







本文参考文章
https://www.cnblogs.com/wu-Chiyu/p/15400105.html
现在对于本文出现的表给出建表sql(我真是太贴心了)
DROP TABLE IF EXISTS `tab1`;
CREATE TABLE `tab1` (
`id` int(11) NOT NULL,
`size` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `tab1` VALUES (1, 10);
INSERT INTO `tab1` VALUES (2, 20);
INSERT INTO `tab1` VALUES (3, 30);
DROP TABLE IF EXISTS `tab2`;
CREATE TABLE `tab2` (
`id` int(11) NOT NULL,
`size` int(11) NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `tab2` VALUES (1, 10, 'AAA');
INSERT INTO `tab2` VALUES (2, 20, 'BBB');
INSERT INTO `tab2` VALUES (3, 20, 'CCC');
-- ----------------------------
-- Table structure for students
-- ----------------------------
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`id` int(11) NOT NULL,
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int(11) NULL DEFAULT NULL,
`gender` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`major` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of students
-- ----------------------------
INSERT INTO `students` VALUES (1, 'Alice', 20, 'F', 'Computer Science');
INSERT INTO `students` VALUES (2, 'Bob', 21, 'M', 'Mathematics');
INSERT INTO `students` VALUES (3, 'Charlie', 22, 'M', 'Physics');
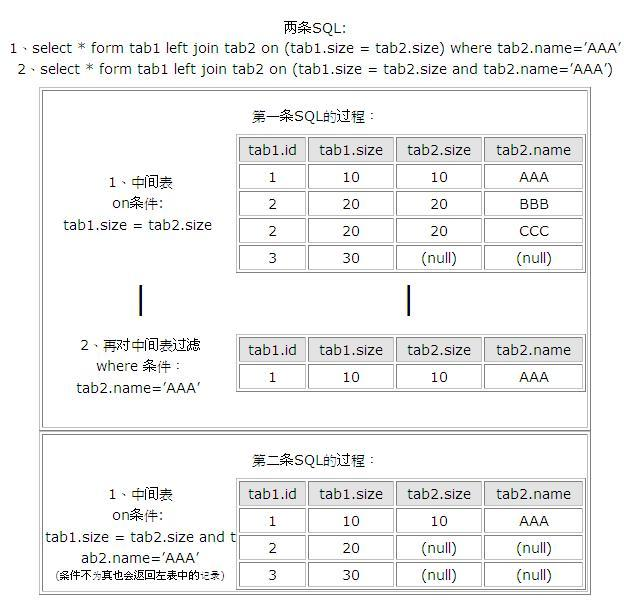
连表查询中WHERE与ON的区别
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
ON在生成临时表时使用,返回表会受到JOIN类型的影响。在LEFT JOIN和RIGHT JOIN中,无论ON上的条件是否为真都会返回左表或右表中的内容,而在INNER JOIN中,WHERE与ON返回表相同。WHERE在临时表生成后,再对临时表进行过滤。这时返回表与JOIN的类型无关,条件不为真的就全部过滤
WHERE,ON,HAVING的区别
- 执行次序:ON>WHERE>HAVING,如果这先后顺序不影响中间结果的话,最终结果相同
- ON先把不符合条件的记录过滤后再进行统计,on一般用于多表进行查询
- WHERE对于ON的记录进行筛选,不符合条件的全部过滤掉,WHERE无法与聚合函数一起使用
- HAVING在分组之后再过滤数据,经过测试下面的语句是错误的。
select name from students HAVING age>20;
having 和 group by的用法
group by
使用 GROUP BY 子句对数据进行分组操作时,必须要指定 SELECT 语句中需要查询哪些字段,并且这些字段必须是分组键或者聚合函数(即select后面只能出现分组的字段和聚合函数)比如下面的sql是错误的.
分组键就是group by后面的
select * from students GROUP BY gender;
select name,count(*) from students GROUP BY gender
比如下面的sql就是正确的
select gender, count(*) from students GROUP BY gender;
- GROUP_CONCAT 函数可以将每个分组内的姓名拼接成一个字符串,并用逗号分隔
SELECT gender, COUNT(*) AS count, GROUP_CONCAT(name) AS names
FROM students
GROUP BY gender;
having
having不能单独使用,必须要和group by组合使用,并且在group by的后面例如下面的sql就是错误的
select name from students HAVING age>20;
如果你需要在having子句中使用某个表格中的字段,那么必须在SELECT语句中列出来,否则sql的结果可能出现错误
SELECT gender, COUNT(*) AS count, GROUP_CONCAT(name) AS names
FROM students
GROUP BY gender;
HAVING age>20;
Having 后面的字段可以用聚合函数本身,也可以使用别名,比如下面的sql就是正确的
SELECT gender, COUNT(*) AS count, GROUP_CONCAT(name) AS names
FROM students
GROUP BY gender
HAVING count=2;
SELECT gender, COUNT(*) AS count, GROUP_CONCAT(name) AS names
FROM students
GROUP BY gender
HAVING COUNT(*)=2;
常用的聚合函数总结
MIN 最小值
MAX 最大值
SUM 求和
AVG 求平均
COUNT 计数















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









