检测机制,攻击也会更加成功。扩展ZEROKERNEL防御方法的适用性以及研究集成GPU的新方法将是新的研究方向。
CONCLUSION
这项工作分析了正在运行的 GPU 内核的 GPU 上下文,并表明特权攻击者可以操纵 GPU 上下文来影响 GPU 执行。在 GPU 内核执行期间,攻击者可以重定向内存访问或执行任意 GPU 代码。我们提出了一种新的安全 GPU 执行模型 ZEROKERNEL,该模型在 GPU 片上存储中的上下文隔离的情况下执行,并表明 ZEROKERNEL 可以提供足够的计算能力,即使它仅依赖于片上存储。多种防御机制支持 ZEROKERNEL 的安全性,我们的实验结果表明 ZEROKERNEL 可以保护自身免受上下文操纵攻击。 ZEROKERNEL 是一种新的解决方案,可在专用 GPU 上提供安全的计算环境,抵御特权攻击者。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











