







pandas dataframe实现多个不连续的索引
dataframe中可以直接使用loc或iloc索引连续的一个区域,如下所示:
import pandas as pd
data = pd.DataFrame(np.random.random(size=(4,7)),columns=['a','b','c','d','e','f','g'])
print(data.loc[:,['a','c']])
print(data.iloc[:,[0,2,4]])
二者的区别在这篇文章提到:
但若对于不连续的多个区域该如何一步索引?
需要借助.r_()方法
print(data.iloc[:,np.r_[0,2,3:6]])
输出:
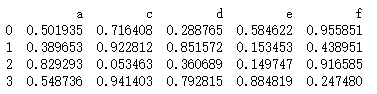
补充:
np.r_与np.c_表示将矩阵分别按照行方向或列方向进行合并,此处使用的是一维的向量,因此默认是按照行的方向,因此使用np.r_即可。
关于np.r_与np.c_区别:numpy矩阵合并中np.r_与np.c_区别















 6808
6808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









