







附注
- 这篇文章中在最终提到模型的时候使用了一个 “知识蒸馏” 的点,这点需要注意。如果不懂的话,请参考知识蒸馏基本原理
- 其实,这里的知识蒸馏主要是在预训练模型的Fine-tuning中应用的较多,首先是使用一个大于1的T来学习预训练模型得到的一个有关数据之间的软分布,同时加上自己的一定真是数据,这样可以使得我们的模型具有较好的泛化能力。
- 接着是在我们进行预测的时候将T的温度降下来,使得输出一个正常的分布。
文章主要思想
- 首先对于这篇文献主要解决的问题是few-shot文本分类问题,同时在文中也是提到了文中提到的方法加以改进亦可以做到zero-shot方面的文本分类问题上来。
- Few-shot上面存在的问题有:
- 首先,few-shot的数据集中带有标签的数据量很少,这种情况有可能导致,我我们在进行模型的预训练的时候很难从这些少量的实例中提取到有用的信息。
- 因此,文中针对于解决few-shot的文本分类问题提出了它的解决方案。
- 文中提到的算法有两个名称分别是PET和iPET,很明显可以看出来iPET是PET模型的改进版。也就是使用的迭代的方式来解决了PET方法中遗留下来的问题。
- 这里先论述base method——PET方法。
- 这种方法使用的大致思想是,首先使用few-shot数据集中仅存的少量带标签的数据对MLM模型进行Fine-tuning,然后可以得到一个集成的语言模型,至于为什么是集成的、以及训练的思想下面再叙述。
- 然后,使用上面得到的Fine-tuning之后的模型,对于数据集中存在的大量的无标签数据进行标签的信息标注,然后我们就可以得到大量的带有标注的数据,将这些数据和原来仅有的一些带标签数据结合就可以生成一个更大的带标签数据集。
- 使用上面扩充的带标签数据集在对预训练语言模型进行Fine-tuning,就可以得到针对于处理特定的任务的模型,然后,通过这个模型就可以执行分类任务了。
- 通过上面的步骤从而实现few-shot问题的解决。
- iPET方法
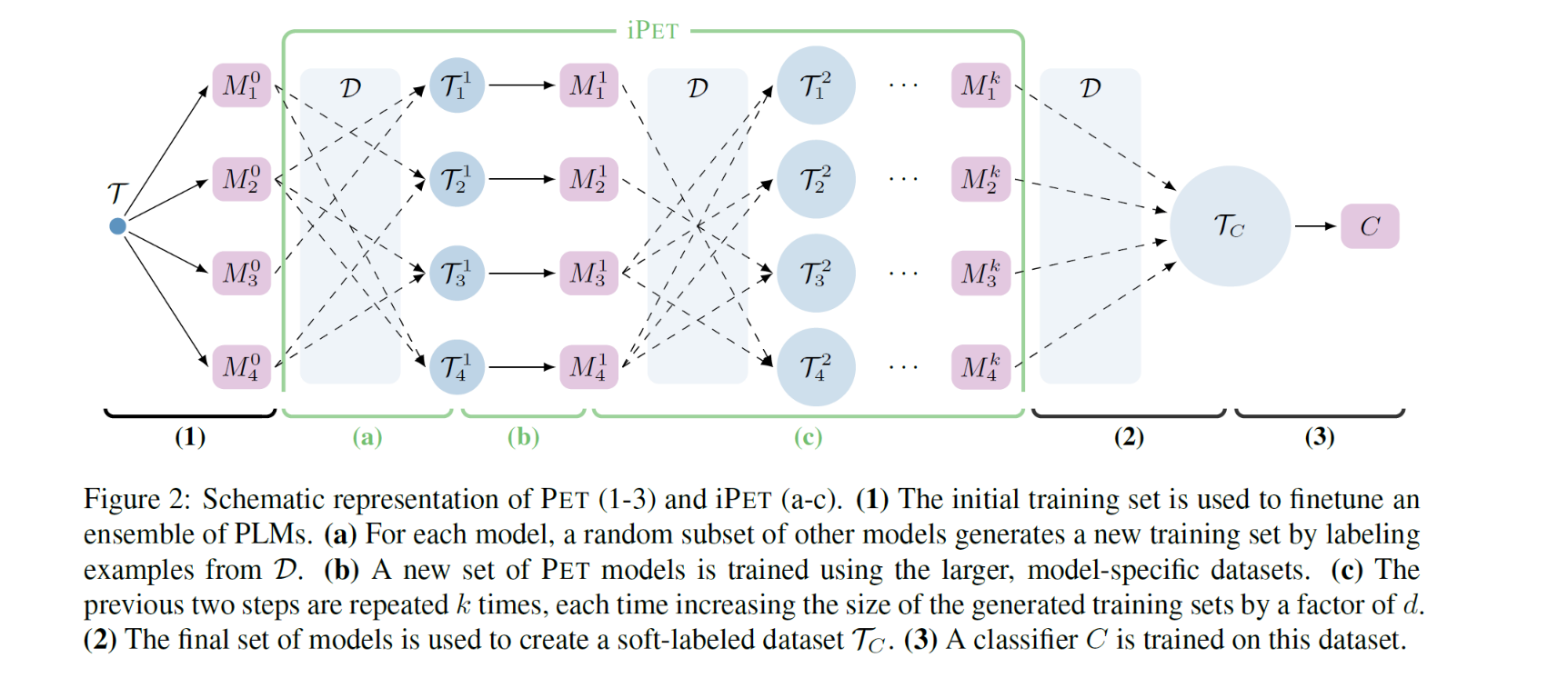
- 这种方法其实基于PET方法的改进版,正如上面的图中所示,这种改进型的方法使用的是PET方法的基础架构。
- 这种方式是基于PET方式的一种迭代版本,就是Tj为模型Mj的训练数据,首先T0是我们起始的时候few-shot中原本带有的一些标注数据集,M0就是基于原来PET方式中得到的ensemble模型,然后基于Mj我们就可以在数据集中选择一定的数据使用Mj模型对这个数据进行标注,然后结合原来的已标注数据就可形成一个更大的标注数据集Tj+1,再通过这个更大的数据集就可以得到Mj+1模型,以此类推,最终迭代到第k次就可以的得到一个效果很好的ensemble模型了,通过这个模型得到最后的标注数据集Tc,然后使用上面PET的方法就可以Fine-tuning出来一个效果很好的模型了。
- 作者在文中提到,这种改进型的PET方法可以应用到zero-shot上面,不过同样要对上面iPET模型进行加以改进。改进的方法就是==将M0设置为没有经过Fine-tuning的模型,然后让这个模型对我们全局都是没有标记的数据进行打标签,然后再沿用上面iPET的方式,通过这种方式来解决0样本问题。
PET
这种方法具体流程在Fine-tuning上面,首先这里引入了两个函数P和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









