






窗口函数的介绍
窗口函数的出现,主要就是为了解决group by 后每组语句只有一条的弊端,即使groupby经常与聚合函数一起使用,但是也只能应用在一些较简单的业务场景,对于复杂的场景,我们此时就需要使用窗口函数。
窗口函数:是一组特殊函数,扫描多个输入行来计算每个输出值,为每行数据都生成一行结果。
按功能可划分为:
排序、聚合、分析
语法:
Function (arg1,..., arg n) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_clause>])
PARTITION BY类似于GROUP BY,未指定则按整个结果集
只有指定ORDER BY子句之后才能进行窗口定义
可同时使用多个窗口函数,互相之间没有影响,独立应用自己的规则。
过滤窗口函数计算结果必须在外面一层
一定要注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
partition by子句
Over子句之后第一个提到的就是Partition By.Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算.
order by子句
order by子句会让输入的数据强制排序。Order By子句对于诸如Row_Number(),Lead(),LAG()等函数是必须的,因为如果数据无序,这些函数的结果就没有任何意义。因此如果有了Order By子句,则Count(),Min()等计算出来的结果就没有任何意义。
我们首先要理解两个概念:
- 如果只使用partition by子句,未指定order by的话,我们的聚合是分组内的聚合.
- 使用了order by子句,未使用window子句的情况下,默认从起点到当前行.
window子句
我们在上面已经通过使用partition by子句将数据进行了分组的处理.如果我们想要更细粒度的划分,我们就要引入window子句了. - PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
排序:
具有排序功能的窗口函数,就是对数据进行分区排序(over函数),在对排序后的数据添加一列序号值(排序函数)。
ROW_NUMBER()
对所有数值输出不同的序号,序号唯一连续
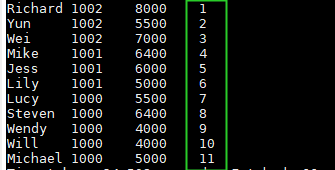
输入: (没有partition by时,单纯的对全局数据添加序号一列)
select name,dept_num,salary ,
row_number() over() as row_num
from employee_contract;
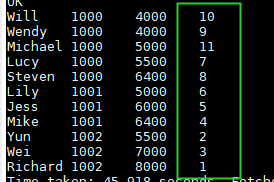
select name,dept_num,salary ,
row_number() over() as row_num
from employee_contract
order by dept_num,salary;
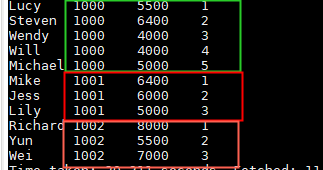
select name,dept_num,salary ,
row_number() over(partition by dept_num) as row_num
from employee_contract;
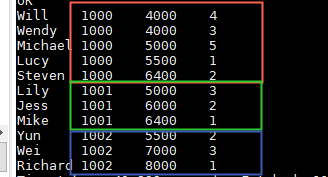
select name,dept_num,salary ,
row_number() over(partition by dept_num) as row_num
from employee_contract
order by dept_num,salary;
select name,dept_num,salary ,
row_number() over(partition by dept_num order by salary) as row_num
from employee_contract;
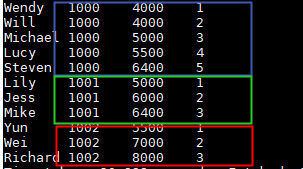
select name,dept_num,salary ,
row_number() over(partition by dept_num order by salary) as row_num
from employee_contract
order by dept_num,salary;
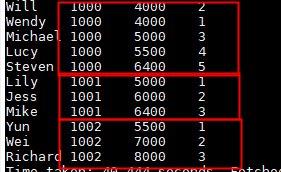
总结:
1、这里我们可以看到,窗口函数是在order by之前执行的,在窗口函数外使用order by ,会对窗口函数的计算结果重新进行排序。(只有order by ,其他都是最后执行)
2、partition by 子句,会根据字段,把数据分成不同的组,此时的聚合,排序等都是分组内的。
3、聚合函数over()内的order by ,是对每一个分组内的数据根据排序字段进行排序,然后在对分组后的函数进行聚合等操作。
其他排序函数和row_number()的使用思想都是一样的,只是聚合的规则稍有不一样,接下来不在详细阐述。
RANK()
对相同数值,输出相同的序号,下一个序号跳过
如(前两个数值相同)(1,1,3)
使用rank over()的时候,空值是最大的,如果排序字段为null, 可能造成null字段排在最前面,影响排序结果。
可以这样: rank over(partition by course order by score desc nulls last)
select name,dept_num,salary ,
rank() over(partition by dept_num order by salary) as row_num
from employee_contract;
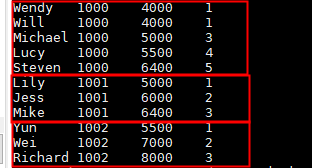
select name,dept_num,salary ,
rank() over(order by salary) as row_num
from employee_contract;
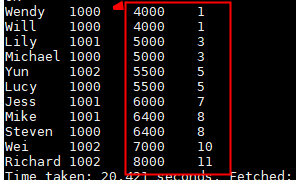
此种情况,是只使用orderby ,此时是对全局的数据根据salary进行排序,这样可以查看整个公司的员工的工资分布情况。同样其他,排序函数也可以使用,都是一样的。
DENSE_RANK()
对相同数值,输出相同的序号,不跳过,下一个序号连续
如(前两个数值相同)(1,1,2)
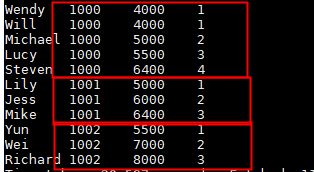
select name,dept_num,salary ,
dense_rank() over(partition by dept_num order by salary) as row_num
from employee_contract;
NTILE(n)
将有序的数据集合平均分配到n个桶中,桶号分配给每一行,
根据桶号,选取前或者后n分之几的数据。
select name,dept_num,salary ,
ntile(3) over(partition by dept_num order by salary) as row_num
from employee_contract;
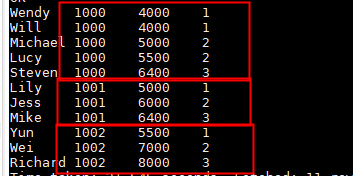
后面的数字是分桶号,如果我们想取前三分之一的数据,只要查询桶号=1的数据即可,可以用于数据的抽样。
PERCENT_RANK()
(目前排名- 1)/(总行数- 1),值相对于一组值的百分比排名。
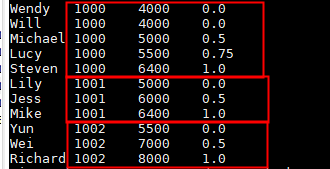
select name,dept_num,salary ,
percent_rank() over(partition by dept_num order by salary desc) as row_num
from employee_contract;
聚合
聚合函数主要包括:count()、sum()、max()、min()、avg()等
我们来看一下其在窗口聚合函数中的应用。
从Hive 2.1.0开始在OVER子句中支持聚合函数
count():统计数量
SELECT rank() OVER (ORDER BY sum(b)) FROM T GROUP BY a;
//统计每个组中的数量,每一行数据都给一个输出结果。
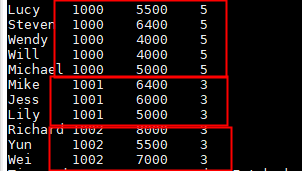
select name,dept_num,salary ,
count(*) over(partition by dept_num) as row_num
from employee_contract;
//统计每个组中的数量,每一行数据都给一个输出结果。
select name,dept_num,salary ,
count(distinct *) over(partition by dept_num) as row_num
from employee_contract;
这样就可以输出,不重复的数据
//统计每个组中的数量,但是是针对每组里面的每一行进行累加统计,直到每组的结尾,输出一个总数。
select name,dept_num,salary ,
count(*) over(partition by dept_num order by salary) as row_num
from employee_contract;
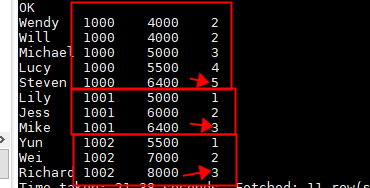
sum() :求和
//统计每个部门中的工资的总额,每一行数据都给一个输出结果。
select name,dept_num,salary ,
sum(salary) over(partition by dept_num) as row_num
from employee_contract;
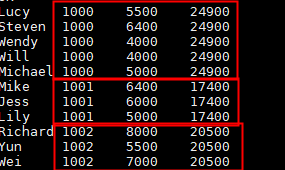
//统计每个部门中的工资的总额,并进行累加,每一行数据都给一个输出结果。
select name,dept_num,salary ,
sum(salary) over(partition by dept_num order by salary) as row_num
from employee_contract;
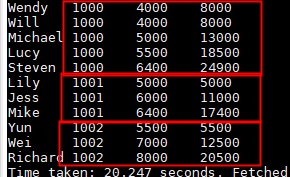
max()
//统计每个部门中的工资的总额,每一行数据都给一个输出结果。
select name,dept_num,salary ,
max(salary) over(partition by dept_num) as row_num
from employee_contract;
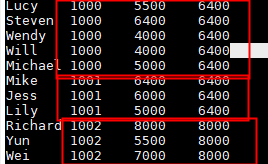
min()
//统计每个部门中的工资的总额,每一行数据都给一个输出结果。
select name,dept_num,salary ,
min(salary) over(partition by dept_num) as row_num
from employee_contract;
正好与上图的数据相反,取出每个组中的最小值。
分析
CUME_DIST()
小于等于当前值的行数/分组内总行数
LEAD/LAG(col,n)
某一列进行往前/后第n行值(n可选,默认为1)
FIRST_VALUE
对该列到目前为止的首个值
LAST_VALUE
到目前行为止的最后一个值
SELECT
name, dept_num, salary,
LEAD(salary, 2) OVER(PARTITION BY dept_num ORDER BY salary) AS lead,
LAG(salary, 2, 0) OVER(PARTITION BY dept_num ORDER BY salary) AS lag,
FIRST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary) AS first_value,
LAST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary) AS last_value_default,
LAST_VALUE(salary) OVER (PARTITION BY dept_num ORDER BY salary RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_value
FROM employee_contract;
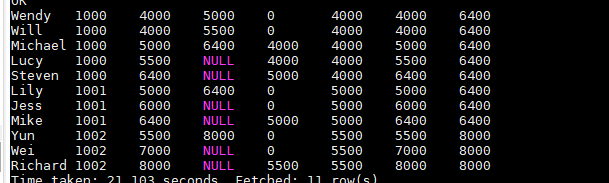
自定义窗口
上面的RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 使我们的window子句,主要用来动态控制窗口的范围,不在限定在某一组中,即自定义窗口。
主要分为两种:
行窗口:根据当前行之前或之后的行号确定的窗口
范围窗口:是取分组内的值在指定范围区间内的行
该范围值/区间必须是数字或日期类型目前只支持一个ORDER BY列
语法是:rows/range between … and …
- PRECEDING:往前
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
但是RANK、NTILE、DENSE_RANK、CUME_DIST、PERCENT_RANK、LEAD、LAG和ROW_NUMBER函数不支持与窗口子句一起使用
- 示例
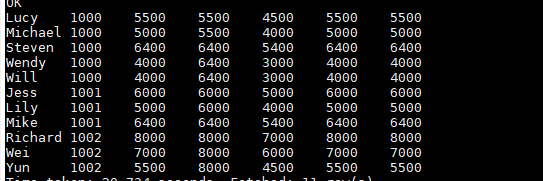
//行窗口
SELECT name, dept_num AS dept, salary AS sal,
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) win1,
salary - 1000 as sal_r_start,salary as sal_r_end,
//范围窗口
MAX(salary) OVER (PARTITION BY dept_num ORDER BY name RANGE BETWEEN 1000 PRECEDING AND CURRENT ROW) win13
FROM employee_contract ;















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









