






一. RAID的基本原理和概念
1.1 RAID基本概念
RAID=Redundant Arrays of Independent Disks,中文称之为独立冗余磁盘阵列。于1987年由美国伯克利大学提出,从本质上来说,RAID是一种多磁盘管理技术,利用多个相互独立的高性能磁盘驱动器组成磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术,其中部分物理存储空间可用来记录和保存用于重建用户数据的冗余信息,同时并发的在多个磁盘上读写数据来提高存储系统的I/O性能。

图 1.1 RAID的基本框架图
1.2 RAID基本原理
1.2.1 镜像(Mirroring)
采用镜像技术将会同时在阵列中产生两个完全相同的副本,分布在两个不同的磁盘驱动器组上。镜像提供了完全的数据冗余能力,当一组磁盘驱动器当中的任意一个磁盘设备失效时,RAID控制器仍然能正常访问另外不同组的副本,不会对应用系统运行和性能产生影响。

图1.2.1 镜像读写示意图
1.2.2 数据条带(Data stripping)
RAID 由多块磁盘组成,数据条带技术将数据以块的方式均匀分布存储在多个磁盘中(单个磁盘所分得的数据块的大小叫条带粒度,且条带粒度包含的扇区的数量是整数),从而可以对数据进行并发处理。这样写入和读取数据就可以在多个磁盘上同时进行,并发产生非常高的聚合 I/O ,有效提高了整体 I/O 性能,而且具有良好的线性扩展性。这对大容量数据尤其显著,如果不分块,数据只能按顺序存储在磁盘阵列的磁盘上,需要时再按顺序读取。而通过条带技术,可获得数倍与顺序访问的性能提升。
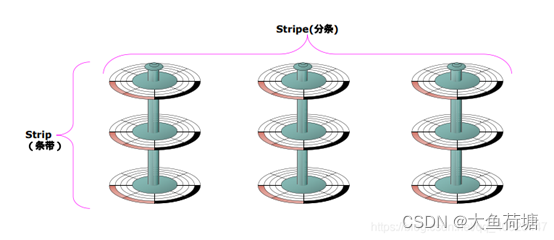 图1.2.2 数据条带示意图
图1.2.2 数据条带示意图
For example, in a four-disk system using only disk striping (used in RAID level 0), segment 1 is written to disk 1,segment 2 is written to disk 2, and so on. Disk striping enhances performance because multiple drives are accessed simultaneously, but disk striping does not provide data redundancy.
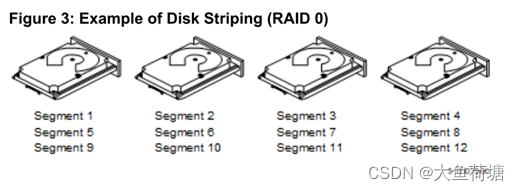
图1.2.3 RAID0数据条带示意图
1.2.3 数据校验(Data parity)
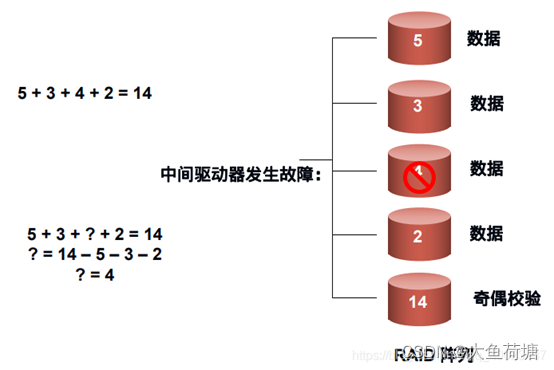
图1.2.4 数据校验示意图
采用数据校验时, RAID 要在写入数据同时进行校验计算,并将得到的校验数据存储在 RAID 成员磁盘中。校验数据可以集中保存在某个磁盘或分散存储在多个不同磁盘中,甚至校验数据也可以分块,不同 RAID 等级实现各不相同。当其中一部分数据出错时,就可以对剩余数据和校验数据进行反校验计算重建丢失的数据。校验技术相对于镜像技术的优势在于节省大量开销,但由于每次数据读写都要进行大量的校验运算,对计算机的运算速度要求很高,必须使用硬件 RAID 控制器。在数据重建恢复方面,检验技术比镜像技术复杂得多且慢得多。
1.2.4 磁盘组(RAID group)
磁盘组RG的成员盘由创建vd命令时指定,需要特别注意的是RG可有多个VD组成,但VD的RAID级别一定是相同的。可以查看的RG相关信息有:总容量(Total Capacity),剩余容量(Free Capacity),回拷的开关状态(CopyBack Switch),成员盘整体的cache状态(PD Cache),逻辑块的大小(Logical Block Size),成员盘的信息(包含ENC,SLOT),包含的热备盘信息,RAID组容量的整体使用情况(RAID Group Block Infomation)。
1.2.5 逻辑磁盘(Virtual drive)
逻辑磁盘VD与磁盘组RG的关系属于子集与母集的关系,可以查看的VD相关信息有:RAID级别(RAID Level),在VDLIST当中的标识(ID),所属RAID组的标识(RAID ID),VD状态(Status),上报的设备类型(Map Type),OS下盘符标号(OS Drive Letter),条带大小(Stripe Size),Write Cache策略,Real Write Cache策略,Read Cache策略,VD 初始化信息(VD Initialize)。
1.2.6 后台初始化(Background Initialization)
Background initialization is a check for media errors on the drives when you create a virtual drive. Background initialization is an automatic operation that starts five minutes after you create the virtual drive. This check ensures that striped data segments are the same on all of the drives in the drive group.Background initialization is similar to a consistency check. The difference between the two is that a background initialization is forced on new virtual drives and a consistency check is not.
1.2.7 写cache策略(Write Cache)
Write-back:RAID caching is a cost-effective way to improve I/O performance by writing data to a controller’s cache before it is written to disk. Write-back cache improves application performance by storing write data to high performance cache memory during periods of heavy use. Where there is a break in user requests, the data is written from the cache memory to the array. During normal write-back operation, data is written to cache (DRAM), the I/O is acknowledged as “complete” to the application that issued the write, and later the write is flushed to disk. If power is lost while write-back cache is enabled, the writes in DRAM may be lost. Since the controller has already acknowledged the I/O as complete, the application is unaware of the data loss.( Recommended settings for hardware RAID arrays based on HDD).
Write-through:In write-through, data is simultaneously updated to cache and memory. This process is simpler and more reliable. This is used when there are no frequent writes to the cache(The number of write operations is less). It helps in data recovery (In case of a power outage or system failure). A data write will experience latency (delay) as we have to write to two locations (both Memory and Cache). It Solves the inconsistency problem. But it questions the advantage of having a cache in write operation (As the whole point of using a cache was to avoid multiple access to the main memory).
1.2.8 Disk sanitization
Disk sanitization is the process of physically obliterating data with specified byte patterns or random data so that recovery of the original data becomes impossible. Using the sanitization process ensures that no one can recover the data on the disks. Sanitize 支持 Block Erase(块擦除)、Overwrite(覆写)、Crypto Erase(密钥删除)三种类型擦除操作:
Block Erase:从 block 级别,也就是从物理上彻底擦除 SSD 上的数据
Overwrite:用特定的数据格式覆盖用户数据。Overwrite 擦除方式最早在 HDD 上应用,HDD 的数据是存储在带有磁性涂层的金属盘片上,写入新数据可以通过覆写的方式完成。NVMe SSD 时代,协议演进到 NVMe1.3 引入 Sanitize 功能,Overwrite 擦除方式也得以沿用。然而,SSD 的存储介质与 HDD 不同,读取和写入的基本单位不是 HDD 的比特(bit)或字节(byte),而是一个页(Page),新的数据写入需要先擦除(Erase),然后再写入(Program),擦除必须按照块(Block)为单位进行,这无形中会引入额外擦除,从而降低 SSD 寿命。
Crypto Erase:对于支持自加密功能的 SSD,通过删除密钥,使加密数据不可识别。
1.2.9 Disk Secure Erase
Secure Erase and Sanitize both securely erase the data on the SSD and reset the SSD to factory settings. After you Sanitize or Secure Erase SSD, all data will be permanently removed on the solid-state drive and cannot be recovered. But there are some differences between those two methods.
Secure Erase only deletes the mapping table but will not erase all blocks that have been written to. However, Sanitize will delete the mapping table and will erase all blocks that have been written to. Thus, Secure Erase is faster to complete than Sanitize. But not all SSD support Sanitize. For example, if you want to know whether your SanDisk SSD supports Sanitize, you need to refer to the SanDisk SSD Dashboard to check it.
1.2.10 writehole(写洞)
The "write hole" effect can happen if a power failure occurs during the write.
It happens in all the array types, including but not limited to RAID5, RAID6, and RAID1. In this case it is impossible to determine which of data blocks or parity blocks have been written to the disks and which have not. In this situation the parity data does not match to the rest of the data in the stripe. Also, you cannot determine with confidence which data is incorrect - parity or one of the data blocks。
系统故障时(异常掉电等),导致写未完成(非写失败场景),分条内一些分条单元的数据进入了不确定状态,特别的是一些分条的校验单元也进入了不确定状态。当分条处于该状态下,后续的分条写前计算就会出现错误。这种情况,称之为写洞。
将写失败的数据备份在掉电保护区,在适当的时机进行重写,从而解决写洞问题。主要的保护场景:
RAID1,RAID 5、RAID 6、RAID 10、RAID 50,RAID 60支持写洞保护,Write hole数据都保存在掉电保护区,不需要开关控制。
掉电保护装置可用时,Write hole数据异常掉电重启后会进入恢复流程。
掉电保护装置不可用时,记录在掉电保护区的Write hole数据异常掉电后丢失,不做Write hole恢复。
RAID 5掉线盘时不可做写洞保护(原本就降级的RAID组不给做写洞保护)。
RAID 6掉线一块盘时可做写洞保护。
RAID 10、RAID 50、RAID 60部分降级时可做写洞保护,按子组恢复数据。完全降级时不可做写洞保护。
不对RAID 0做写洞保护
板卡上有写洞异常时,会屏蔽RAID卡上报给UEFI的启动项,直连盘的启动项不会被屏
1.2.11 数据掉电保护
开启高速缓存提升写性能(即是write back的开启)的同时,也增大了数据丢失的风险,在整机意外掉电时,高速缓存中的数据将会丢失。
为了提升整机的高读写性能和高速缓存中数据的安全,可为SP686C RAID控制卡配置超级电容。
超级电容保护模块的原理是在发生系统意外掉电时,利用其超级电容供电,将高速缓存中的数据写入超级电容模块中的NAND Flash中,系统再上电时将NAND Flash中的数据刷回到DDR当中。RAID控制卡分为配置超级电容与不配置超级电容两种形态,只有配置超级电容的RAID控制卡支持数据掉电保护功能,即使在不配置超级电容的情况下配置了write back,写操作时也不会根据配置的write back策略来进行,而是根据real write cache=write through来进行。
1.2.12 pinnedcache
备电保护场景中,上电时数据由nandflash回拷至DDR cache中失败会产生pinnedcache(即是原本属于要下发给VD的数据因为异常原因没有下发下去),带pinnedcache
1.2.13 热激活 & 冷激活
RAID卡固件升级分2个步骤:固件下载、固件激活
其中热激活指的是不需要服务器重启,固件立即生效
冷激活指的是要使固件生效,需要服务器AC重启
1.2.13 bootwithpinnedcache
板卡中有pinnedcache时OS(OS无论装在直连还是RAID下)的启动策略:
On: 系统中存在pinned cache时,系统会选择丢弃脏数据并正常启动;
Off: 系统中存在pinned cache时,系统会保留这部分脏数据并正常启动。
但需要用户主动处理这部分脏数据,否则会阻塞一部分系统管理命令,
例如创建LUN、修改读写策略等。
1.2.14 快速初始化
快速初始化,是对VD前后8M写0,即算完成初始化并报盘,后台会继续针对不同的RAID组采取不同的策略(RAID0全写0,其余镜像/冗余RAID组开始后台初始化)继续初始化剩余容量。用户此时是可以对该已上报的盘做操作的,fw会有机制保证RAID组剩余容量的初始化和用户操作不产生串扰,但一定会影响性能。
1.2.15 冗余RAID组的写惩罚机制
1.整条写(Full Stripe Write):
如果一次磁盘写操作的数据正好映射满一个Stripe,则相应的校验值可根据新的数据块的值就直接计算出来,该过程可以在RAID的缓存中直接完成。整条写不需要任何多余的读操作,是RAID5中效率最高的一种写操作。
2.重构写(Reconstruct Write):
如果一次写磁盘的数据包括一个Stripe中的多数个数据块时,则在产生新的校验信息时必须先将没有更新的数据读到缓存中,计算出新的校验信息,然后将新用户数据与新校验信息一起写到磁盘的相应位置。重构写比整条写多一个读旧数据操作,所以其效率比整条写低。
3.读改写(Read-Modify-Write):
如果一次写磁盘的数据包括一个Stripe中的极小部分数据块时,为计算新的校验值,需要先读出Stripe中即将被更新旧数据、旧校验信息,然后与新数据计算校验信息,再将新数据和新校验信息一起写到磁盘上,该操作称为"读改写".
写效率排列顺序为:整条写>重构写>读改写
注:冗余RAID组写原理:依次写各个条带,一个写满再写下一个,对于没有写满的条带也会生成校验数据。随机写相比于顺序写更容易触发写惩罚机制,写并发太小也容易触发写惩罚机制。
二. RAID Level
2.1 RAID 0:

RAID0又称数据分块,即把数据分成若干相等大小的小块,并把它们写到阵列上不同的硬盘上,这种技术又称“Stripping”(即将数据条带化)。把数据分布在多个盘上,在读写时是以并行的方式对各硬盘同时进行操作。从理论上讲,其容量和数据传输率是单个硬盘的N倍。N为构成RAID0的硬盘总数。当然,若阵列控制器有多个硬盘通道时,对多个通道上的硬盘进行RAID0操作,I/O性能会更高。
数据被分成从512字节到数兆字节的若干块后,再交替写到磁盘中。第1块被写到磁盘1中,第2块被写到磁盘2中,如此类推。当系统到达阵列中的最后一个磁盘时,就写到磁盘1的下一分段,如此下去分割数据可以将I/O负载平均分配到所有的驱动器中。由于驱动器可以同时写或读,使得性能显著提高。但是,它却没有数据保护能力。如果一个磁盘出现故障,那么数据就会全盘丢失。
从严格意义上说,RAID 0不是RAID,因为它没有数据冗余和校验。RAID 0技术只是实现了带区组。在实现过程中,RAID 0只是连续地分割数据并行地读/写于多个磁盘上。由于数据块被并行地保存在不同的磁盘上,因此RAID 0具有很高的数据传输率。另外,由于组成RAID 0的所有硬盘空间都可以用来保存数据,因此RAID 0的存储空间利用率也是最高的 。所以RAID 0只适用于类似Video/Audio信号存储、临时文件的转储等对速度要求极其严格的特殊应用。由于没有任何的数据冗余,所以安全性极低,只要RAID里的任何一块磁盘损坏,都会发生所有数据丢失的毁灭性的情况。换句话说,RAID 0模式中,硬盘个数越多,安全性越低。因此,RAID 0不适用于关键任务环境,但是,它却非常适合于视频、图象的制作和编辑。
2.2 RAID 1:
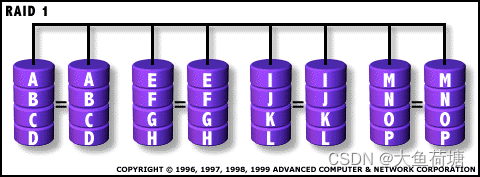
RAID1主要是通过数据镜像实现数据冗余,在两对分离的磁盘上产生互为备份的数据,因RAID 1具有很高的安全性,它甚至可以保证在一半数量的磁盘出现问题时还能不间断地工作,但是整个系统的处理能力会受到影响。不过,由于 RAID 1需要通过两次读写来实现磁盘镜像,这样虽然保证了镜像磁盘随时与原磁盘上的数据完全一致,但是磁盘控制器的负载相当大。另外,RAID 1的数据空间浪费极其严重,是RAID各种等级中成本最高的一种。它只有一半的磁盘空间利用率,只有当系统需要极高的可靠性时,人们才会选择使用RAID 1。因此RAID1常用于对容错要求极严的应用场合。
2.3 RAID 3:
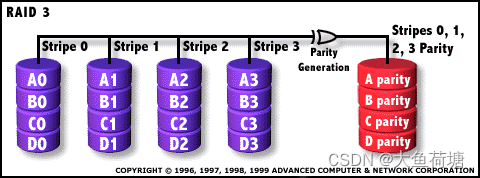
RAID3属于单盘容错并行传输。即采用Stripping技术将数据分块,对这些块进行异或校验,校验数据写到最后一个硬盘上。它的特点是有一个盘为校验盘,数据以位或字节的方式存于各盘(分散记录在组内相同扇区的各个硬盘上)。当一个硬盘发生故障,除故障盘外,写操作将继续对数据盘和校验盘进行操作。而读操作是通过对剩余数据盘和校验盘的异或计算重构故障盘上应有的数据来进行的。RAID3的优点是并行I/O传输和单盘容错,具有很高可靠性。
2.4 RAID 5:
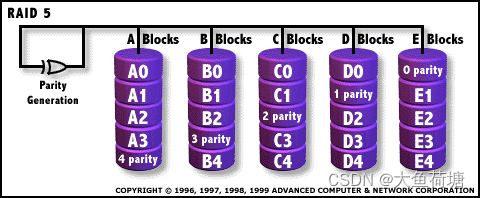
RAID5也被叫做带分布式奇偶位的条带。每个条带上都有相当于一个"块"那么大的地方被用来存放奇偶位。与RAID 3不同的是,RAID 5把奇偶位信息也分布在所有的磁盘上,而并非一个磁盘上,大大减轻了奇偶校验盘的负担。尽管有一些容量上的损失,RAID 5却能提供较为完美的整体性能,因而也是被广泛应用的一种磁盘阵列方案。它适合于输入/输出密集、高读/写比率的应用程序,如事务处理等。为了具有RAID5级的冗余度,我们需要至少三个磁盘组成的磁盘阵列。RAID5可以通过磁盘阵列控制器硬件实现,也可以通过某些网络操作系统软件实现。
2.5 RAID 6:
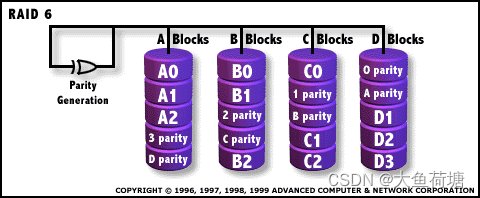
RAID6是带有两种分布存储的奇偶校验码的独立磁盘结构。它使用了分配在不同的磁盘上的第二种奇偶校验来实现增强型的RAID5,它能承受多个驱动器同时出现故障. RRAID6是由一些大型企业提出来的私有RAID级别标准,它的全称叫“Independent Data disks with two independent distributed parity schemes(带有两个独立分布式校验方案的独立数据磁盘)”。这种RAID级别是在RAID 5的基础上发展而成,因此它的工作模式与RAID 5有异曲同工之妙,不同的是RAID 5将校验码写入到一个驱动器里面,而RAID 6将校验码写入到两个驱动器里面,这样就增强了磁盘的容错能力,同时RAID 6阵列中允许出现故障的磁盘也就达到了两个,但相应的阵列磁盘数量最少也要4个.
2.6 RAID 10:
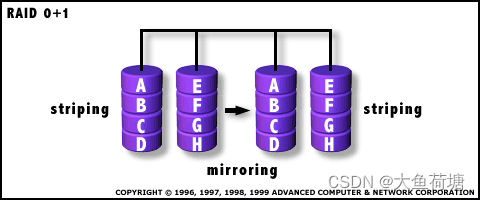
RAID10,也被称为镜象阵列条带,现在我们一般称它为RAID 0+1。RAID 10(RAID 0+1)提供100%的数据冗余,支持更大的卷尺寸。组建RAID 10(RAID 0+1)需要4个磁盘,其中两个为条带数据分布,提供了RAID 0的读写性能,而另外两个则为前面两个硬盘的镜像,保证了数据的完整备份。RAID (0+1) 允许多个硬盘损坏,因为它完全使用硬盘来实现资料备余。RAID 0+1是存储性能和数据安全兼顾的方案。它在提供与RAID 1一样的数据安全保障的同时,也提供了与RAID0近似的存储性能.
2.7 RAID 50:
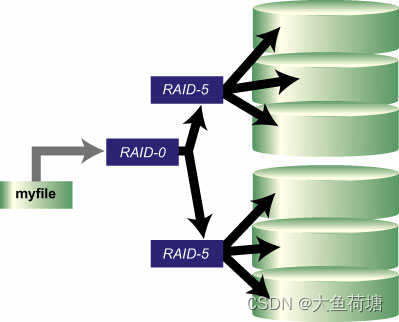
RAID50被称为分布奇偶位阵列条带。它由两组RAID5磁盘组成(每组最少3个),每一组都使用了分布式奇偶位,而两组硬盘再组建成RAID0,实验跨磁盘抽取数据。RAID50提供可靠的数据存储和优秀的整体性能,并支持更大的卷尺寸。即使两个物理磁盘发生故障(每个阵列中一个),数据也可以顺利恢复过来. RAID 50最少需要6个驱动器。
2.8 JBOD(JUST A BUNCH OF DISK):
JBOD方式直接将当前框位号和槽位号的磁盘暴露给主机端,而后主机侧可以对该盘进行操作。
三. RAID 数据保护
3.1 热备盘与冷备盘(hotspare Drive):
如果具有容错冗余能力的 RAID 阵列中坏掉了一块硬盘,RAID 阵列会如何自我进行恢复呢?以 2 盘的 RAID1 为例。假如坏掉了一块盘,RAID1 阵列将只有 1 块盘在正常运行,这时的RAID1 阵列将处于降级(Degraded)状态,也就意味着当前阵列已无容错冗余能力,虽然还能继续行,但是数据已经不安全,需要人为干预进行修复。只需要拔出坏掉的硬盘,换一块相同容量的、好的硬盘插上去,RAID1 阵列就会自动开始恢复重建过程。简单来说,就是将剩余 1 块盘中的数据重新拷贝到新换上的这块盘中。根据硬盘大小的不同,阵列恢复重建过程将从十几小时到几十小时不等。
那么,换上的这块硬盘,不管是从抽屉里拿出来的还是去科技市场买了一块新的,都是通过人为操作插入到整个阵列里的。在出问题之前,这块盘就冷冷的躺在抽屉里而并不会通电,这块盘就叫冷备盘(Cold Spare)。那能不能让阵列自动找一块好的硬盘来替换掉坏掉的盘呢?当然可以
通过热备盘(Hot Spare)实现。简单来说,就是在建好 RAID 阵列后,再向其中插入 1 到多块与阵列中硬盘相同容量的盘,将其设置为 Hot Spare 模式。这些盘在阵列健康的时候就静静的呆在那,也不存数据,也没有读写访问。一旦阵列中有硬盘出问题,阵列处于 Degraded 状态时,RAID控制器会立即激活热备盘,开始阵列的恢复重建工作。
配备热备盘的好处是当阵列出现问题时,可以第一时间启动恢复重建操作,而不必等操作人员发现之后再手动操作。这样就避免了阵列在(降级后,操作人员发现之前)的这段时间内「带病运行」,增加了数据的可靠性。当然,缺点就是又增加了成本。
The hot spare can be of two types:
• Global hot spare-全局热备盘
Use a global hot spare drive to replace any failed drive in a redundant drive group as long as its capacity is equal to or larger than the coerced capacity of the failed drive. A global hot spare defined on any channel should be available to replace a failed drive on both channels.
Global hot spares can be created without first creating a logical drive. If all logical drives are deleted, global hot spares become unconfigured good.
• Dedicated hot spare-本地热备盘,只服务于已经指定的RAID组
Use a dedicated hot spare to replace a failed drive only in a selected drive group. One or more drives can be designated as a member of a spare drive pool. The most suitable drive from the pool is selected for failover. A dedicated hot spare is used before one from the global hot spare pool.Hot spare drives can be located on any RAID channel. Standby hot spares (not being used in RAID drive group) are polled every 60 seconds at a minimum, and their status made available in the drive group management software. RAID controllers offer the ability to rebuild with a disk that is in a system but not initially set to be a hot spare.Observe the following parameters when using hot spares:
• Hot spares are used only in drive groups with redundancy: RAID levels 1, 5, 6, 10, 50, and 60.
• A hot spare connected to a specific RAID controller can be used to rebuild a drive that is connected only to the same controller.
• You must assign the hot spare to one or more drives through the controller BIOS or must use drive group management software to place it in the hot spare pool.
• A hot spare must have free space equal to or greater than the drive it replaces.
For example, to replace a 500-GB drive, the hot spare must be 500-GB or larger.
• A dedicated hot spare becomes a global hot spare if all the logical drives in the drive group that the hot spare is dedicated to are deleted (the drive group is deleted).
3.2 预拷贝(precopy):
预拷贝功能是fw能够通过企业级磁盘设备中一个名为SMART的工具上报故障的状态感知到,从而将即将故障的成员中的数据拷贝到热备盘中.其中,SMART工具提供磁盘自我检测,分析和报告的能力,检测磁盘的健康状况,旋转速度,温度,通电次数,通电数据累计,写错误率等。预拷贝过程主要包括三个步骤:
- 正常使用时,实时监控磁盘状态
- 当某个磁盘疑似出现故障时,将该盘上的数据拷贝到热备盘上去
- 拷贝完成后,若有新盘替换故障盘,再将数据迁移回新盘(回拷)
3.3 重构(rebuild):
重构是指当RAID组中某个磁盘发生故障时,根据RAID中的奇偶校验算法或者镜像策略,用其他正常成员盘的数据重新生成故障磁盘数据的过程。重构内容包括用户数据和校验数据,最终将这些数据写到热备盘或者新替换的磁盘上.在正常情况下,RAID组中出现成员磁盘失效时就会降级状态并触发重构.成功触发重构需要具备如下三个前提:
- 阵列中有成员盘故障或数据失效
- 阵列中配置有热备盘且没有被其他RAID组占用,或者新盘替换了故障盘
- RAID级别应配置成RAID1,RAID3,RAID5,RAID6,RAID10,RAID50等
3.4 回拷(copyBack):
If a member drive of a RAID array with redundancy becomes faulty, the hot spare drive automatically replaces the failed drive and starts data synchronization(即是重构的过程). After a new data drive is installed to replace the faulty one, data is copied from the hot spare drive to the new data drive. As the data copyback is complete, the hot spare drive restores its hot spare state.
3.5 一致性检查(ccheck):
Consistency Check verifies the redundancy is the same across the Virtual Disk members at a redundancy level RAID group. 针对RAID1/RAID5/RAID6/ RAID10/RAID50/RAID60这类具备冗余功能的RAID级别,Consistency Check(一致性检测)对RAID组中的数据进行一致性检测,RAID0没有Consistency Check。
对于RAID1/ RAID10这类基于“镜像”的RAID算法,如果主备成员盘之间的Consistency Check结果不一致,则会记录数据不一致的情况,但是不会进行数据的重新写入操作,原因是RAID卡无法判断哪个数据是正确的。对RAID5/RAID6/RAID50/RAID60,Consistency Check会读取各个成员盘中的数据并做奇偶运算,如果运算结果和校验盘中的数据不一致,则用新生成的数据覆盖校验盘中原数据。
3.6 巡读(patrolread):
Patrol Read check blocks on the drives ,Patrol read involves the review of your system for possible drive errors that could lead to a drive failure and then action to correct errors. The goal is to protect data integrity by detecting drive failure before the failure can damage data. The corrective actions depend on the drive group configuration and the type of errors.
Patrol read cannot be performed on a drive that has any of the following operations in progress:
- RAID hot spare drive recovery
- Dynamic drive expansion
- Full or background initialization
- Consistency check
相较于ccheck:Consistency Check仅仅测试存储阵列中硬盘上包含数据和校验信息的部分,而不是存储阵列中空白区域(无数据和校验信息);Patrol Read检查存储阵列中成员盘的每一个扇区。由于当前硬盘容量越来越大,Patrol Read测试比Consistency Check显得更加重要。Patrol Read可以发现存储阵列中暂无数据和校验信息部分的错误,而这些错误正常是无法发现,直到这些区域被测试或者被写(注:好处是避免对错误区域进行读写)。如果短时间内读写足够多的区域,那么就会达到坏区数量的极限,从而导致Raid Fail(尤其是Rebuid状态)。
至于这两者的功能,Patrol Read可以做Consistency Check大部分任务,由错误读写或者硬盘错误引起的不一致也可以被Patrol Read发现。
3.7 紧急热备(Emergency Hotspare):
After the emergency spare function is enabled for a RAID array that supports redundancy and has no hot spare drive specified, a drive in the Unconfigured Good state will automatically replace a failed member drive and rebuild data to avoid data loss.
3.8 故障修复(error repair):
Writehole类:
修复策略:Clear Data
Pinnedcache类:
修复策略:删除Pinned Cache
Restore类:
firmware error:固件故障
soc fatal:SOC重故障
修复策略:Restore Data
Drop类:
ddr mbit error:DDR Mbit故障
rde error:RDE故障
修复策略:
Drop Data
Bad Card类(不能修复)
故障描述:nfc error:NFC故障
small capacitor abnormal:小电容异常
sram error:SRAM故障
修复策略:
换卡
3.9 自动S.M.A.R.T扫描:
S.M.A.R.T(Self-Monitoring Analysis and Report Technology)即自动检测分析及报告技术,可以对硬盘的磁头单元、盘片电机驱动系统、硬盘内部电路以及盘片表面媒介材料等进行监测,当S.M.A.R.T 监测并分析出硬盘可能出现问题时会及时向用户报警以避免服务器数据丢失。
RAID卡支持周期性对其管理的硬盘进行S.M.A.R.T扫描。扫描周期可通过S.M.A.R.T Polling设置。当扫描到硬盘有SMART error时,RAID卡根据FW策略触发预拷贝功能。

















 4294
4294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









