





 文章提出了PatternExploitingTraining(PET)方法,通过将输入示例转化为完形填空形式,结合预训练语言模型理解任务,改善小样本文本分类和自然语言推理。PET和迭代版本iPET在多种任务和语言上展现出优越性能,特别是在资源有限的情况下。
文章提出了PatternExploitingTraining(PET)方法,通过将输入示例转化为完形填空形式,结合预训练语言模型理解任务,改善小样本文本分类和自然语言推理。PET和迭代版本iPET在多种任务和语言上展现出优越性能,特别是在资源有限的情况下。
《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》
标题:《利用完形填空题进行少量镜头文本分类和自然语言推理》
期刊:2021年EACL (欧洲自然语言处理会议)
作者:Timo Schick Hinrich Schutze
单位: 德国慕尼黑大学信息和语言处理中心
摘要
通过提供带有自然语言“任务描述”的预训练语言模型,可以以完全无人监督的方式解决某些 NLP 任务(例如,Radford 等人,2019 年)。虽然这种方法的表现不及监督方法,但我们在这项工作中展示了这两种想法可以结合起来:我们介绍了 PatternExploiting Training (PET),这是一种半监督训练程序,将输入示例重新表述为完形填空式短语,以帮助语言模型理解给定的任务。然后使用这些短语将软标签分配给大量未标记的示例。最后,对生成的训练集执行标准监督训练。
对于多种任务和语言,PET 在资源匮乏的环境中大大优于监督训练和强大的半监督方法。
1.介绍
从示例中学习是许多 NLP 任务的主要方法:模型在一组标记示例上进行训练,然后从中泛化到看不见的数据。
由于语言、领域和任务的数量众多以及注释数据的成本,在 NLP 的实际使用中通常只有少量标记示例,这使得少样本学习成为一个非常重要的研究领域。不幸的是,将标准监督学习应用于小型训练集通常表现不佳;很多问题光看几个例子是很难把握的。例如,假设我们得到以下文本片段:
T1: This was the best pizza I’ve ever had.
T2: You can get better sushi for half the price.
T3: Pizza was average. Not worth the price.
此外,假设我们被告知 T1 和 T2 的标签分别是 l 和 l’,并且我们被要求推断出 T3 的正确标签。仅基于这些示例,这是不可能的,因为可以为 l 和 l’ 找到合理的理由。
然而,如果我们知道基本任务是识别文本是否提及价格,我们可以轻松地将 l’ 分配给 T3。这说明,当我们还有任务描述时,仅通过几个示例解决任务就会变得容易得多,即帮助我们理解任务内容的文本解释。
随着 GPT(Radford 等人,2018 年)、BERT(Devlin 等人,2019 年)和 RoBERTa(Liu 等人,2019 年)等预训练语言模型(PLM)的兴起,提供任务描述的想法已经成为对于神经架构是可行的:我们只需将自然语言中的此类描述附加到输入中,然后让 PLM 预测解决任务的延续(Radford 等人,2019 年;Puri 和 Catanzaro,2019 年)。到目前为止,这个想法主要是在根本没有可用训练数据的零样本场景中考虑的。
在这项工作中,我们展示了提供任务描述可以成功地与小样本设置中的标准监督学习相结合:我们介绍了模式利用训练 (PET),这是一种半监督训练程序,它使用自然语言模式将输入示例重新表述为完形填空式短语。
如图 1 所示,PET 分三个步骤工作:
首先,对于每个模式,一个单独的 PLM 在一个小训练集 T 上进行微调。
然后使用所有模型的集合来注释带有软标签的大型未标记数据集 D。
最后,在软标记数据集上训练标准分类器。我们还设计了 iPET,这是 PET 的一种迭代变体,其中随着训练集大小的增加重复此过程。
在多种语言的不同任务集上,我们表明,给定少量到中等数量的标记示例,PET 和 iPET 明显优于无监督方法、监督训练和强大的半监督基线。

2.相关工作
雷德福等人。 (2019) 以自然语言模式的形式为阅读理解和问答 (QA) 等具有挑战性的任务的零样本学习提供提示。这一思想已应用于无监督文本分类(Puri 和 Catanzaro,2019)、常识知识挖掘(Davison 等,2019)和论证关系分类(Opitz,2019)。斯利瓦斯塔瓦等。 (2018) 使用任务描述进行零样本分类,但需要语义解析器。对于关系提取,Bouraoui 等人。 (2020) 自动识别表达给定关系的模式。麦肯等人。 (2018) 将几个任务改写为 QA 问题。拉菲尔等人。 (2020) 将各种问题定义为语言建模任务,但它们的模式只是松散地类似于自然语言,不适合小样本学习。
最近的另一项工作使用完形填空式短语来探究 PLM 在预训练期间获得的知识;这包括调查事实和常识性知识(Trinh 和 Le,2018 年;Petroni 等人,2019 年;Wang 等人,2019 年;Sakaguchi 等人,2020 年),语言能力(Ettinger,2020 年;Kassner 和 Sch ̈ utze,2020 年),理解稀有词 (Schick and Sch ̈ utze, 2020),以及进行符号推理的能力 (Talmor et al., 2019)。姜等。 (2020) 考虑寻找最佳模式来表达给定任务的问题。
NLP 中小样本学习的其他方法包括利用相关任务中的示例(Yu 等人,2018 年;Gu 等人,2018 年;Dou 等人,2019 年;Qian 和 Yu,2019 年;Yin 等人,2019 年)并使用数据增强(Xie et al., 2020; Chen et al., 2020);后者通常依赖于反向翻译 (Sennrich et al., 2016),需要大量并行数据。使用文本类描述符的方法通常假设大量示例可用于类的子集(例如,Romera-Paredes 和 Torr,2015 年;Veeranna 等人,2016 年;Ye 等人,2020 年)。相比之下,我们的方法不需要额外的标记数据,并提供了一个直观的界面来利用特定于任务的人类知识。
iPET 背后的想法——在前几代标记的数据上训练多代模型——与词义消歧(Yarowsky,1995)、关系提取(Brin,1999;Agichtein 和 Gravano,2000;Batista)的自我训练和引导方法相似等人,2015 年)、解析(McClosky 等人,2006 年;Reichart 和 Rappoport,2007 年;Huang 和 Harper,2009 年)、机器翻译(Hoang 等人,2018 年)和序列生成(He 等人,2020 年) ).
3. 模式开发训练
设 M 是一个带有词汇 V 和掩码标记 ∈ V 的掩码语言模型,设 L 是我们目标分类任务 A 的一组标签。我们将任务 A 的输入写为短语序列 x = (s1, . . . , sk) 且 si ∈ V ∗;例如,如果 A 是文本推理(两个输入句子),则 k = 2。我们将一个模式定义为一个函数 P,它以 x 作为输入并输出一个短语或句子 P (x) ∈ V ∗ 恰好包含一个掩码标记,即它的输出可以看作是一个完形填空题。此外,我们将 verbalizer 定义为单射函数 v : L → V ,它将每个标签映射到 M 词汇表中的一个词。我们将 (P, v) 称为模式-表达器对 (PVP) 。
3.1 参数说明
假设 M 表示一个预训练语言模型,词汇表记做 V,其中包含一个[MASK](原文作者用下划线表示),L 表示目标任务 A 的所有标签集合。
任务 A 的输入记做 X=(s1,s2,…,sk) 。其中 si 表示一个句子。如果 k=2,则输入的 X 是两个句子,通常在自然语言推理或文本蕴含任务中使用。
定义一个函数 ,其将 X 作为输入,输出 P(X) 表示将 X 转化为带有[MASK]的phrase;
定义一个映射: v:L→V 其表示将每个标签映射到具体的词。例如在情感分析中,我们可以为positive标签寻找一个词great作为替代。
最终 (P,v) 作为pattern-verbalizer-pair(PVP)。
3.2 PET的实现原理
给定一个sentence pair任务,其判断两个句子是否矛盾。输入则为两个句子,如图:
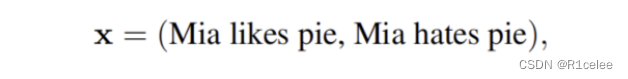
pattern映射为带有[MASK]的模板:
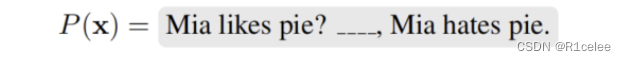
其原始的标签是entailment和contradiction,根据verbalizer v 可以设计映射关系为{entailment:yes、contradiction:no},因此模型可以对[MASK]的部分输出预测yes或no的概率。
3.3 PET的训练和推理
定义一个 M(w∣Z) 表示给定带有一个[MASK]标记的序列 Z,语言模型可以在该[MASK]位置填入词 w∈L 的非归一化得分,其次定义概率分布:
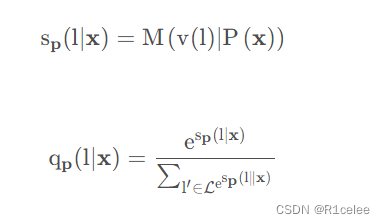
使用cross-entropy进行训练。作者发现,由于这是在非常少的样本集合 T 上进行训练,可能会导致灾难性遗忘,因此作者引入预训练模型的loss作为辅助损失(Auxiliary MLM loss),两个损失通过加权方式结合:
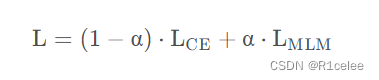
Lce 是交叉熵的loss
Lmlm 是再做一次完形填空的Loss
作者根据先前的工作,取了一个经验值 α = 1 0-4 .
3.4模型训练
(1)首先在小样本数据集 T 对一组预训练模型进行微调(上一节)(为每个模板去微调语言模型);
(2)其次将每一个预训练模型进行集成、对于每个预训练模型,分别对未标注的数据集 D 进行标注,此时获得的是soft-label,即给定一个输入 X,标签 l∈V 的概率得分:
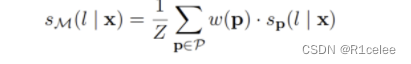
Sm:ensemble模型 集成模型
W(p):权重
得到新的数据集 Tc;
(3)在 Tc 使用标准的微调方法进行微调。
(2)->(3)的过程比较类似knowledge distillation过程
其中 Z = ∑ p∈P w§ 和 w§ 是 PVP 的加权项。我们试验了这个权重项的两种不同实现:我们简单地为所有 p 设置 w§ = 1,或者我们将 w§ 设置为训练前在训练集上使用 p 获得的准确度。我们将这两种变体称为统一和加权。姜等。 (2020) 在零镜头设置中使用了类似的想法。
3.5Iterative PET
作者发现,如果只进行一次微调+生成,往往得到的新的数据集会有很多错误的数据,因此扩展提出iPET模型,即添加了迭代。iPET的核心思想是:
The core idea of iPET is to train several generations of models on datasets of increasing size.
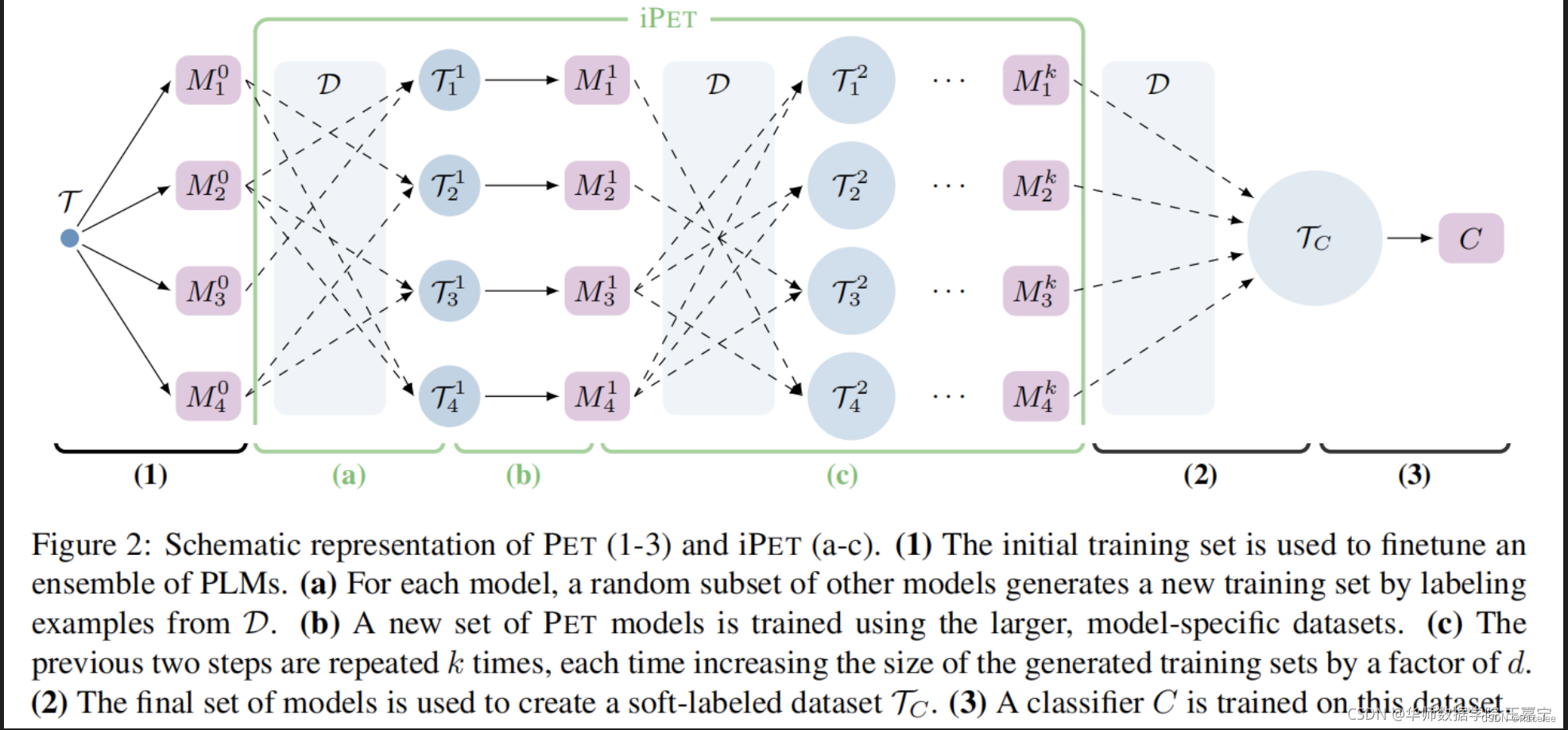
PET训练过程:
1.初始训练集用于微调一系列的预训练模型,每个模板微调一个模型
2.集成(1)中模型,对无标签数据进行预测,产生soft标签数据集
3.基于(2)中伪标签数据集,训练分类器
对于iPET模型
(a)对于任意一个模型,其他模型对无监督数据集D的一个子集进行标注,产生的样本被补充到T,然后用来(b)中训练当前模型;M02和M03标注一部分D,再加上T,得到T11,T11用来(b)中训练M11
(b)如上所述,基于被补充的新数据集,再训练模型
(c)重复(a)(b)k次,每次数据集补充d倍;
iPET的大致流程如上图所示,首先随机从集成的预训练模型集合中抽取部分预训练模型,并在未标注数据集 D 上标注部分数据,并扩增到 T,其次再根据扩增后的 T 分别微调预训练模型。上述过程一直迭代多次。
(1)假设初始化有 n 个预训练模型 M0=M10,…,Mn0 。在第 j 轮迭代,则先随机从上一轮迭代获得的预训练模型集合中抽取 λ⋅(n−1) 个模型,记做:
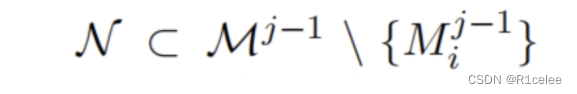
(2)其次使用该预训练集合,生成一个标注数据集:
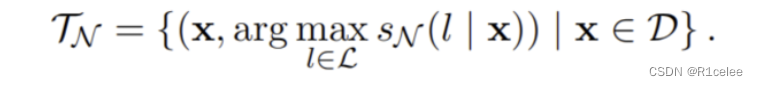
由上式可知,每次从每个类 l 中挑选得分最高的样本,以避免引入大量的错误标注数据。其中 sN(l∣X) 表示得分。
(3)合并原始的小样本标注数据和新生成的数据:
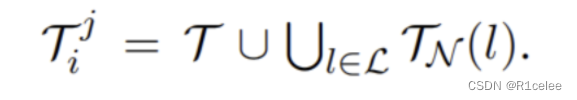
最后,iPET迭代 k 次后,将最后一次训练好的预训练模型集合 Mk 用来标注数据,并生成 TC。
3.6 推荐使用的PVP
(1)情感分析类型任务(例如五分类的Yelp)
任务描述:给定一个句子,判断其情感类型,例如电影评论等;

(2)主题分类型任务(例如AGNews、Yahoo)
给定一个句子,判断其主题类型,例如新闻分类等;

- verbalizer:可以直接将label class的词作为label word。
(3)句子对类型任务(例如MNLI)
给定两个句子,判断两个句子的相关性(MNLI等为判断前后句子是否有逻辑关系)

4.实验
(1)训练集数量与效果提升的变化关系:
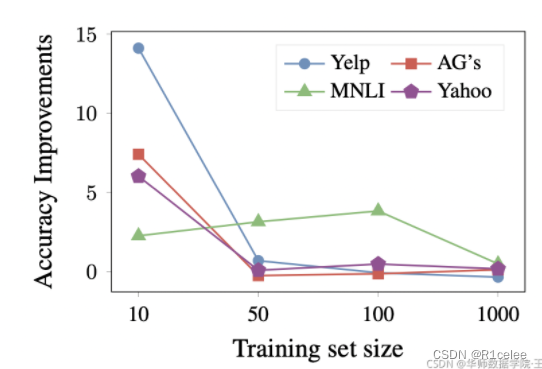
说明了PET在样本数量少的时候,基于Prompt的方法提升很明显,但是在数量较多时,相比传统方法只有小量提升。
(2)在所有数据集上的实验结果:

不论样本数量有多少,基于迭代的iPET模型均可以达到SOTA。(supervised表示直接使用RoBERTa-large传统的方法进行微调)

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









