






上一讲我们提到,推理模型的挑战在于:冗长的推理过程造成模型低效和高的推理成本。本讲则直接点出:“推理模型的下一步不是更会想,而是更知道何时停。” ,本文会按照“问题 → 解法 → 落地” 三个步骤记录,不让模型想太多的方法。
目录
1. 问题:RL 时代的新症状——“想太多”
-
现象:同样的题,模型答 5 次,最短链 5 k token,最长 20 k;长度翻倍,正确率却没涨。见下方截图。 记录模型最短的答案为group1,最长的答案为group5(横轴),在多个数学推理任务上,accuracy并没有随着推理内容变长而增加。[1]
-
根源:纯 RL 只给“答对”正奖励,不给“啰嗦”惩罚 → 模型用长度换置信度
-
后果:
– 用户侧:苦等 30 s,答案被埋在 10 k token 废话里;
– 厂商侧:GPU 账单随 token 线性膨胀,推理成本 > 训练成本。

2、解法:把“长度”重新写进奖励函数
给出 4 条技术路线,对应上一讲“四大流派”的瘦身版。
| 流派 | 控长手段 | 一句话总结 | 关键论文 |
|---|---|---|---|
| ① Prompt 工程 | Chain-of-Draft(每步≤5 词) | 不改模型,靠提示逼模型用更短的推理 | https://arxiv. org/pdf/2502.18600 |
| ② 工作流搜索 | 减少采样次数 | 人类直接拧旋钮:约束选择的路径从 8→2,长度立降 60 % | |
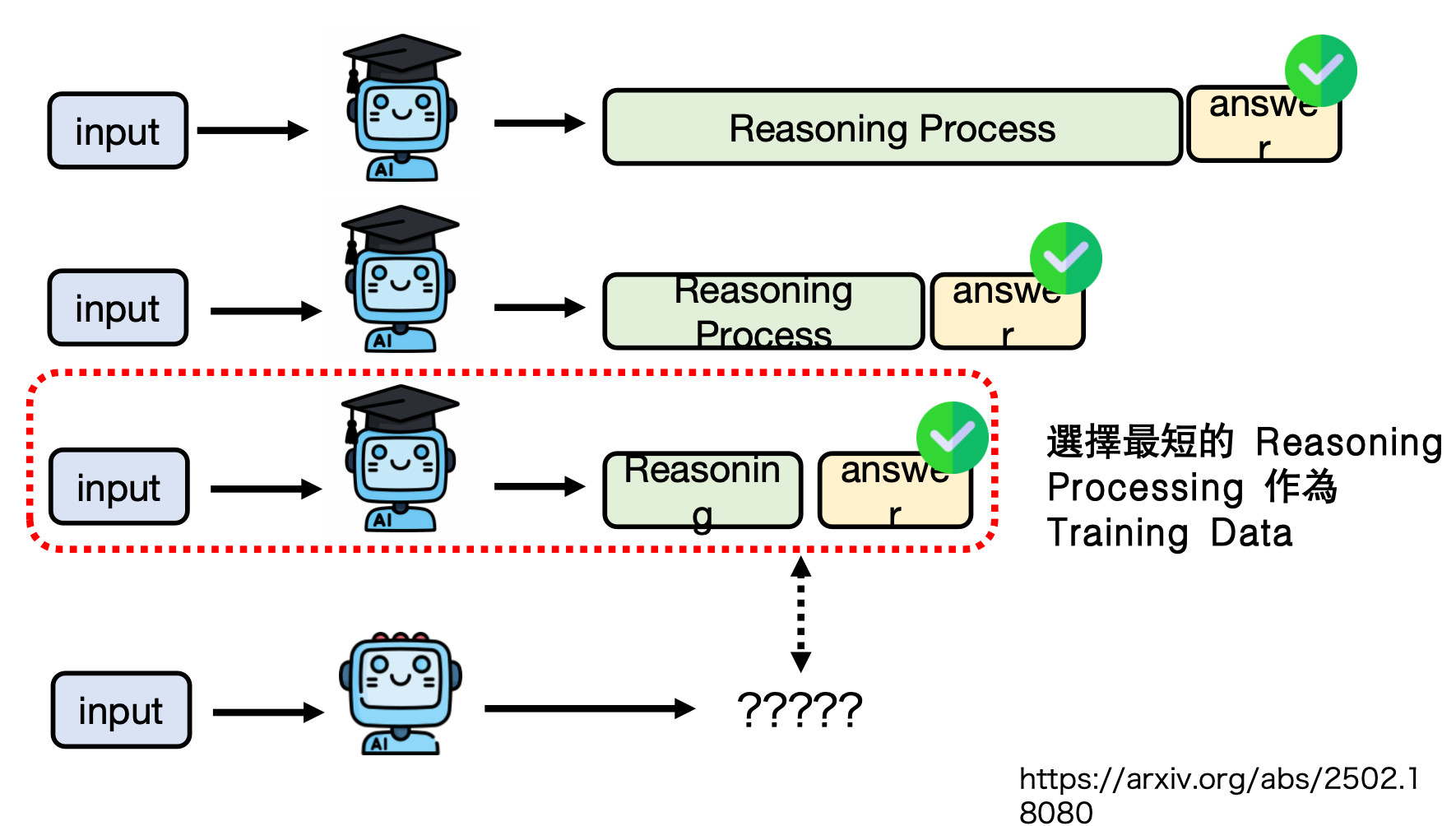
| ③ 模仿学习 | 只蒸馏“最短正确路径” | 教师写 10 条,选最短对的给学生 | https://arxiv.org/abs/2502.18080 |
| ④ 强化学习 | 奖励 = 正确率 − λ|长度−目标| | 把 token 当罪恶,越接近目标长度越爽 | https://arxiv.org/abs/2501.12570 https://arxiv.org/abs/2501.12599 https://arxiv.org/abs/2502.04463 |
技术详解
1)Chain-of-Draft
对比三种提示词:标准(Standar)、CoT(Chain-of-Thought)、CoD(Chain-of-Draft)如截图

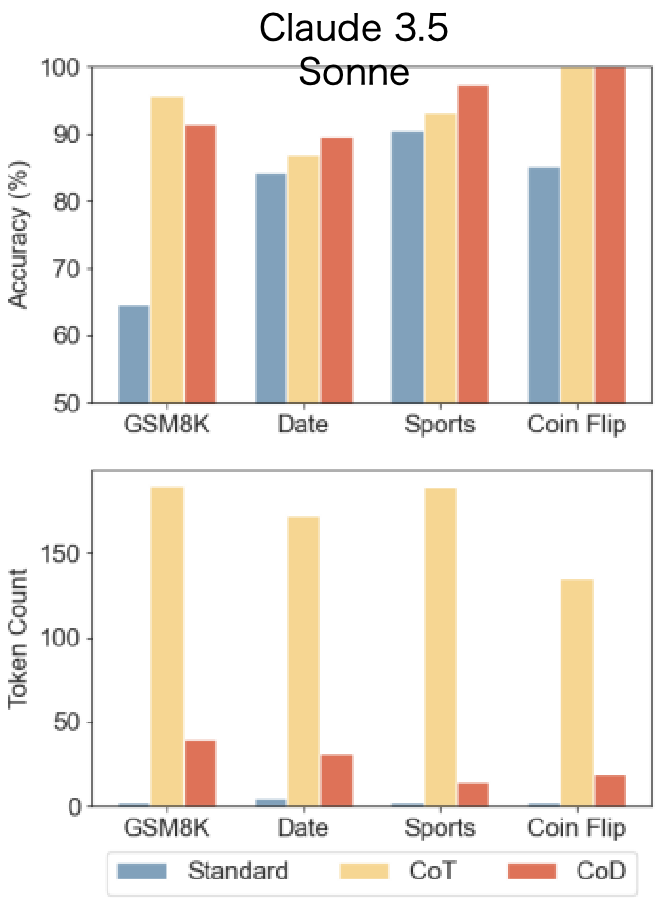
效果如下图,CoD在消耗更少Token的情况下,多个任务的Accuracy与CoT相似。
2)模仿学习——选择最短的推理过程作为后训练数据
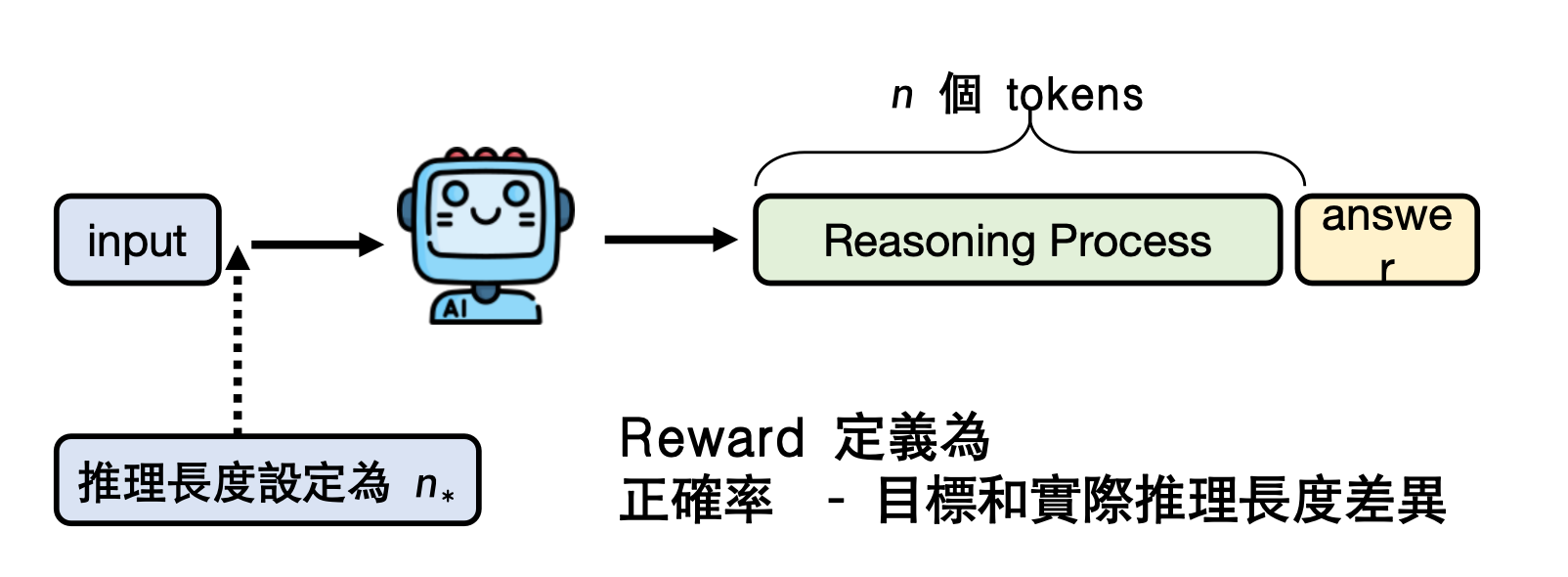
3)RL 细节-控制reasoning的长度
– 先离线统计“该题正确样本的平均长度 L*”;
– 在线训练时,多一个长度损失项,模型若想靠堆5k废话冲正确率,会被惩罚;
– 结果:同等正确率下长度降低35 %,且用户可指定“给我 200 token 版”或“1000 token 版”。

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









