







 文章介绍了MiLP方法,一种通过参数高效的微调和记忆注入技术,实现在大型语言模型中生成个性化响应的策略。MiLP结合了低秩适应(LoRA)和贝叶斯优化,解决了现有方法在捕获个人健康信息方面的不足,以满足医疗等领域的个性化需求。
文章介绍了MiLP方法,一种通过参数高效的微调和记忆注入技术,实现在大型语言模型中生成个性化响应的策略。MiLP结合了低秩适应(LoRA)和贝叶斯优化,解决了现有方法在捕获个人健康信息方面的不足,以满足医疗等领域的个性化需求。
MiLP:个性化的大模型响应生成
论文:https://arxiv.org/pdf/2404.03565.pdf
代码:https://github.com/MatthewKKai/MiLP
提出背景
1. 引言
主题: 大型语言模型(LLM)的个性化响应生成的潜力与需求。
逻辑链条:
- 个性化需求: 强调个性化模型的潜力,尤其是在医疗等关键领域,对提供根据个人需求定制的响应的重要性。
- 现有尝试: 通过预存储的用户特定信息来引导LLM产生期望输出的尝试,并通过示例比较了增强记忆的LLM与普通LLM的差异。
- 问题识别: 现有方法在捕获细粒度信息方面的局限性,提出是否可以通过激活LLM内不同的记忆来实现个性化响应的问题。
2. PEFT与记忆注入
主题: 参数高效的微调(PEFT)与记忆注入的提案。
具体问题与解法:
-
问题: 全面更新转换器结构的Feed Forward Layers(FFL)参数成本高昂,可能会导致旧知识丢失。
-
解法: 提出使用PEFT和基于贝叶斯优化的搜索策略进行记忆注入(MiLP)。
子解法1: PEFT,之所以使用PEFT子解法,是因为它通过更新或引入一小部分参数的方式,能够在保持LLM大部分预训练权重不变的同时注入知识。例如,Ye et al. (2023) 研究展示了PEFT模块的能力。
子解法2: 贝叶斯优化搜索策略,之所以使用这个子解法,是因为不同的记忆需要不同的参数配置来激活,以达到个性化响应生成。贝叶斯优化能够为多个PEFT模块提供最优配置。
3. 实现个性化的LLM
主题: 通过MiLP实现个性化LLM响应生成的具体实施和贡献。
具体问题与解法:
-
问题: 如何有效实现个性化响应生成,考虑到长期记忆与短期记忆的不同需求。
-
解法: 使用多个PEFT模块和贝叶斯优化策略实现MiLP。
子解法1: 多个PEFT模块,之所以使用此子解法,是因为可以直接将记忆注入到LLM中,而非存储在数据库中。例如,通过LoRA技术实现。
子解法2: 高维多目标贝叶斯优化,之所以使用这个子解法,是因为它能够在复杂的搜索空间中找到注入不同记忆所需的最优配置。
贡献:
- 首次提出直接将记忆注入LLM的方法,为LLM个性化提供了新视角。
- 提出了整合了全面搜索空间和基于贝叶斯优化的方法的MiLP框架,以实现个性化响应生成。
- 通过在三个公开数据集上的实验,证明了MiLP方法的有效性和优越性,与三个基线模型相比显示出显著改进。
假设有一位患者,他有长期的糖尿病历史(长期记忆),并且最近被诊断出缺乏维生素B和维生素C(短期记忆)。
在传统的LLM或基于简单记忆的系统中,当询问如何改善健康状况时,系统可能仅根据最近的查询(例如维生素缺乏)提供一般性建议,如推荐富含维生素B和C的水果。
然而,这样的建议可能忽视了患者需要控制血糖水平的长期记忆要求,从而不适宜推荐含糖量高的水果。
在使用MiLP方法的场景下,情况将大为不同:
-
记忆注入: 首先,通过多个PEFT模块,我们将关于患者的长期和短期医疗记录(如糖尿病历史和维生素缺乏)直接注入到LLM中。
这种方式比在数据库中静态存储患者信息更动态,允许模型更全面地理解患者的健康背景。
-
优化搜索: 接着,使用贝叶斯优化方法在定义的广泛搜索空间中寻找最佳配置。
这一步骤考虑了哪些记忆(长期和短期)应当在生成回应时被激活,以及如何调整模型参数来最佳反映这些记忆。
-
个性化响应生成: 在此基础上,当患者查询如何改善健康状况时,MiLP方法使LLM能够同时考虑到他的糖尿病历史和维生素缺乏情况,推荐低糖且富含维生素B/C的食物选项(例如某些特定的蔬菜),而不是仅仅根据最近的健康状况提供建议。
这个例子展示了MiLP方法如何通过细粒度地理解和整合患者的个人健康信息,生成更加个性化且考虑长期和短期健康需求的回应。
这种方法的应用不仅限于医疗领域,也可以扩展到任何需要个性化建议和回应的场景。
MiLP 方法概述
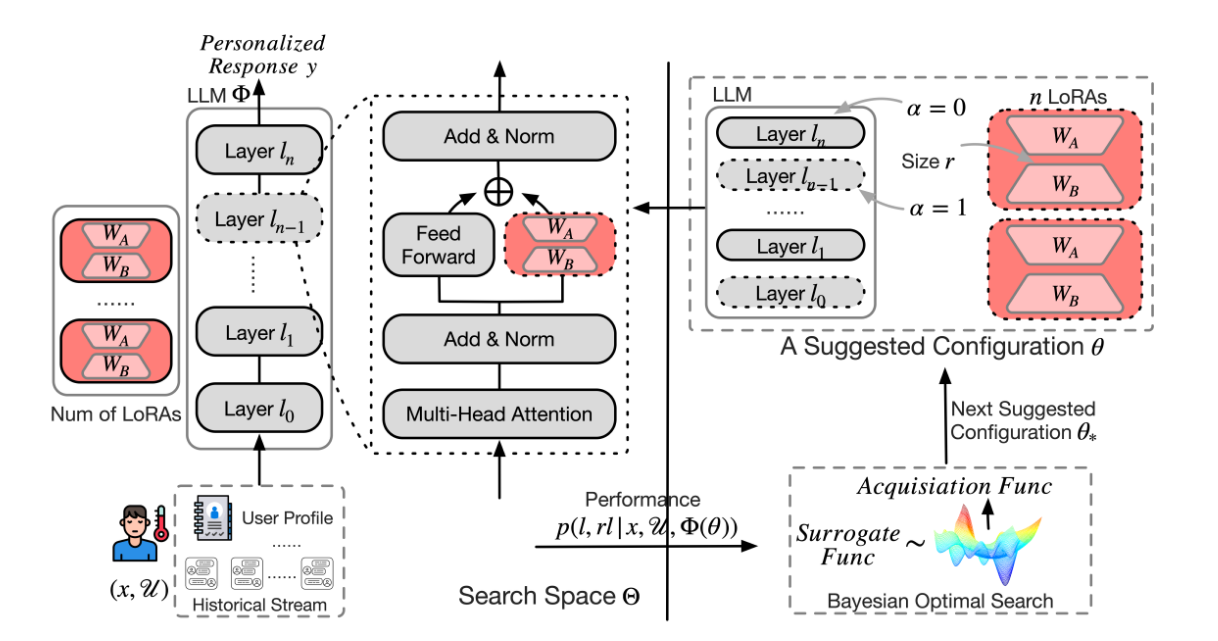
图2展示了MiLP方法的工作流程。它包含了几个关键部分:
-
LLM 结构: 描述了LLM的多层结构,包含添加和标准化(Add & Norm)、前馈(Feed Forward)和多头注意力(Multi-Head Attention)部分。
每一层中都包含了用于记忆注入的低秩适应(LoRA)模块,这些模块由W_A和W_B矩阵组成。
-
搜索空间Θ: 这部分展示了对LLM进行调整的可能配置。
例如,决定在LLM的哪些层插入LoRA模块(通过二进制参数α控制),以及LoRA模块的数量和低秩大小(r)。
-
贝叶斯优化搜索: 一个贝叶斯优化的过程被用于从搜索空间Θ中选择最佳配置θ,用以生成个性化的响应y。
这个过程使用了一个替代函数(Surrogate Func)和获取函数(Acquisition Func),不断地提出新的建议配置θ_*并迭代,直到找到最优解。
图中还强调了用户个人资料和历史内容(U)是如何影响LLM生成个性化响应的关键因素。
主题: 提出的MiLP方法旨在通过用户内容(包括用户资料和历史内容)和查询作为输入,使用低秩适应(LoRA)和改进的贝叶斯优化方法实现记忆注入和搜索,以输出个性化响应。
2.1 记忆注入
具体问题与解法:
-
问题: 如何在LLM中注入知识以实现个性化。
-
解法: 修改Transformer的前馈层,使用低秩适应(LoRA)来实现记忆注入。
子解法1: 低秩适应(LoRA),之所以使用这个子解法,是因为它通过低秩矩阵分解,有效地调整了前馈层的权重,增加了额外的适应能力,同时保持了模型其他部分的稳定性。
2.2 记忆搜索
具体问题与解法:
-
问题: 如何有效地从注入的记忆中检索相关信息以生成个性化响应。
-
解法: 定义搜索空间,并采用贝叶斯优化方法来确定生成个性化响应的最佳配置。
子解法1: 定义搜索空间,之所以这样做,是因为不同的前馈层存储了不同类型的信息,选择哪些层进行LoRA操作可以影响注入的记忆的质量和相关性。
子解法2: 贝叶斯优化搜索,之所以采用这个子解法,是因为它通过概率替代模型和获取函数平衡探索与利用,有效地在高维搜索空间中找到最佳配置。
例子: 如果一个LLM被训练来提供健康建议,通过注入用户的医疗记录和历史查询作为记忆,可以个性化响应用户关于健康问题的查询。
使用LoRA调整特定前馈层可以使模型更好地理解与用户健康状况相关的上下文,而贝叶斯优化则帮助确定最适合该用户特定需求的层的配置,如注入记忆的深度和广度。
MiLP方法通过结合低秩适应和贝叶斯优化,实现了一个高效的个性化LLM响应生成框架。
通过精细调整模型的特定层并优化这些调整,MiLP能够根据用户的具体需求和背景生成更加个性化和精准的响应,特别是在处理包含大量用户特定信息的场景时。
假设有一位糖尿病患者,他使用一个健康咨询的聊天机器人来获取个性化的饮食建议。
此患者的用户资料和历史内容(包括以往对话、糖尿病管理日志等)作为输入数据U = {c0, …, cn},其中包含了他的健康状况、饮食偏好、血糖水平记录等。
患者提出了一个查询x:“我应该如何调整我的饮食来更好地管理我的血糖水平?”
在这个例子中,使用MiLP方法如下:
- 记忆注入
首先,通过将患者的健康信息注入LLM中,我们采用低秩适应(LoRA)技术。
具体来说,针对患者的糖尿病状况和饮食需求,调整LLM的前馈层参数,实现对该患者状况的记忆注入。
例如,如果历史数据显示患者对某些食物有过敏反应,这些信息将通过LoRA技术被注入到模型中。
- 记忆搜索
在记忆注入后,为了生成个性化的饮食建议,使用改进的贝叶斯优化方法来搜索最佳的记忆配置。
这一步考虑到了哪些注入的记忆对当前查询最相关,以及如何结合这些记忆来生成有针对性的建议。
贝叶斯优化通过考虑模型性能(例如,准确性和相关性)和用户满意度来寻找最优解。
个性化响应生成:
最终,基于优化后的模型配置,LLM能够生成一个针对该糖尿病患者特定情况的个性化饮食建议y。
这个建议不仅基于患者的糖尿病状况,还考虑到了他的个人喜好和过敏信息。
例如,建议可能包括低GI(升糖指数)食物,避免患者过敏的食物,并建议根据血糖监测结果调整饮食计划。
这个过程展示了MiLP如何结合用户个人的历史信息和特定查询,通过记忆注入和优化搜索,生成深度个性化的响应,从而为糖尿病患者提供更精准、更有用的健康管理建议。

















 5024
5024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









