







GP-VAE: Deep Probabilistic Time Series Imputation
作者: Vincent Fortuin, Dmitry Baranchuk, Gunnar Rätsch, and Stephan Mandt
来源: PMLR2020
论文: https://arxiv.org/abs/1907.04155
摘要
在医疗保健和金融等领域,带有缺失值的多元时间序列非常常见,并且随着年份的增长,这些序列的数量和复杂性也不断增加。这引发了一个问题,即在这个领域中,深度学习方法是否能够超越经典的数据插补方法。然而,简单的深度学习应用在可靠性估计和可解释性方面存在不足。我们提出了一种新的深度顺序潜变量模型,用于降维和数据插补。我们的建模假设非常简单且易于理解:高维时间序列具有一个低维表示形式,该表示形式根据高斯过程在时间上平滑演化。在存在缺失数据的情况下,使用具有新颖结构的变分自编码器方法实现非线性降维。我们证明了我们的方法在计算机视觉和医疗保健领域的高维数据上优于多种经典和深度学习的数据插补方法,并且进一步提高了插补的平滑性并提供了可解释的不确定性估计。
介绍
时间序列常常存在缺失值,例如由于测量设备故障、部分观测状态或昂贵的测量程序引起的缺失值[18]。这些缺失值会影响数据的有用性和可解释性,导致数据插补问题:从观测到的数据中估计缺失的值[42]。
多元时间序列由多个相关的单元时间序列或通道组成,产生了两种不同的插补缺失信息的方法:(1) 利用每个通道内的时间相关性,(2) 利用跨通道的相关性,例如使用数据的低维表示。例如在医疗设置中,如果患者的血压未被观察到,当前时间心率高于正常水平,并且一小时前血压也升高,这可能是有信息量的。因此,多元时间序列的理想插补模型应该考虑这两种信息源。这些模型的另一个期望属性是提供概率解释,以允许不确定性估计。
不幸的是,当前的插补方法在至少一个期望方面存在不足。虽然有许多经过时间考验的多元时间序列分析的统计方法(例如,高斯过程[41])在数据完整的情况下表现良好,但这些方法通常不适用于特征缺失的情况。另一方面,时间序列插补的传统方法通常不考虑不同通道之间的可能复杂相互作用[33, 38]。最后,最近的研究探索了使用变分自编码器进行非线性降维的方法来处理缺失值的i.i.d.数据点[1, 35, 37],但这项工作并没有考虑时间数据和跨时间共享统计强度的策略。
基于以上考虑,将非线性降维与表达丰富的时间序列模型相结合是很有前途的。具体方法是通过联合学习将数据空间(其中某些特征是缺失的)映射到潜在空间(其中所有维度都是完整确定的)。然后可以在这个潜在空间中应用所选择的统计模型来建模时间动态。如果动态模型和降维映射都是可微分的,那么这个方法可以进行端到端的训练。
本文中,我们提出了一种架构,使用深度变分自编码器(VAE)将缺失数据的时间序列映射到没有缺失的潜在空间中,在这个潜在空间中使用高斯过程(GP)来建模低维度动态。正如下面我们所讨论的,我们提出了一个能够在多个时间尺度上高效运行的先验模型,考虑到多元时间序列可能具有不同的通道(例如心率、血压等),这些通道可能具有不同的特征频率。最后,我们的变分推断方法使用了高效的结构化变分近似,其中我们使用另一个多元高斯过程来逼近难以计算的真实后验分布。
我们做出以下贡献:
- 一个新的模型。我们提出了一个使用GP先验的VAE架构,用于多变量时间序列插补,以捕捉时间动态。我们提出了一个柯西核,允许时间序列以减小的维度在多个尺度上显示动态。
- 高效的推断。我们使用结构化变分逼近,在时间域建模后验相关性。通过构造,推断是高效的,并且用于训练的变分分布的采样的时间复杂度与时间步数呈线性关系(相对于天真地完成时呈立方关系)。
- 在实际数据上进行基准测试。我们进行了广泛的比较,包括经典插补方法和最先进的深度学习方法,并在两个不同领域的数据上进行实验。我们的方法在两种情况下都表现出有利的性能。
方法
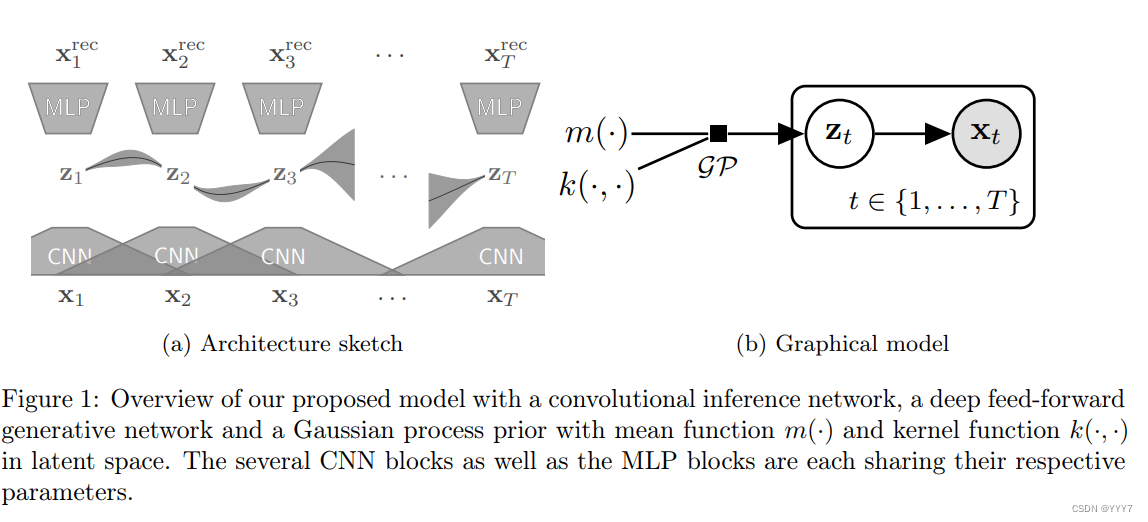
我们提出了一种新颖的架构用于缺失值填充,如图1所示。我们的模型可以看作是在潜在高斯过程模型上执行摊销近似推断的方法。
我们提出的方法的主要思想是将数据嵌入到一个降维的潜在空间中,其中每个维度都是完全确定的,然后在这个潜在空间中建模时间动态。由于数据中的许多特征可能是相关的,潜在表示捕捉这些相关性并将其用于重构缺失值。此外,潜在空间中的高斯过程先验鼓励模型将数据嵌入到一个表示中,其中时间动态比原始数据空间中更平滑且更易解释。最后,推理网络的结构化变分分布使模型能够将时间信息整合到表示中,使得缺失值的重构不仅可以基于同一时间点的相关观察特征,还可以基于整个时间序列。
具体而言,我们将VAE[25],GP[39],Cauchy核[21],高效的结构化变分分布[3]以及用于缺失数据的特殊ELBO[37]的思想相结合,并将这些思想综合成一个缺失数据时间序列填充的通用框架。在接下来的部分中,我们将概述问题设置,描述所假设的生成模型,并推导出我们提出的推断方案。
问题的设置
我们假设一个数据集X ∈ RT ×d,其中T个数据点xt = [xt1, . . . , xtj, . . . , xtd]> ∈ Rd。假设这T个数据点是在连续的时间点τ = [τ1, . . . , τT ]>上测量的,其中τt < τt+1 ∀t。通常,我们设定τ1 = 0。因此,数据X可以被视为在时间上长度为τT的时间序列。我们进一步假设任意数量的数据特征xtj可能是缺失的,即它们的值可能是未知的。现在,我们可以将每个数据点分成观测和未观测特征。数据点xt的观测特征为xto := [xtj | xtj已观测]。等效地,缺失的特征为xtm := [xtj | xtj未观测],其中xto ∪ xtm ≡ xt。我们可以使用这种分区来定义缺失值插补问题。缺失值插补描述了在给定观测特征Xo := [xto]1:T的情况下,估计缺失特征Xm := [xtm]1:T的真实值的问题。许多方法假设不同的数据点是独立的,这种情况下推理问题缩减为估计p(xtm | xto)的T个单独的问题。在时间序列设置中,这种独立性假设是不成立的,这导致了更复杂的估计问题,即估计p(xtm | xo1:T)。
生成模型
RBF核函数
在RBF核函数中,参数r通常表示输入数据点之间的欧几里得距离。具体地说,对于两个输入点 x i x_i xi和 x j x_j xj,它们之间的欧几里得距离为:
r i j = ( x i − x j ) T ( x i − x j ) r_{ij} = \sqrt{(x_i - x_j)^T(x_i - x_j)} rij=(xi−xj)T(xi−xj)
在RBF核函数中,使用这个欧几里得距离的平方来表示两个数据点之间的相似性,即:
k R B F ( r i j ) = exp ( − r i j 2 2 ℓ 2 ) k_{RBF}(r_{ij}) = \exp\left(-\frac{r_{ij}^2}{2\ell^2}\right) kRBF(rij)=exp(−2ℓ2rij2)
其中,参数 ℓ \ell ℓ表示核函数的长度尺度或者时间尺度,控制着核函数的变化速度和相似性函数的平滑度。
RBF和Rational Quadratic kernel的区别
Rational Quadratic kernel 可以考虑多个时间尺度,而 RBF kernel 只能考虑单一的时间尺度。Rational Quadratic kernel 的形式为 k R Q ( r ∣ α , l , σ ) = σ 2 ( 1 + r 2 / ( 2 α l 2 ) ) − α k_{RQ}(r | \alpha, l, \sigma) = \sigma^2 (1 + r^2/ (2\alpha l^2))^{-\alpha} kRQ(r∣α,l,σ)=σ2(1+r2/(2αl2))−α,其中 α \alpha α 表示时间尺度的数量, l l l 表示长度尺度, σ \sigma σ 表示标准差。相比之下,RBF kernel 的形式为 k R B F ( r ∣ l , σ ) = σ 2 exp ( − r 2 / ( 2 l 2 ) ) k_{RBF}(r | l, \sigma) = \sigma^2 \exp(-r^2/(2l^2)) kRBF(r∣l,σ)=σ2exp(−r2/(2l2)),只有一个长度尺度 l l l,没有时间尺度的概念。
Gamma分布
Gamma分布是一种概率分布,通常用来描述连续随机变量的取值情况。它可以用来表示一段时间内发生了多少事件,也可以用来表示某个随机变量的累积和等。
Gamma分布的概率密度函数可以写成以下形式:
p ( λ ∣ α , β ) = 1 Γ ( α ) ( β λ ) α λ α − 1 e − β / λ p(\lambda|\alpha, \beta) = \frac{1}{\Gamma(\alpha)} \left(\frac{\beta}{\lambda}\right)^\alpha \lambda^{\alpha-1} e^{-\beta/\lambda} p(λ∣α,β)=Γ(α)1(λβ)αλα−1e−β/λ
其中, α \alpha α 和 β \beta β 都是分布的参数。 Γ ( α ) \Gamma(\alpha) Γ(α) 表示 Gamma 函数,定义为:
Γ ( α ) = ∫ 0 ∞ t α − 1 e − t d t \Gamma(\alpha) = \int_0^\infty t^{\alpha-1} e^{-t} dt Γ(α)=∫0∞tα−1e−tdt
当 α \alpha α 是整数时,可以直接用阶乘的形式表示,即 Γ ( α ) = ( α − 1 ) ! \Gamma(\alpha) = (\alpha-1)! Γ(α)=(α−1)!。
Gamma分布的期望和方差可以用参数 α \alpha α 和 β \beta β 表示:
E [ λ ] = α β E[\lambda] = \frac{\alpha}{\beta} E[λ]=βα
V a r [ λ ] = α β 2 Var[\lambda] = \frac{\alpha}{\beta^2} Var[λ]=β2α
在该文章中,Gamma分布被用作高斯过程模型中RBF核函数的长度尺度的先验分布。参数 α \alpha α 和 β \beta β 的取值会影响先验分布的形状,从而影响高斯过程模型的拟合效果。
我们通过已经观测到的部分数据来训练模型,并得到了后验分布 q ψ ( z 1 : T ∣ X o , 1 : T ) q_{\psi}(z_{1:T}|X_{o,1:T}) qψ(z1:T∣Xo,1:T),这个分布给出了在已观测数据的条件下,潜在变量 z 1 : T z_{1:T} z1:T 的分布。然后,我们可以使用这个后验分布生成潜在变量 z 1 : T z_{1:T} z1:T 的样本,通过解码器 p θ ( X t ∣ z t ) p_{\theta}(X_{t}|z_{t}) pθ(Xt∣zt) 来生成缺失数据的估计。具体地,我们可以使用后验分布 q ψ ( z 1 : T ∣ X o , 1 : T ) q_{\psi}(z_{1:T}|X_{o,1:T}) qψ(z1:T∣Xo,1:T) 中的样本来代替生成过程中的潜在变量 z 1 : T z_{1:T} z1:T,从而生成缺失数据的估计 X m , 1 : T X_{m,1:T} Xm,1:T。这种方法通常被称为基于生成模型的缺失数据插补方法。
高斯过程
高斯过程(Gaussian Process, GP)是一种用于回归和分类问题的非参数统计模型,它可以看作是对函数空间中潜在函数的先验分布的建模,也就是将函数看作随机变量,通过观察其输入输出的关系来推断函数的分布。
GP的本质是定义了一个概率分布,这个分布描述了函数空间中所有可能函数的分布。对于任意一组输入 x 1 , … , x n x_1,\ldots,x_n x1,…,xn,对应的输出 y 1 , … , y n y_1,\ldots,y_n y1,…,yn,GP 可以用来估计对于新的输入 x n + 1 x_{n+1} xn+1 的输出 y n + 1 y_{n+1} yn+1 的后验分布。
在 GP 中,我们假设 f ( x ) f(x) f(x) 是一个随机函数,且 f ( x ) f(x) f(x) 满足高斯分布,即:
f ( x ) ∼ G P ( m ( x ) , k ( x , x ′ ) ) f(x) \sim GP(m(x), k(x,x')) f(x)∼GP(m(x),k(x,x′))
其中, m ( x ) m(x) m(x) 表示 f ( x ) f(x) f(x) 的均值函数, k ( x , x ′ ) k(x,x') k(x,x′) 表示 f ( x ) f(x) f(x) 和 f ( x ′ ) f(x') f(x′) 之间的协方差函数, x x x 和 x ′ x' x′ 是输入。一般情况下,我们可以设 m ( x ) = 0 m(x) = 0 m(x)=0。
k ( x , x ′ ) k(x,x') k(x,x′) 的具体形式可以根据问题的不同选择不同的核函数,例如常用的 RBF 核函数(Radial Basis Function)为:
k ( x , x ′ ) = σ 2 exp ( − 1 2 l 2 ( x − x ′ ) 2 ) k(x,x')=\sigma^2\exp(-\frac{1}{2l^2}(x-x')^2) k(x,x′)=σ2exp(−2l21(x−x′)2)
其中, σ \sigma σ 表示函数的方差, l l l 表示长度尺度,控制了函数波动的频率。如果 x x x 和 x ′ x' x′ 越接近,它们对应的 f ( x ) f(x) f(x) 和 f ( x ′ ) f(x') f(x′) 之间的相关性就越强。
高斯过程的参数主要是均值函数和协方差函数中的参数,如长度尺度 l l l 和方差 σ 2 \sigma^2 σ2,它们的取值会影响函数的形状和振幅。此外,样本点的分布也会影响高斯过程的预测结果,因为高斯过程是对随机函数的分布进行建模。在实际应用中,需要通过样本点的分布来拟合高斯过程中的参数,以获得更好的预测效果。
推导过程
高斯过程的推导基于一些基本假设:
- 假设我们有一个观测值的集合 D = x ∗ i , y i ∗ i = 1 n \mathcal{D}={\mathbf{x}*i,y_i}*{i=1}^{n} D=x∗i,yi∗i=1n,其中 x i \mathbf{x}_i xi表示输入特征向量, y i y_i yi表示对应的输出值。
- 我们假设这些观测值都是由一个未知的函数 f ( x ) f(\mathbf{x}) f(x)在 x \mathbf{x} x处的取值加上一个噪声项 ϵ \epsilon ϵ得到的: y i = f ( x i ) + ϵ i y_i = f(\mathbf{x}_i) + \epsilon_i yi=f(xi)+ϵi。
- 我们假设噪声项 ϵ i \epsilon_i ϵi是独立同分布的高斯噪声,即 ϵ i ∼ N ( 0 , σ 2 ) \epsilon_i \sim \mathcal{N}(0,\sigma^2) ϵi∼N(0,σ2),其中 σ 2 \sigma^2 σ2是噪声的方差。
对于高斯过程的推导过程,需要从多元高斯分布开始推导。假设 y = [ y 1 , y 2 , … , y n ] T \mathbf{y} = [y_1, y_2, \ldots, y_n]^T y=[y1,y2,…,yn]T是一个 n n n维向量,其服从均值为 μ = [ μ 1 , μ 2 , … , μ n ] T \boldsymbol{\mu} = [\mu_1, \mu_2, \ldots, \mu_n]^T μ=[μ1,μ2,…,μn]T,协方差矩阵为 K \mathbf{K} K的多元高斯分布,即

其中, N \mathcal{N} N表示高斯分布。
接着,考虑一个连续的输入空间 X \mathcal{X} X,并将每一个输入 x x x映射到输出 y ( x ) y(x) y(x)。由于高斯过程是一个分布,我们不仅能够得到一个输出值,而是得到一个输出值的分布。因此,对于任意一组输入 x = [ x 1 , x 2 , … , x n ] T \mathbf{x} = [x_1, x_2, \ldots, x_n]^T x=[x1,x2,…,xn]T,其对应的输出向量 y = [ y ( x 1 ) , y ( x 2 ) , … , y ( x n ) ] T \mathbf{y} = [y(x_1), y(x_2), \ldots, y(x_n)]^T y=[y(x1),y(x2),…,y(xn)]T也是一个多元高斯分布,且有以下的均值和协方差:

其中, k ( x , x ′ ) k(x,x') k(x,x′)表示输入为 x x x和 x ′ x' x′时的协方差函数, μ ( x ) \mu(x) μ(x)表示输入为 x x x时的均值函数。这样,我们就得到了高斯过程的定义。














 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









