






一、部署
1、gitee地址:
https://gitee.com/running-elephant/datart
在官网也有更详细的教程可以去看,我这边只展示我用到了的。
2、下载图中的发行版


3、修改配置、创建sql库
(1)创建sql
CREATE DATABASE datart CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
(2)修改配置
解压后 config目录下:我们只需要配置datart.conf下的mysql、以及application-config.yml下的redis。
-
datart.conf为快捷配置文件;如果你只想快速体验 datart 的功能,配置它就足够了。datart.conf本质上是application-config.yml中常用配置的快捷方式。 -
logback.xml为日志配置文件 -
application-config.yml为应用配置文件,包含所有的应用配置。建议将所有的应用配置文件拷贝都放置到profiles目录下
4、部署
${DATART_HOME}/bin/datart-server.sh start # 启动
${DATART_HOME}/bin/datart-server.sh stop # 停止
${DATART_HOME}/bin/datart-server.sh status # 查看状态
${DATART_HOME}/bin/datart-server.sh restart # 重启
二、使用
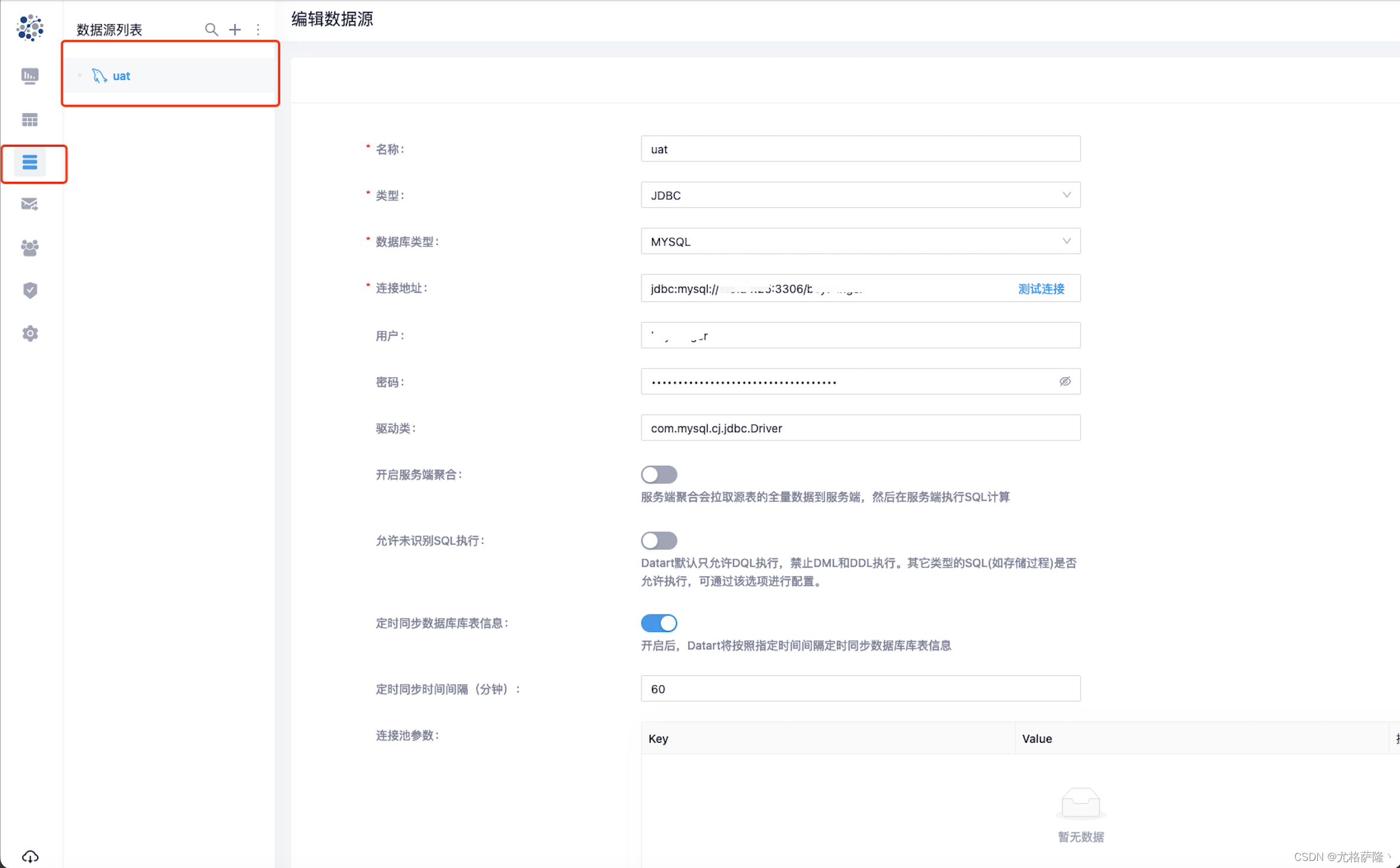
1、连接jdbc
datart 通过 JDBC 连接数据库、获取数据库信息和数据;创建一个 JDBC 数据源通常需要配置以下内容:
- 名称:数据源名称,要求唯一
- 数据库类型:默认支持 30+种 JDBC 数据库。如果你的数据库不在选项中,请参照扩展 JDBC 数据源章节
- 连接地址:通常格式为
jdbc:<数据源名称>://<数据源域名或IP>:(<端口>)/<数据源实例>(?<连接参数>) - 用户
- 密码
- 驱动类:datart 没有内置所有数据库的驱动类,所以当测试连接提示缺少驱动类时,用户需要手动填写驱动类名称
- 开启服务端聚合:开启后,在执行 SQL 时,会将数据视图中 SQL 查询的结果集全量拉取到服务端,然后进行本地分组聚合计算。这个选项适合数据源端计算效率低,或者计算能力弱的数据源进行开启。如果源端本身具有较强的计算能力,则不需要开启这个选项
- 连接池参数:键值对形式
2、数据视图
在数据视图中拼写sql
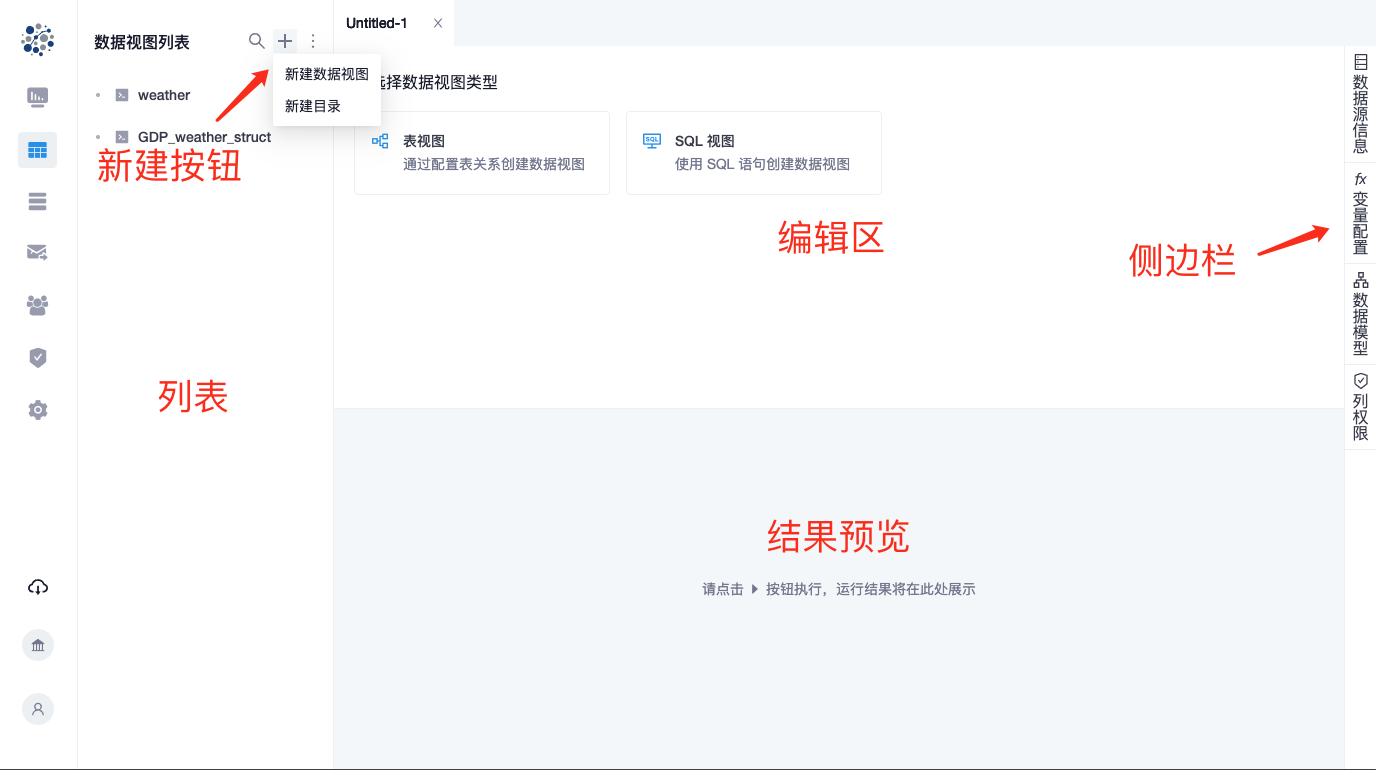
-
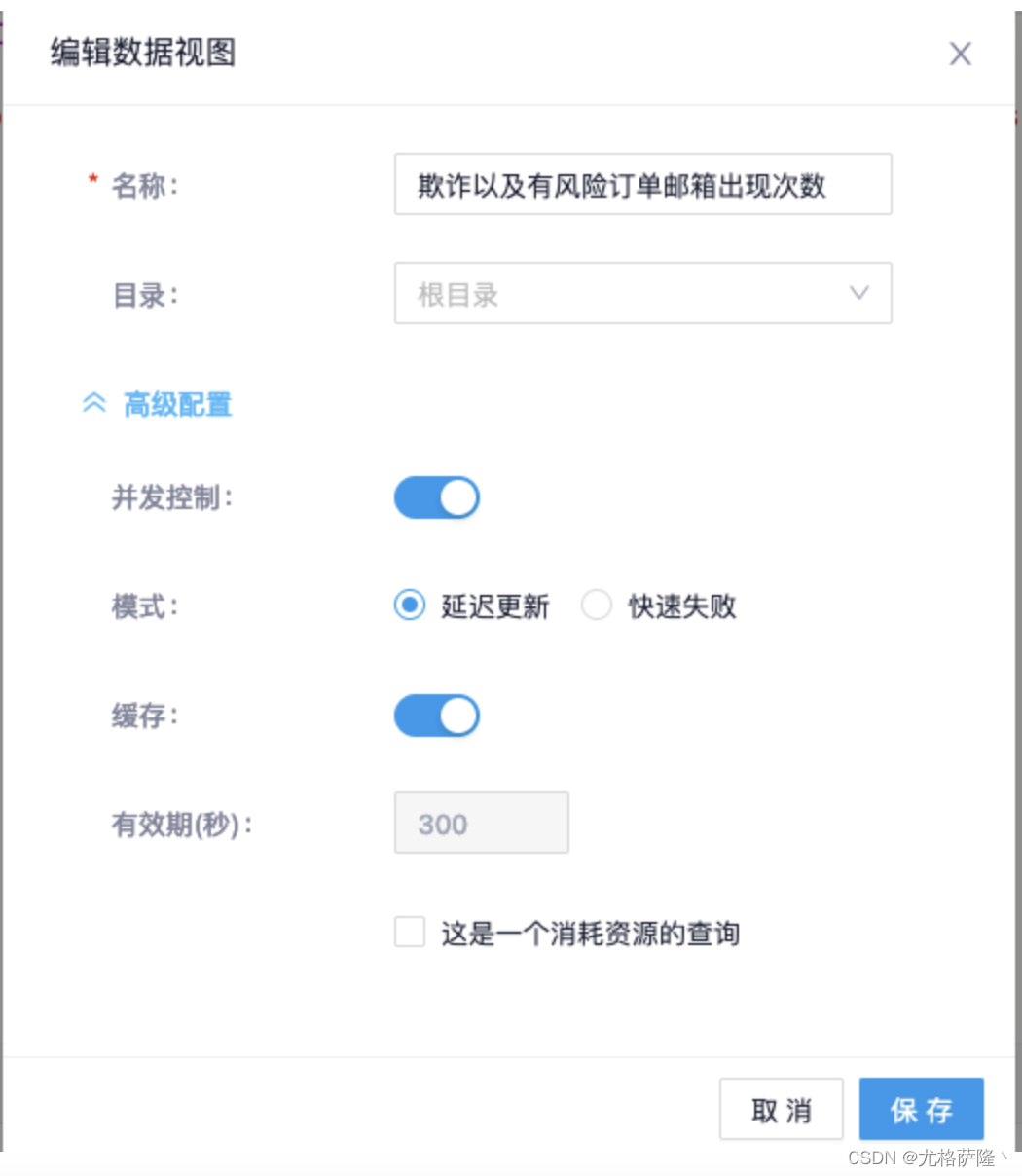
高级配置
(1)延迟刷新:
使用延迟刷新时,来源于同一个数据视图、SQL 语句完全相同的请求,在首次查询没有执行完成的情况下,后续的查询不会真正发送到数据库,而是在服务器队列中处于等待状态;直到首次查询返回结果,服务器会将本次查询结果返回给所有队列中的查询,然后清空队列,进入下一个周期
(2)缓存:
datart 支持缓存查询结果数据,开启之后,在可视化中查询数据时,首次查询结果会被缓存起来,使用 SQL 语句作为索引;在之后缓存有效期内的所有相同 SQL 语句的查询均会直接返回缓存结果
缓存功能同样依赖 Redis,使用缓存功能需要确保 Redis 已正确配置
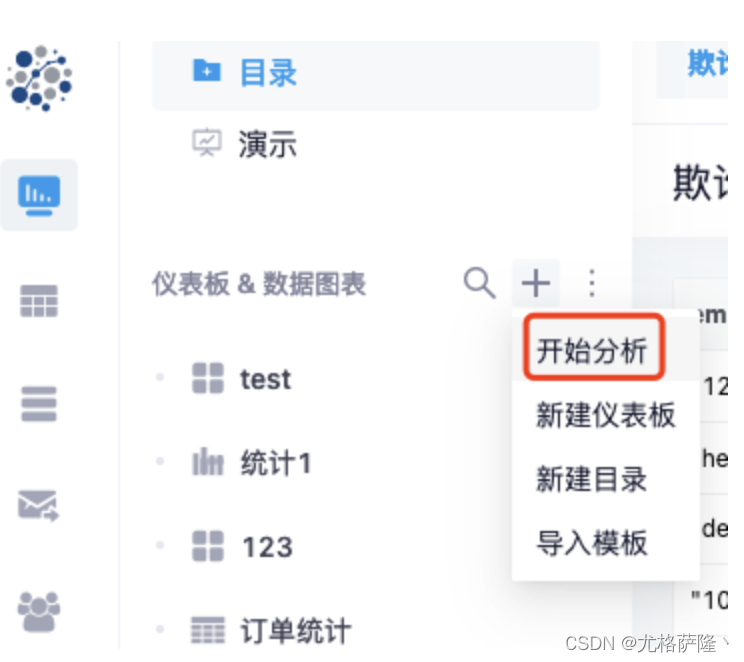
3、数据图表
点击开始分析创建数据图表
这边选择刚才创建的数据视图
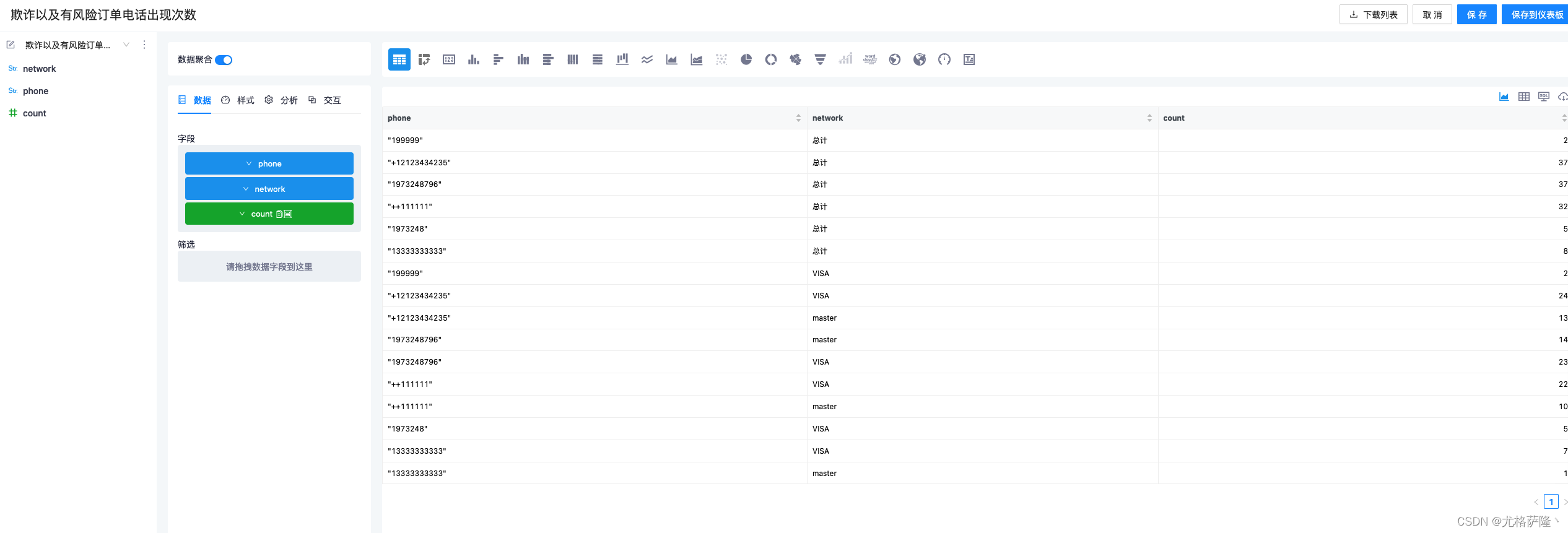
在字段中添加想要的字段。生成图表。
只展示图标,该处还有很多功能,可以去官网查看:https://running-elephant.gitee.io/datart-docs/docs/datachart.html
4、仪表盘
仪表板拥有自动、自由两种布局类型
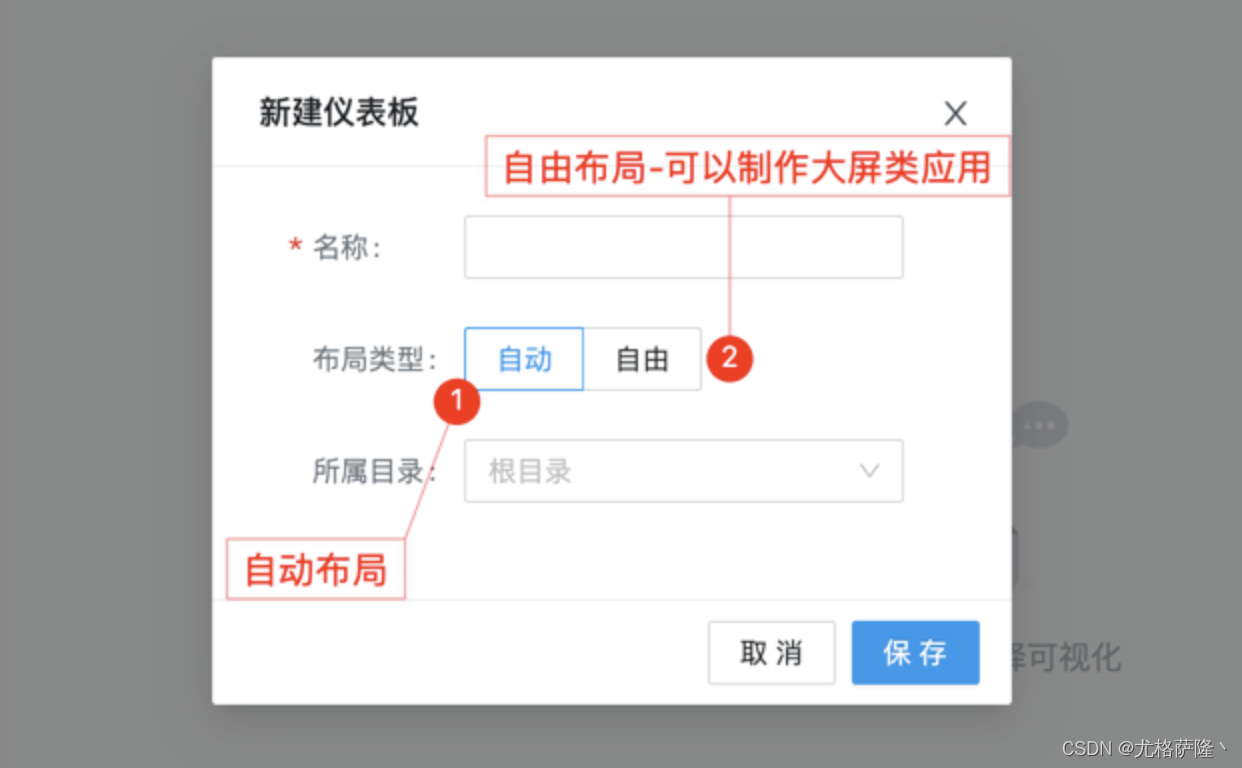
(1)自动布局:
在调整组件尺寸和位置时,其他组件会适应该组件变化进行流式布局
仪表板可视区域宽度在 768 像素以上时组件会按照用户定义的比例进行显示,在 768 像素以下时会响应为移动端观看模式
(2)自由布局:
自由布局可以用来制作大屏类应用,可以设定面板具体尺寸,任意调整组件大小,和位置。并且组件可以上下重叠。
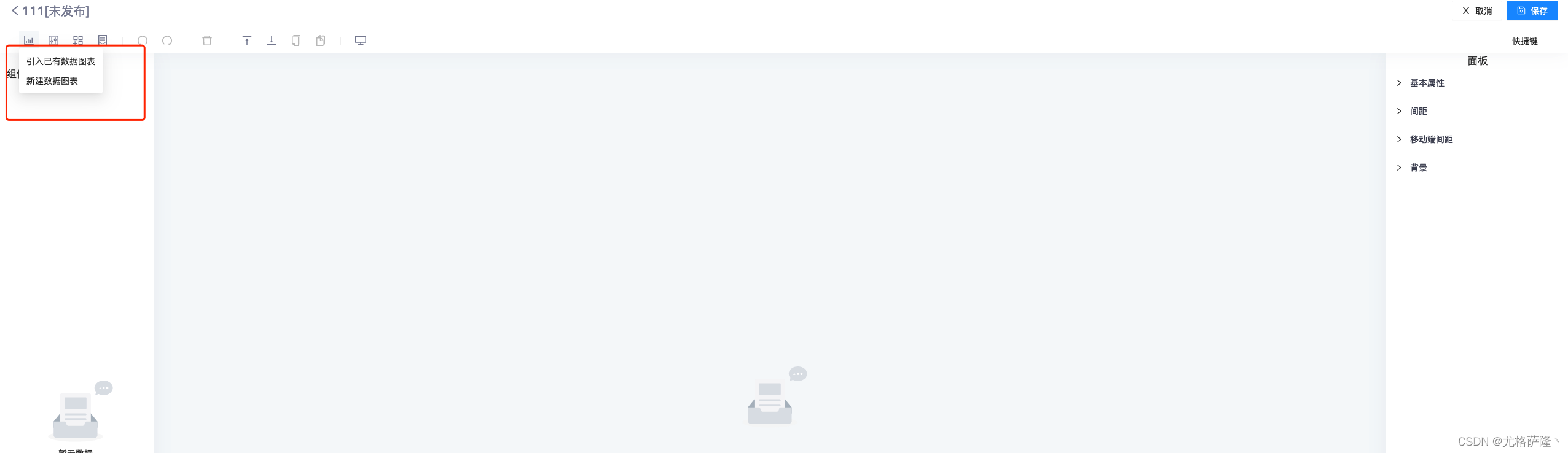
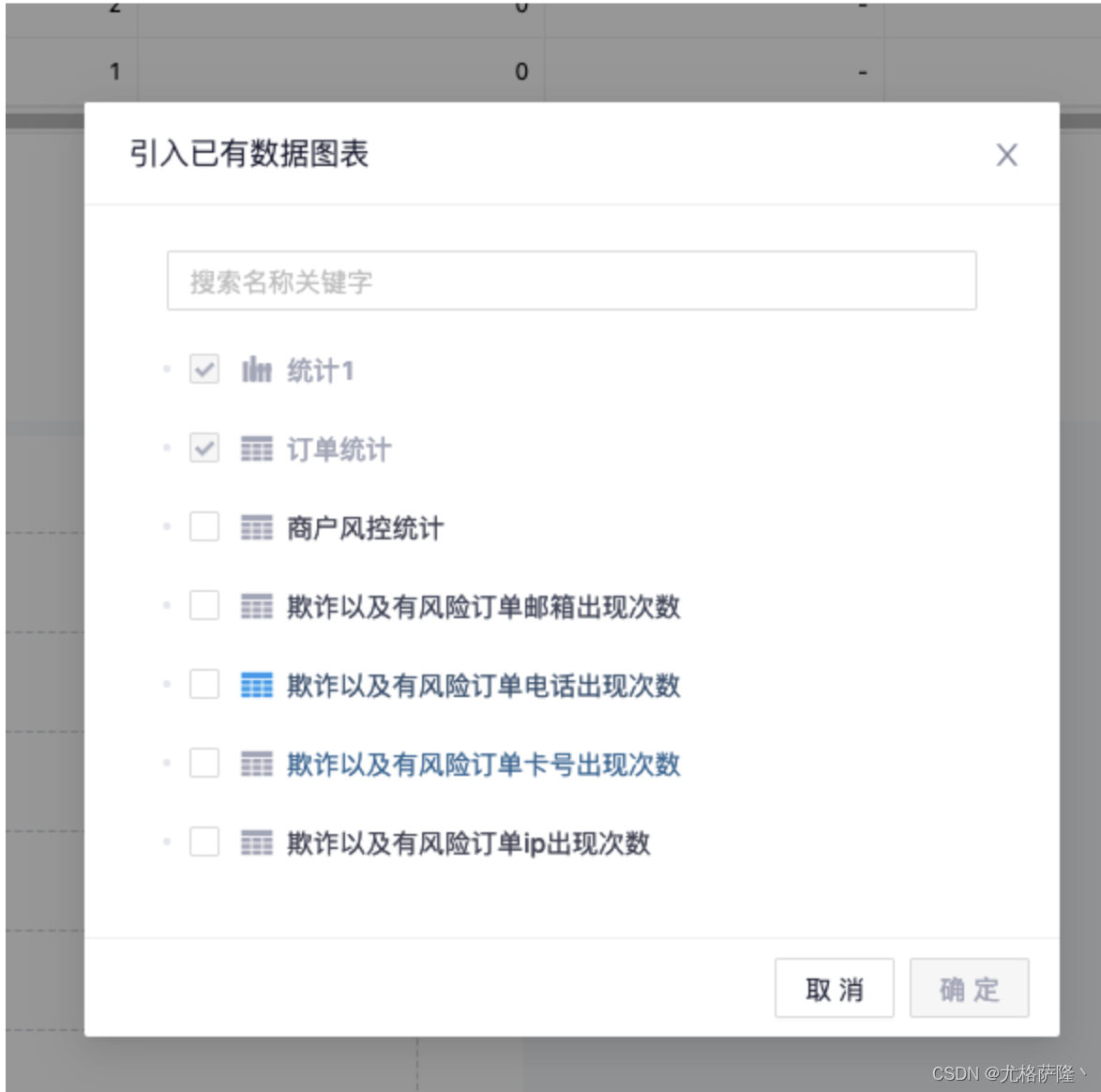
(3)添加数据图表
可自行添加数据图表以及创建数据图表。

















 3179
3179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









