






Python
一、Python基础语法
一个module(python模块,也即一个python文件),module包含:
.py:源文件
.pyc:编译了的文件
.pyo:优化的文件
1、编码
Python3源码文件以UTF-8编码,所有字符串都是unicode字符串
2、标识符
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分由字母、数字和下划线组成。
- 标识符对大小写敏感。
在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也是允许的了。
3、保留字
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
4、注释
#!/usr/bin/python3
# 第一个注释
# 第二个注释
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
"""
print ("Hello, Python!")
5、行与缩进
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数
if True:
print ("True")
else:
print ("False")
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
6、多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠()
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
7、数据类型
(1)变量不需要声明
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
print (counter)
print (miles)
print (name)
#Python允许你同时为多个变量赋值
a = b = c = 1
"""
也可以为多个对象指定多个变量,以上实例,两个整型对象 1 和 2 的分配给变量 a 和 b,字符串对象 "runoob" 分配给变量 c
"""
a, b, c = 1, 2, "runoob"
(2)标准数据类型
Python3 中有六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- **不可变数据(3 个):**Number(数字)、String(字符串)、Tuple(元组);
- **可变数据(3 个):**List(列表)、Dictionary(字典)、Set(集合)。
内置的type() 函数可以用来查询变量所指的对象类型,此外还可以用isinstance来判断
isinstance 和 type 的区别在于:
- type()不会认为子类是一种父类类型。
- isinstance()会认为子类是一种父类类型。
>>> class A:
... pass
...
>>> class B(A):
... pass
...
>>> isinstance(A(), A)
True
>>> type(A()) == A
True
>>> isinstance(B(), A)
True
>>> type(B()) == A
False
python中数字有四种类型:整数、布尔型、浮点数和复数。
- int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
- bool (布尔), 如 True。
- float (浮点数), 如 1.23、3E-2
- complex (复数), 如 1 + 2j、 1.1 + 2.2j
在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加
8、空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
**记住:**空行也是程序代码的一部分
9、字符串
- python中单引号和双引号使用完全相同。
- 使用三引号(’’'或""")可以指定一个多行字符串。
- 转义符 ‘’
- 反斜杠可以用来转义,使用r可以让反斜杠不发生转义。。 如 r"this is a line with \n" 则\n会显示,并不是换行。
- 按字面意义级联字符串,如"this " "is " "string"会被自动转换为this is string。
- 字符串可以用 + 运算符连接在一起,用 * 运算符重复。
- Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python中的字符串不能改变。向一个索引位置赋值,比如word[0] = 'm’会导致错误
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
word = '字符串'
sentence = "这是一个句子。"
paragraph = """这是一个段落,
可以由多行组成"""
str='Runoob'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第五个的字符
print(str[2:]) # 输出从第三个开始后的所有字符
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
print('------------------------------')
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符
print(r'hello\nrunoob') # 在字符串前面添加一个 r,表示原始字符串,不会发生转义
| 字符串操作 | 说明 | 举例 |
|---|---|---|
| string[n:m] | 字符串切片 | string=‘Hello World\n’ string[0] string[:-1] string[3:5] |
| int() | 字符串转数值类型 | int(“123”) float(“123”) |
| str() | 数值类型转字符串 | str(123) str(123.456) |
| ord() | 字符转Unicode码 | ord(‘刘’) |
| chr() | Unicode码转字符 | chr(21016) |
| lower() | 转成小写字符串 | “WELCOME”.lower() |
| upper() | 转成大写字符串 | “welcome”.upper() |
| 字符串操作 | 说明 | 举例 |
|---|---|---|
| in | 判断是否为子串 | ‘or’ in ‘toronto or orlando’ # True |
| find() | 返回子串开始的索引值,找不到子串时返回-1 | s = ‘toronto or orlando’ s.find(‘or’) # return index 1 s.find(‘or’, 2, 8) # return -1, meaning not found |
| index() | 返回子串开始的索引值,找不到子串时抛出异常 | s = ‘toronto or orlando’ s.index(‘or’) # return index 1 s.index(‘or’, 2, 8) # throw ValueError: substring not found |
| count() | 统计字符串里某个字符出现的次数 | s = ‘toronto or orlando’ s.count(‘or’) # return 3 s.count(‘or’, 2) # return 2 s.count(‘or’, 2, 9) # return 0 |
| replace() | 方法把字符串中的 旧字符串替换成新字符串 | s = ‘toronto or orlando’ s.replace(‘or’, ‘/x\’)# result: t/x\onto /x\ /x\lando s.replace(‘or’, ‘/x\’, 2)# result: t/x\onto /x\ orlando |
| 字符串操作 | 说明 | 举例 |
|---|---|---|
| startswith() | 检查字符串是否是以指定子字符串开头 | s = ‘toronto or orlando’ s.startswith(‘or’) # return False s.startswith(‘or’, 1) # return True s.startswith((‘or’, ‘tor’)) # return True |
| endswith() | 检查字符串是否是以指定子字符串结尾 | s = ‘toronto or orlando’ s.endswith(‘and’) # return False s.endswith(‘and’, 1, -1) # return True s.endswith((‘and’, ‘do’)) # return True |
| maketrans() translate() | 字符串转换,maketrans() 设置转换模式,translate()执行转换操作 | s = ‘toronto or orlando’ # define a translation table: table=s.maketrans(‘on’, ‘.N’) # o change to . # n change to N # translate using above table s.translate(table) # result: ‘t.r.Nt. .r .rlaNd.’ |
| 字符串操作 | 说明 | 举例 |
|---|---|---|
| split() | 分割字符串 | words = “WELCOME TO PYTHON”.split() type(words)# list print(words)# [‘WELCOME’, ‘TO’, ‘PYTHON’] words = “WELCOME TO PYTHON”.split(‘O’) print(words)# [’WELC’, ‘ME T’, ’ PYTH’, ‘N’] words = “WELCOME TO PYTHON”.split(’ TO ‘) print(words)# [’WELCOME’, ‘PYTHON’] |
| join() | 将序列中的元素以指定的字符连接生成一个新的字符串 | s = ‘++’ list=[‘1’, ‘2’, ‘3’] s.join(list)# result is ‘1++2++3’ s.join(‘why’)# result is ‘w++h++y’ |
| strip() lstrip() rstrip() | 用于移除字符串头尾/头/尾指定的字符(默认为空格或换行符)或字符序列 | s = ’ “hi\ \n\tPython” ’ s.strip() # result is ‘“hi\ \n\tPython”’ s.strip(’ "no’) # result is ‘hi\ \n\tPyth’ |
10、input输入
input("\n\n按下 enter 键后退出。")
#以上代码中 ,"\n\n"在结果输出前会输出两个新的空行。一旦用户按下 enter 键时,程序将退出
11、同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割,以下是一个简单的实例
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
12、多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之代码组。像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。我们将首行及后面的代码组称为一个子句(clause)
if expression :
suite
elif expression :
suite
else :
suite
13、print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=""
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
14、import 与 from…import
在 python 用 import 或者 from…import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
15、列表[]
list1 = ['Google', 'Runoob', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
list1 = ['Google', 'Runoob', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print ("list1[0]: ", list1[0])
print ("list2[1:5]: ", list2[1:5])
#删除列表元素
del list[2]
| Python 表达式 | 结果 |
|---|---|
| len([1, 2, 3]) | 3 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] |
| 3 in [1, 2, 3] | True |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 |
Python列表函数&方法
| 操作符 | 说明 |
|---|---|
| s[i] = x | 更新指定索引的值 |
| s[i:j] = t | 使用序列t替换s中的i到j的值 |
| del s[i:j] | 等同于s[i:j] = [] |
| s[i:j:k] = t | 使用序列t中的值替换s[i:j:k]的值 |
| del s[i:j:k] | 删除s[i:j:k]的值 |
| s.append(x) | 将值x添加到序列的末尾 |
| s.clear() | 清空序列,相当于del s[:] |
| s.copy() | 创建一个s的浅拷贝 |
| s.extend(t) | 使用序列t扩展序列s |
| s.insert(i, x) | 在序列s的i索引处插入值x |
| s.pop(i) | 返回序列s中索引为i的值,并将该值从序列中移除 |
| s.remove(x) | 将序列中第一个值为x的元素移除 |
| s.reverse() | 将序列s倒序排列 |
列表生成式
用列表生成式创建列表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cdVWNb0h-1602226846318)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1598242085419.png)]
| 需求描述 | 列表生成式 |
|---|---|
| 0~9的平方 | [x**2 for x in range(10) ] |
| 2~99中的偶数 | [x for x in range(2,100) if x % 2 == 0] |
| π的精度逐渐升高 (1~9位小数) | from math import pi [str(round(pi, i)) for i in range(1, 10)] |
| [[ 1, 0, 0, 1 ],[ 0, 1, 1, 0 ], [ 0, 1, 1, 0 ],[ 1, 0, 0, 1 ]] | [[1 if rc or r+c3 else 0 for c in range(4)]for r in range(4)] |
| 字符串’what is this’中出现的字母(生成集合) | sentence = ‘what is this’ { c for c in sentence if c != ’ ’ } |
| 字符串’what is this’中含i单词(生成器表达式) | sentence = ‘what is this’ (w for w in sentence.split() if ‘i’ in w) |
| 字符串’what is this’中单词的辅音字母(生成字典) | sentence = ‘what is this’ { w:{c for c in w if c not in ‘aeiou’} for w in sentence.split() } |
16、集合{}
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
集合生成式:{v for v in input if xxxx}
筛选字符串中的字母
{x for x in ‘abracadabra’ if x not in ‘abc’}
17、字典{}
通过键值对(key-value)来储存数据
储存的数据是无序的,可使用键索引
键是必须唯一,但值可以不唯一
键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
empty_dict = {}
dict_1 = {1:'one', 2:'two', 3:'three'}
dict_2 = dict(one=1, two=2, three=3)
dict = {['Name']: 'Runoob', 'Age': 7}
print ("dict['Name']: ", dict['Name'])
字典内置函数&方法
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> len(dict) 3 |
| 2 | str(dict) 输出字典,以可打印的字符串表示。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> str(dict) "{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} >>> type(dict) <class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | radiansdict.clear() 删除字典内所有元素 |
| 2 | radiansdict.copy() 返回一个字典的浅复制 |
| 3 | radiansdict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | radiansdict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | radiansdict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | radiansdict.keys() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 8 | radiansdict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | radiansdict.values() 返回一个迭代器,可以使用 list() 来转换为列表 |
| 11 | [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的最后一对键和值。 |
字典生成式:{k: v for k,v in input if xxxx }
遍历字典:
(1)遍历键
for k in x.keys()
print(k)
(2)遍历值
for v in x.values():
print(v)
(3)遍历键和值
for k,v in x.items():
print(k,v)
18、元组()
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
>>>tup1 = ('Google', 'Runoob', 1997, 2000)
>>> tup2 = (1, 2, 3, 4, 5 )
>>> tup3 = "a", "b", "c", "d" # 不需要括号也可以
>>> type(tup3)
<class 'tuple'>
#创建空元组
tup1 = ()
#元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用
>>>tup1 = (50)
>>> type(tup1) # 不加逗号,类型为整型
<class 'int'>
>>> tup1 = (50,)
>>> type(tup1) # 加上逗号,类型为元组
<class 'tuple'>
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7 )
print ("tup1[0]: ", tup1[0])
print ("tup2[1:5]: ", tup2[1:5])
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print (tup3)
tup = ('Google', 'Runoob', 1997, 2000)
print (tup)
del tup
print ("删除后的元组 tup : ")
print (tup)
元组运算符
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| (‘Hi!’,) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print (x,) | 1 2 3 | 迭代 |
元组索引,截取
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | ‘Runoob’ | 读取第三个元素 |
| L[-2] | ‘Taobao’ | 反向读取,读取倒数第二个元素 |
| L[1:] | (‘Taobao’, ‘Runoob’) | 截取元素,从第二个开始后的所有元素。 |
元组内置函数
| 序号 | 方法及描述 | 实例 |
|---|---|---|
| 1 | len(tuple) 计算元组元素个数。 | >>> tuple1 = ('Google', 'Runoob', 'Taobao') >>> len(tuple1) 3 >>> |
| 2 | max(tuple) 返回元组中元素最大值。 | >>> tuple2 = ('5', '4', '8') >>> max(tuple2) '8' >>> |
| 3 | min(tuple) 返回元组中元素最小值。 | >>> tuple2 = ('5', '4', '8') >>> min(tuple2) '4' >>> |
| 4 | tuple(iterable) 将可迭代系列转换为元组。 | >>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu'] >>> tuple1=tuple(list1) >>> tuple1 ('Google', 'Taobao', 'Runoob', 'Baidu') |
19、运算符
Python算术运算符
以下假设变量a为10,变量b为21
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的21次方 |
| // | 取整除 - 向下取接近商的整数 | >>> 9//2 4 >>> -9//2 -5 |
Python比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 | (a < b) 返回 True。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 True。 |
Python赋值运算符
以下假设变量a为10,变量b为20
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
Python位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
Python逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
Python成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
Python身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,求余数和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
二、Python语句结构
#if语句
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
#while语句
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
#for语句
sites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
#range
>>>for i in range(5):
... print(i)
...
0
1
2
3
4
#pass,不做任何事情,一般用做占位语句
for letter in 'Runoob':
if letter == 'o':
pass
print ('执行 pass 块')
print ('当前字母 :', letter)
print ("Good bye!")
三、Python函数
1、Python函数特点
(1)函数参数类型多样
(2)允许嵌套函数
(3)无需声明函数返回值类型
(4)yield可以作为函数返回值的关键字
(5)函数能够被赋值给变量
(6)Python中函数是对象
(7)函数可以被引用,即函数可以赋值给一个变量
(8)函数可以当做参数传递
(9)函数可以作返回值
(10)函数可以嵌套
2、定义函数
def 函数名(参数列表):
函数体
3、函数参数类型
(1)无参函数
(2)位置参数
def func_name(arg1,arg2,arg3):
print(arg1,arg2,arg3)
func_name(val1,val2,val3)
(3)关键字参数
def func_name(arg1,arg2,arg3):
print(arg1,arg2,arg3)
func_name(arg1=val1,arg3=val3,arg2=val2)
(4)默认参数
#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )
print ("------------------------")
printinfo( name="runoob" )
(5)包裹位置参数
def func2( *t ) : # t is a tuple
print(t)
func2() # no argument
func2(1,2,3)
func2(1,2,3,4,5)
(6)包裹关键字参数
def func3( **d ) : # d is a dictionary
print(d)
func3() # no argument
func3(a=1, b=2, c=3)
def func5(x, y=10, *args, **kwargs) :
print(x, y, args, kwargs)
func5(0) :
func5(a=1, b=2, y=3, x=4)
func5(1, 2, 3, 4, a=5, b=6)
4、装饰器
def my_decorator(some_func):
def wrapper(*args):
print("I am watching you!")
some_func(*args)
print("You are called.")
return wrapper
@my_decorator
def add(x, y):
print(x,'+',y,'=',x+y)
add(5,6)
5、全局变量与局部变量
(1)全局变量
修改全局变量时,要先使用global关键字声明变量
msg = 'created in module'
def outer() :
def inner() :
global msg
msg = 'changed in inner'
inner()
outer()
print(msg)
(2)局部变量
四、Python面向对象
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- **方法:**类中定义的函数。
- **类变量:**类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- **数据成员:**类变量或者实例变量用于处理类及其实例对象的相关的数据。
- **方法重写:**如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- **局部变量:**定义在方法中的变量,只作用于当前实例的类。
- **实例变量:**在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- **继承:**即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- **实例化:**创建一个类的实例,类的具体对象。
- **对象:**通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
'''
MyClass 类的属性 i 为: 12345
MyClass 类的方法 f 输出为: hello world
'''
类有一个名为 init() 的特殊方法(构造方法),该方法在类实例化时会自动调用,像下面这样:
def __init__(self):
self.data = []
x = MyClass()
#此时构造方法自动调用
当然, init() 方法可以有参数,参数通过 init() 传递到类的实例化操作上。例如:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5
注意:self并不是python的关键字,换成其他名字也可以
'''
Python默认的成员函数和成员变量都是公开的,Python 私有属性和方法没有类似别的语言的public,private等关键词来修饰。 在python中定义私有变量只需要在变量名或函数名前加上 "__"两个下划线,那么这个函数或变量就会为私有的了
'''
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()
#结果为 runoob 说: 我 10 岁。
#类的继承
#一、单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
#另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#二、多重继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中排前地父类的方法
#类方法必须包含参数self,且为第一个参数。也可以使用this,但是最好还是按照约定是用self
五、Python正则表达式
1、正则表达式基础
(1)普通字符
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串 “google runoob taobao” 中所有的 e o u a 字母。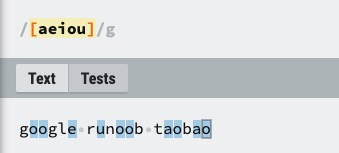 |
| [^ABC] | 匹配除了 […] 中字符的所有字符,例如 [^aeiou] 匹配字符串 “google runoob taobao” 中除了 e o u a 字母的所有字母。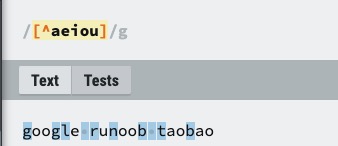 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。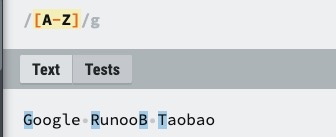 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。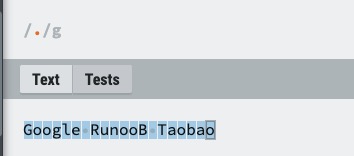 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,包括换行。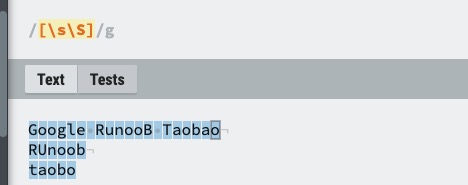 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]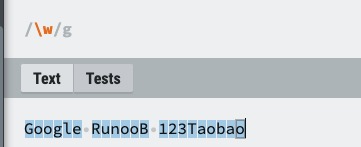 |
(2)非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
(3)特殊字符
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义。
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\’ 匹配 “”,而 ‘(’ 则匹配 “(”。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
(4)限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
以下正则表达式匹配一个正整数,[1-9]设置第一个数字不是 0,[0-9]* 表示任意多个数字:
/[1-9][0-9]*/
(5)定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
(6)选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)。
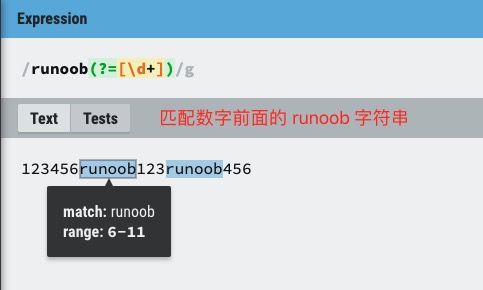
以下列出 ?=、?<=、?!、?<!= 的使用区别
exp1(?=exp2):查找 exp2 前面的 exp1。
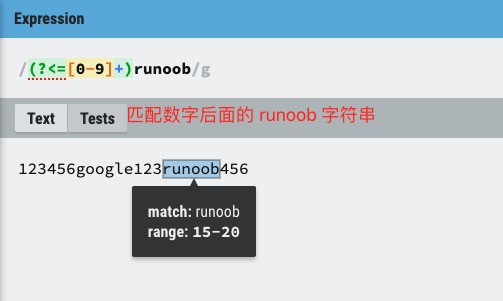
(?<=exp2)exp1:查找 exp2 后面的 exp1。
exp1(?!exp2):查找后面不是 exp2 的 exp1。
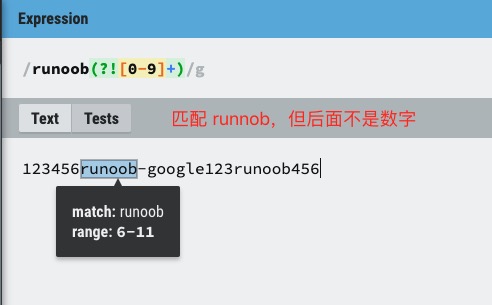
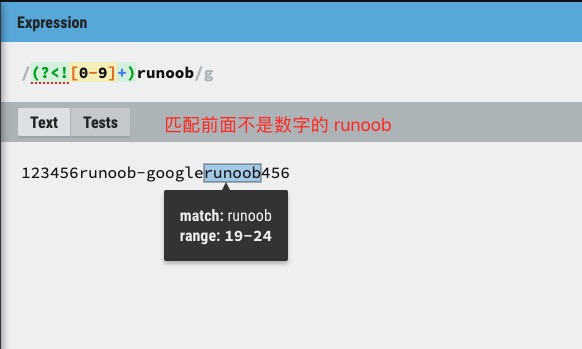
(?<!=exp2)exp1:查找前面不是 exp2 的 exp1。
六、Pyhton爬虫——Scrapy
1、爬虫原理
(1)爬虫开始运行时以一个 URL列表作为爬取的初始入口。从这个 URL列表开始,通用搜索爬虫不断下载网页。
(2)提取下载所得网页中所有的URL。
(3)爬取新提取的URL 对应的网页。
(4)重复步骤(2)和(3)直到将互联网上所有的网页都爬取了一遍,至此,通用搜索爬虫的本次爬取结束。
2、Scrapy安装及项目创建
(1)安装Scrapy
conda install scrapy
(2)配置Scrapy环境变量
将Anaconda的Scripts文件夹加入到Path环境变量中
(3)创建Scrapy项目的命令
在想要保存爬虫项目的目录下输入
cmd命令:scrapy startproject 新工程名
(4)创建Spider
scrapy genspider 爬虫名 start_url
修改parse()方法,在控制台输出文本
(5)启动Spider
scrapy crawl 爬虫名
3、编写Spider文件
打开通过命令行创建的爬虫项目,例如名为minyan2的项目:
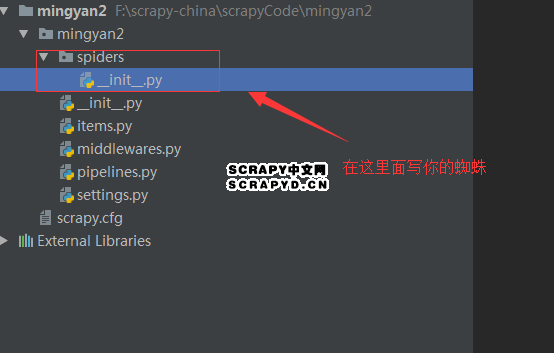
在spiders文件下写一个Python File,例如就叫mingyan_spider.py:
import scrapy
class mingyan(scrapy.Spider): #需要继承scrapy.Spider类
name = "mingyan2" # 定义蜘蛛名
def start_requests(self): # 由此方法通过下面链接爬取页面
# 定义爬取的链接
urls = [
'http://lab.scrapyd.cn/page/1/',
'http://lab.scrapyd.cn/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
#爬取到的页面如何处理?提交给parse方法处理
def parse(self, response):
#标志开始爬取数据
print("Scrapy started")
# 提取整个引言框
quotes = response.xpath("//div[@class='quote']")
# 遍历每一个引言框
for quote in quotes:
# 在引言框中提取引言
quote_text = quote.xpath("./span[@class='text']/text()").extract_first()
# 在引言框中提取about对应的URL
quote_author_url = quote.xpath(".//a/@href").extract_first()
# 在登录状态下才显示的内容
goodreads_url = quote.xpath("./span[2]/a[2]/@href").extract_first()
if goodreads_url is None:
goodreads_url = ""
# url是个相对地址,需要拼接完整后使用
# 请求后由parse_authordetail来处理响应
# 使用meta_data来将quote和对应的authordetail关联在一起
# 因为author会有重复,所以需要关闭Scrapy的自动过滤机制
if quote_author_url is not None:
yield scrapy.Request(self.start_urls[0] + quote_author_url, callback=self.parse_author_detail, dont_filter=True, meta={"quote": quote_text, "goodreads_url": goodreads_url})
# 提取下一页的URL
next_page = response.xpath("//ul[@class='pager']/li[@class='next']/a/@href").extract_first()
# 最后一页没有Next Page按钮,无法获取URL
if next_page is not None:
yield scrapy.Request(self.start_urls[0]+next_page, cookies=self.SCRAPE_COOKIE)
七、Python库
1、NumPy
(1)NumPy简介
NumPy (Numeric Python)是 Python 中科学计算的基础包。它是一个Python库,提供了多维数组对象和各种派生对象,以及快速操作的各种函数,包括数学、逻辑、形状操作、排序、选择、傅立叶变换、基本线性代数、基础统计运算、随机模拟等。
NumPy 的底层使用 C 语言编写,并且在内部实现了对 Python 解释器锁(PIL)的解锁,使其并行运算的效率远高于 Python 的基础数据结构。
(2)NumPy核心——ndarray对象
<1>ndarray特点
{1}存放同类型元素
{2}以0下标为开始
{3}每个元素在内存中都有相同存储大小的区域
<2>ndarray数据类型
| 名称 | 描述 |
|---|---|
| bool | 用一个字节存储的布尔类型(True或False) |
| int 8~64 | 有符号整型 |
| uint 8~64 | 无符号整数 |
| float16~64 | 实型 |
| complex64~128 | 复数,用64或128位分别表示实部与虚部 |
dtype可以自己定义:numpy.dtype(object, align, copy)
- object - 要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体。
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
#首先创建结构化数据类型
import numpy as np
dt = np.dtype([('age',np.int8)])
print(dt)
#将数据类型应用于ndarray对象
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)
#输出结果为[(10,) (20,) (30,)]
print(a['age'])#输出结果为[10 20 30]
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print(student) #输出为[('name', 'S20'), ('age', 'i1'), ('marks', 'f4')]
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
#输出为[('abc', 21, 50.0), ('xyz', 18, 75.0)]
每个内建类型都有一个唯一定义它的字符代码,如下:
| 字符 | 对应类型 |
|---|---|
| b | 布尔型 |
| i | (有符号) 整型 |
| u | 无符号整型 integer |
| f | 浮点型 |
| c | 复数浮点型 |
| m | timedelta(时间间隔) |
| M | datetime(日期时间) |
| O | (Python) 对象 |
| S, a | (byte-)字符串 |
| U | Unicode |
| V | 原始数据 (void) |
<3>ndarray属性
| 属性名 | 描述 |
|---|---|
| dtype | 描述数组中元素的类型 |
| shape | 以 tuple 的形式,表示数组的形状 |
| ndim | 数组的维度 |
| size | 数组中元素的个数 |
| itemsize | 数组中元素在内存所占字节数 |
| T | 数组的转置 |
| flat | 返回一个数组的迭代器,对 flat 赋值将导致整个数组的元素被覆盖 |
| nbytes | 数组占用的存储空间 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
<4>创建ndarray数组
格式:numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
例:
import numpy as np
a = np.array([1,2,3]) #a为[1, 2, 3]
b = np.array([[1,2],[3,4]])
'''
b为[[1, 2]
[3, 4]]
'''
c = np.array([1,2,3,4,5],ndmin=2) #[[1, 2, 3, 4, 5]]时
d = np.array([1,2,3],dtype=complex) #d为[ 1.+0.j, 2.+0.j, 3.+0.j]
import numpy as np
print (np.matrix('1 2; 3 4'))
'''
[[1 2]
[3 4]]
'''
#numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
#numpy.empty(shape, dtype = float, order = 'C')
x = np.empty([3,2], dtype = int)
print (x)
'''
输出为
[[ 6917529027641081856 5764616291768666155]
[ 6917529027641081859 -5764598754299804209]
[ 4497473538 844429428932120]]
'''
#numpy.zeros 创建指定大小的数组,数组元素以 0 来填充:
#numpy.zeros(shape, dtype = float, order = 'C')
# 默认为浮点数
x = np.zeros(5)
print(x) #[0. 0. 0. 0. 0.]
# 设置类型为整数
y = np.zeros((5,), dtype = np.int)
print(y) #[0 0 0 0 0]
# 自定义类型
z = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print(z)
'''
[[(0, 0) (0, 0)]
[(0, 0) (0, 0)]]
'''
#numpy.ones创建指定形状的数组,数组元素以 1 来填充:
#numpy.ones(shape, dtype = None, order = 'C')
# 默认为浮点数
x = np.ones(5)
print(x) #[1. 1. 1. 1. 1.]
# 自定义类型
x = np.ones([2,2], dtype = int)
print(x)
'''
[[1 1]
[1 1]]
'''
#numpy.asarray
#numpy.asarray(a, dtype = None, order = None)
'''
参数 描述
a 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组
dtype 数据类型,可选
order 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
'''
import numpy as np
x = [1,2,3]
a = np.asarray(x)
print (a)
x = (1,2,3)
a = np.asarray(x)
print (a)
#输出结果均为[1 2 3]
x = [(1,2,3),(4,5)]
a = np.asarray(x)
print (a)
# 输出为:[(1, 2, 3) (4, 5)]
x = [1,2,3]
a = np.asarray(x, dtype = float)
print (a)
#输出为[ 1. 2. 3.]
#numpy.arange
#numpy.arange(start, stop, step, dtype)
x = np.arange(5)
print (x)
#输出为[0 1 2 3 4]
x = np.arange(5, dtype = float)
print (x)
#输出为[0. 1. 2. 3. 4.]
x = np.arange(10,20,2)
print (x)
#输出为[10 12 14 16 18]
#numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
#np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
'''
start 序列的起始值
stop 序列的终止值,如果endpoint为true,该值包含于数列中
num 要生成的等步长的样本数量,默认为50
endpoint 该值为 true 时,数列中包含stop值,反之不包含,默认是True。
retstep 如果为 True 时,生成的数组中会显示间距,反之不显示。
dtype ndarray 的数据类型
'''
a = np.linspace(1,10,10)
print(a)
#输出为[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
#numpy.logspace 函数用于创建一个于等比数列。格式如下:
#np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
'''
start 序列的起始值为:base ** start
stop 序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中
num 要生成的等步长的样本数量,默认为50
endpoint 该值为 true 时,数列中中包含stop值,反之不包含,默认是True。
base 对数 log 的底数。
dtype ndarray 的数据类型
'''
a = np.logspace(1.0, 2.0, num = 10)
print (a)
'''
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
'''
a = np.logspace(0,9,10,base=2) #将对数的底数设置为 2 :
print (a)
#[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
<5>ndarray数组方法
| reshape() | 返回展平数组,原数组不改变 |
|---|---|
| resize() | 返回给定 shape 的数组,原数组的 shape 发生改变 |
| flatten() | 返回展平数组,原数组不改变 |
| astype() | 返回指定元素类型的数组副本 |
| fill() | 将数组元素全部设定为一个标量值 |
| sum()/prod() | 计算所有数组元素的和/积 |
| mean()/var()/std() | 返回数组元素的均值/方差/标准差 |
| max()/min()/median() | 返回数组元素的最大值/最小值/取值范围/中位数 |
| argmax()/argmin() | 返回最大值/最小值的索引 |
| sort() | 对数组进行排序,axis 指定排序的轴,kind 指定排序算法,默认 是快速排序 |
| tolist() | 将数组完全转为列表数据类型 |
| compress() | 返回满足条件的元素构成的数组 |
<6>NumPy切片和索引
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引2开始到索引7停止,间隔为2
print(a[s])#结果为[2 4 6]
print(s) #结果为slice(2, 7 ,2)
a = np.arange(10)
b = a[2:7:2] #从索引2开始到索引7停止,间隔为 2
print(b)
'''
冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
'''
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
b = a[5]
print(b) #结果为5
a = np.arange(10)
print(a[2:]) #结果为[2 3 4 5 6 7 8 9]
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a[1:])
'''
结果为:
[[3 4 5]
[4 5 6]]
'''
'''
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
'''
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print (a[...,1]) # 第2列元素
print (a[1,...]) # 第2行元素
print (a[...,1:]) # 第2列及剩下的所有元素
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
#x[row,colunm],行取第0、1、2行,列取第0、1、0列,故取的是矩阵中的x[0,0],x[1,1],x[2,0]
#结果为[1 4 5]
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
#等于取了x[0,0],x[0,2],x[3,0],x[3,2]
'''
[[ 0 2]
[ 9 11]]
'''
# : 或 … 与索引数组组合
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
'''
[[5 6]
[8 9]]
'''
c = a[1:3,[1,2]]
'''
[[5 6]
[8 9]]
'''
d = a[...,1:]
'''
[[2 3]
[5 6]
[8 9]]
'''
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('大于 5 的元素是:')
print (x[x > 5])
'''
大于 5 的元素是:
[ 6 7 8 9 10 11]
'''
a = np.array([1, 2+6j, 5, 3.5+5j])
print (a[np.iscomplex(a)])
#[2.0+6.j 3.5+5.j]
'''
花式索引
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行
'''
x=np.arange(32).reshape((8,4))
print (x[[4,2,1,7]])
#取数组的4,2,1,7行组成新数组
'''
[[16 17 18 19]
[ 8 9 10 11]
[ 4 5 6 7]
[28 29 30 31]]
'''
print (x[[-4,-2,-1,-7]])
'''
[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4 5 6 7]]
'''
<7>ndarray的迭代
import numpy as np
a = np.arange(6).reshape(2,3)
for x in np.nditer(a):
print (x, end=", " )
# 输出:0, 1, 2, 3, 4, 5,
a = np.arange(0,60,5)
a = a.reshape(3,4)
b = a.T # b数组是a数组的转置
c = b.copy(order='C') #行优先
print (c)
for x in np.nditer(c):
print (x, end=", " )
print ('\n')
print ('以 F 风格顺序排序:') #列优先
c = b.copy(order='F')
print (c)
for x in np.nditer(c):
print (x, end=", " )
a = np.arange(0,60,5)
a = a.reshape(3,4)
for x in np.nditer(a, order = 'C'):
print (x, end=", " )
for x in np.nditer(a, order = 'F'):
print (x, end=", " )
for x in np.nditer(a, op_flags=['readwrite']):
x[...]=2*x
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
print ('修改后的数组是:')
for x in np.nditer(a, flags = ['external_loop'], order = 'F'):
print (x, end=", " )
'''
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改后的数组是:
[ 0 20 40], [ 5 25 45], [10 30 50], [15 35 55],
'''
2、Pandas
(1)前提
import numpy as np
import pandas as pd
(2)Pandas数据结构
-
Series,它是一个一维数组对象,类似于NumPy的一维ndarray。Series可存储整数、浮点数、字符串、Python对象等类型的数据。但不同的是,Series除了包含一组数值,还包含一组索引,通俗地可以将它理解为一组带索引的一维数组。

-
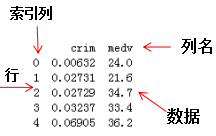
DataFrame,它是一个二维表格型的数据结构。与Excel表格、数据库表非常相似。DataFrame每一列可以看作一个 Series,可以将DataFrame理解为Series的容器
(3)生成Series对象
# 格式:s = pd.Series(data, index=index)
'''
data可以是字典、多维数组、列表等,index是轴标签列表
data 是多维数组时,index 长度必须与 data 长度一致。没有指定 index 参数时,创建数值型索引,即 [0, ..., len(data) - 1]。
'''
s = pd.Series(np.random.randn(5), index=['a','b','c','d','e']) #给定索引
s
Out[4]:
a 0.469112
b -0.282863
c -1.509059
d -1.135632
e 1.212112
dtype: float64
pd.Series(np.random.randn(5)) #默认索引
Out[6]:
0 -0.173215
1 0.119209
2 -1.044236
3 -0.861849
4 -2.104569
dtype: float64
mylist = list('abcedfghijklmnopqrstuvwxyz') # 列表
myarr = np.arange(26) # 数组
mydict = dict(zip(mylist, myarr)) # 字典
# 构建方法
ser1 = pd.Series(mylist)
ser2 = pd.Series(myarr)
ser3 = pd.Series(mydict)
print(ser3.head()) # 打印前5个数据
#> a 0
b 1
c 2
d 4
e 3
dtype:int64
In [7]: d = {'b': 1, 'a': 0, 'c': 2}
In [8]: pd.Series(d)
Out[8]:
b 1
a 0
c 2
dtype: int64
(4)生成DataFrame对象
# 利用Series字典生成DataFrame
In [37]: d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
....: 'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
....:
In [38]: df = pd.DataFrame(d)
In [39]: df
Out[39]:
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
In [41]: pd.DataFrame(d, index=['d', 'b', 'a'], columns=['two', 'three'])
Out[41]:
two three
d 4.0 NaN
b 2.0 NaN
a 1.0 NaN
#用多维数组字典、列表字典生成 DataFrame
In [44]: d = {'one': [1., 2., 3., 4.],
....: 'two': [4., 3., 2., 1.]}
....:
In [45]: pd.DataFrame(d)
Out[45]:
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0
In [46]: pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
Out[46]:
one two
a 1.0 4.0
b 2.0 3.0
c 3.0 2.0
d 4.0 1.0
3、Matplotlib
4、SciPy
| scipy.cluster | Vector quantization / Kmeans |
|---|---|
| scipy.constants | 物理和数学常数 |
| scipy.fftpack | 傅里叶变换 |
| scipy.integrate | 积分 |
| scipy.interpolate | 插值 |
| scipy.io | 文件 |
| scipy.linalg | 线性代数 |
| scipy.ndimage | 多维图像处理 |
| scipy.odr | Orthogonal(正交) distance regression |
| scipy.optimize | 优化 |
| scipy.signal | 信号处理 |
| scipy.sparse | 稀疏矩阵 |
| scipy.spatial | Spatial data structures and algorithms |
| scipy.special | 特殊函数 |
| scipy.stats | 统计 |
5、Sklearn
八、PySpark
1、PySpark体系结构
为了让 Spark 支持 Python,Apache Spark 社区发布了一个工具 PySpark。使用 PySpark,我们可以使用 Python 编程语言处理 RDD。这一切是由一个名为 Py4j的库达到的。PySpark的优势之一是在开发中允许你直接调用Python的内置库和第三方库。如果 Spark 是本地模式,可以直接调用 Python 的第三方库。但如果是集群模式
的话,则会发生错误.原因是 PySpark 需要在各个执行节点的机器上执行操作,而与操作相关的文件存在本地。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3sZkqdss-1602226846331)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1599354477668.png)]
2、PySpark包
(1)Core Classes
pyspark.SparkContext
pyspark.RDD
pyspark.sql.SQLContext
pyspark.sql.DataFrame
(2)pyspark.streaming
pyspark.streaming.StreamingContext
pyspark.streaming.DStream
(3)pyspark.ml
(4)pyspark.mllib
3、PySpark的使用
(1)获得SparkContext对象
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
(2)创建RDD
PySpark没有makeRDD()方法,但常用的textFile()、parallelize()、textFile()、wholeTextFiles()
| parallelize(c, numSlices=None) | sc.parallelize([0, 2, 3, 4, 6], 5).collect() |
|---|---|
| range(start, end=None, step=1, numSlices=None) | sc.range(5).collect() |
| textFile(name, minPartitions=None, use_unicode=True) | sc.textFile(path).collect() |
| wholeTextFiles(path,minPartitions=None, use_unicode=True) | sc.wholeTextFiles(dirPath).collect() |
(3)加载文件
sc.addFile(path)
SparkFiles.get(filename)
#sci.py
def sqrt(num):
return num * num
def circle_area(r):
return 3.14 * sqrt(r)
sc.addPyFile("file:///root/sci.py")
from sci import circle_area
sc.parallelize([5, 9, 21]).map(lambda x : circle_area(x)).collect()
(4)匿名函数
<1>转换算子
map
filter
mapValues
distinct
reduceByKey
groupByKey
sortByKey
union
join
<2>动作算子
count()
collect()
take(num)
first()
reduce
foreach
lookup
max
min
saveAsTextFile
k 社区发布了一个工具 PySpark。使用 PySpark,我们可以使用 Python 编程语言处理 RDD。这一切是由一个名为 Py4j的库达到的。PySpark的优势之一是在开发中允许你直接调用Python的内置库和第三方库。如果 Spark 是本地模式,可以直接调用 Python 的第三方库。但如果是集群模式
的话,则会发生错误.原因是 PySpark 需要在各个执行节点的机器上执行操作,而与操作相关的文件存在本地。
[外链图片转存中…(img-3sZkqdss-1602226846331)]
2、PySpark包
(1)Core Classes
pyspark.SparkContext
pyspark.RDD
pyspark.sql.SQLContext
pyspark.sql.DataFrame
(2)pyspark.streaming
pyspark.streaming.StreamingContext
pyspark.streaming.DStream
(3)pyspark.ml
(4)pyspark.mllib
3、PySpark的使用
(1)获得SparkContext对象
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
(2)创建RDD
PySpark没有makeRDD()方法,但常用的textFile()、parallelize()、textFile()、wholeTextFiles()
| parallelize(c, numSlices=None) | sc.parallelize([0, 2, 3, 4, 6], 5).collect() |
|---|---|
| range(start, end=None, step=1, numSlices=None) | sc.range(5).collect() |
| textFile(name, minPartitions=None, use_unicode=True) | sc.textFile(path).collect() |
| wholeTextFiles(path,minPartitions=None, use_unicode=True) | sc.wholeTextFiles(dirPath).collect() |
(3)加载文件
sc.addFile(path)
SparkFiles.get(filename)
#sci.py
def sqrt(num):
return num * num
def circle_area(r):
return 3.14 * sqrt(r)
sc.addPyFile("file:///root/sci.py")
from sci import circle_area
sc.parallelize([5, 9, 21]).map(lambda x : circle_area(x)).collect()
(4)匿名函数
<1>转换算子
map
filter
mapValues
distinct
reduceByKey
groupByKey
sortByKey
union
join
<2>动作算子
count()
collect()
take(num)
first()
reduce
foreach
lookup
max
min
saveAsTextFile















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









