






年份: 2023
Github: https://github.com/invictus717/MetaTransformer
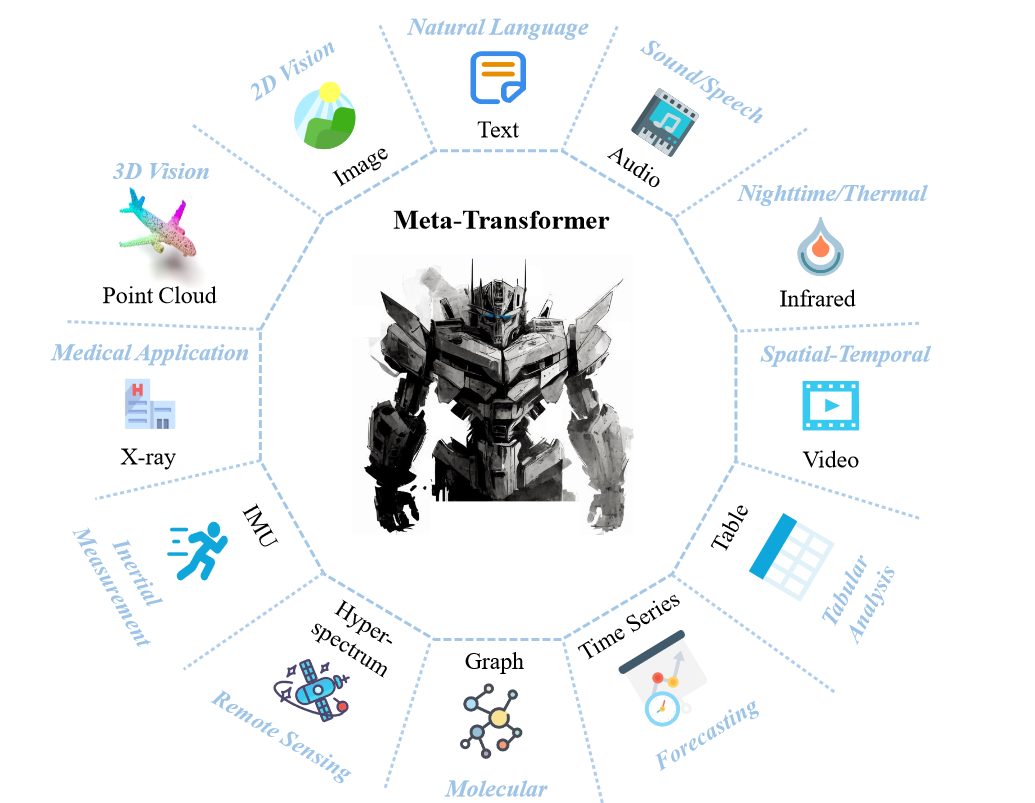
一个统一多模态学习模型。元转换器(Meta-Transformer)利用相同的骨干网络对自然语言、图像、点云、音频、视频、红外、高光谱、X射线、时间序列、表格、惯性测量单元(IMU)和图数据进行编码。
简介:
多模态学习旨在构建可以处理和关联来自多种模态的信息的模型。尽管在这个领域已经进行了多年的发展,但由于它们之间固有的差异,设计一个用于处理各种模态(例如自然语言、2D图像、3D点云、音频、视频、时间序列、表格数据)的统一网络仍然具有挑战性。在这项工作中,我们提出了一个名为Meta-Transformer的框架,它利用一个冻结的编码器在没有任何配对的多模态训练数据的情况下执行多模态感知。在Meta-Transformer中,来自不同模态的原始输入数据被映射到一个共享的标记空间,允许后续具有冻结参数的编码器提取输入数据的高层语义特征。Meta-Transformer由三个主要组件组成:统一数据标记器、模态共享编码器以及用于下游任务的特定任务头。它是第一个可以在12种不配对数据的情况下实现跨模态学习的框架。在不同的基准测试上进行的实验表明,Meta-Transformer可以处理各种任务,包括基础感知(文本、图像、点云、音频、视频)、实际应用(X射线、红外、高光谱和IMU)以及数据挖掘(图形、表格和时间序列)。Meta-Transformer为使用转换器开发统一多模态智能指明了一个有前景的未来。
介绍

人类的大脑被认为是神经网络模型的灵感来源,它同时处理来自各种感官输入的信息,例如视觉、听觉和触觉信号。此外,从一个来源获取的知识可以有助于理解另一个来源的信息。然而,在深度学习中,设计一个能够处理广泛数据格式的统一网络是一个非常复杂的任务,因为它们之间存在显著的模态差距[1-3]。
每种数据模态呈现独特的数据模式,这使得难以将在一种模态上训练的模型适应另一种模态。例如,图像由于像素密集排列而呈现出高度信息冗余,而自然语言则不同[4]。另一方面,点云在3D空间中具有稀疏分布,使其更容易受到噪声的影响并且难以表示[5]。音频谱图是一种随时间变化且非平稳的数据模式,由频率域中的波形组合而成[6]。视频数据包含一系列图像帧,使其能够捕捉空间信息和时间动态[7]。图数据将实体表示为图中的节点,将关系表示为边,建模了实体之间复杂的多对多关系[8]。由于不同数据模态之间的显著差异,通常使用不同的网络架构来分别编码每个模态。例如,Point Transformer [9] 利用向量级的位置注意力从3D坐标中提取结构信息,但不能编码图像、自然语言段落或音频谱图。因此,设计一个能够利用模态共享参数空间来编码多种数据模态的统一框架仍然是一个重要的挑战。最近,像VLMO [2]、OFA [10]和BEiT-3 [3]这样的统一框架的发展通过对配对数据进行大规模多模态预训练[3, 10, 2],提高了网络的多模态理解能力,但它们更加专注于视觉和语言,并且不能在模态之间共享整个编码器。
2017年,Vaswani等人提出的转换器架构和注意机制[11]用于自然语言处理(NLP),在深度学习领域产生了重大影响[11-16]。这些进步在增强不同模态之间的感知能力方面发挥了重要作用,如2D视觉(包括ViT [17, 18]和Swin Transformer [19])、3D视觉(如Point Transformer [9]和Point-ViT [20, 21])以及音频信号处理(AST [6])等。这些研究展示了基于转换器的架构的多功能性,激发了研究人员探索是否可能开发能够统一多种模态的基础模型,最终实现在所有模态上达到人类水平的感知。
在本文中,我们探讨了转换器架构在处理图像、自然语言、点云、音频谱图、视频、红外、高光谱、X射线、IMU、表格、图和时间序列数据等12种模态方面的潜力,如图1所示。我们讨论了每种模态在转换器中的学习过程,并解决了将它们统一到一个框架中面临的挑战。因此,我们提出了一种名为Meta-Transformer的新型统一框架,用于多模态学习。Meta-Transformer是第一个使用相同参数集合同时对来自十二种模态的数据进行编码的框架,从而实现了更加协调的多模态学习方法(如表1所示)。Meta-Transformer包含三个简单有效的组件:用于数据到序列标记化的模态专家(§ 3.2)、用于跨模态提取表示的模态共享编码器(§ 3.3)以及用于下游任务的特定任务头。具体来说,Meta-Transformer首先将多模态数据转换为共享的标记序列空间。然后,一个带有冻结参数的模态共享编码器提取表示,这些表示通过更新下游任务头和轻量级标记器的参数进一步适应到各自的任务中。最后,通过这个简单的框架可以有效地学习特定于任务的和通用于模态的表示。
我们在12种模态的不同基准测试上进行了广泛的实验。通过专门使用LAION-2B [24]数据集的图像进行预训练,Meta-Transformer在处理来自多种模态的数据方面表现出色,在不同多模态学习任务上持续优于现有技术方法。更详细的实验设置可以在§ D中找到。总之,我们的贡献可以总结如下:
- 对于多模态研究,我们提出了一种新颖的框架Meta-Transformer,它使统一编码器能够同时从多种模态中提取表示,并使用相同的参数集合。
- 对于多模态网络设计,我们全面地研究了转换器组件(如嵌入、标记化和编码器)在处理各种模态时的功能。Meta-Transformer提供了有价值的见解,并在开发能够统一所有模态的无模态偏见框架方面开启了一个有前景的新方向。
- 在实验方面,Meta-Transformer在处理12种模态的各种数据集上取得了出色的性能,验证了Meta-Transformer在统一多模态学习方面的进一步潜力。
相关工作
略…
Meta-Transformer
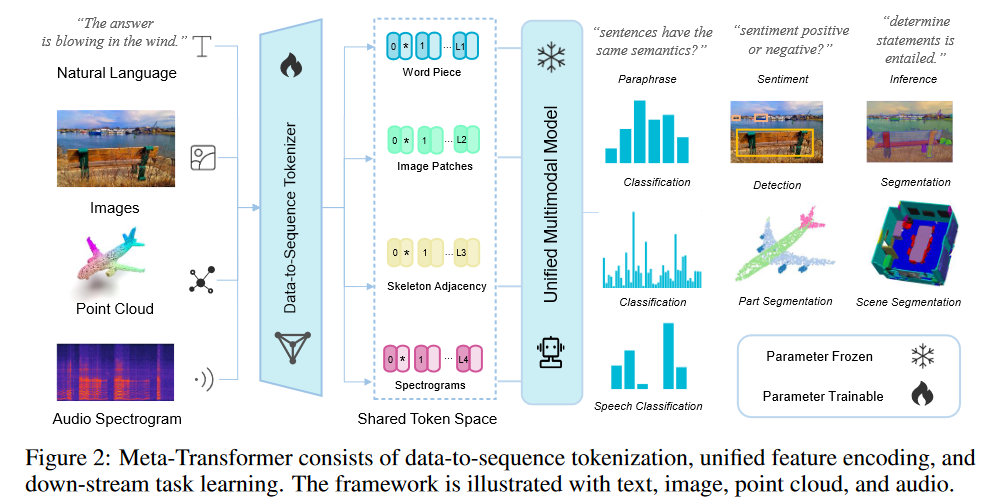
在本节中,我们详细描述了提出的框架Meta-Transformer。Meta-Transformer统一了来自不同模态的数据处理流程,通过共享编码器来完成对文本、图像、点云、音频和其他8种模态的编码。为了实现这一目标,Meta-Transformer由三个组件组成:数据到序列标记器用于将数据投射到共享的嵌入空间,无模态偏见编码器用于对不同模态的嵌入进行编码,以及任务特定头部用于执行下游预测,如图2所示。
Preliminary
形式上,我们用
X
1
,
X
2
,
…
,
X
n
{X_1, X_2, \ldots , X_n}
X1,X2,…,Xn 表示n个模态的输入空间,而
Y
1
,
Y
2
,
…
,
Y
n
{Y_1, Y_2, \ldots , Y_n}
Y1,Y2,…,Yn 则表示相应的标签空间。此外,我们假设每个模态存在一个有效的参数空间
Θ
i
Θ_i
Θi,其中任何参数
θ
i
∈
Θ
i
θ_i ∈ Θ_i
θi∈Θi 都可以用于处理来自该模态的数据
x
i
∈
X
i
x_i ∈ X_i
xi∈Xi。我们称 Meta-Transformer 的本质是找到一个共享的
θ
∗
θ^*
θ∗,满足:
θ
∗
∈
Θ
1
∩
Θ
2
∩
Θ
3
∩
…
Θ
n
θ^* ∈ Θ_1 ∩ Θ_2 ∩ Θ_3 ∩ \ldots Θ_n
θ∗∈Θ1∩Θ2∩Θ3∩…Θn
并假设:
Θ
1
∩
Θ
2
∩
Θ
3
∩
…
Θ
n
≠
∅
Θ_1 ∩ Θ_2 ∩ Θ_3 ∩ \ldots Θ_n \neq \emptyset
Θ1∩Θ2∩Θ3∩…Θn=∅
多模态神经网络可以被表述为一个统一的映射函数
F
:
x
∈
X
→
y
^
∈
Y
F:x ∈ X → \widehat{y} ∈ Y
F:x∈X→y
∈Y,其中
x
x
x 是来自任何模态
X
1
,
X
2
,
…
,
X
n
{X_1, X_2, \ldots , X_n}
X1,X2,…,Xn 的输入数据,而
y
^
\widehat{y}
y
表示网络的预测值。设
y
y
y 为真实标签,多模态流程可以被表述为:
y
^
=
F
(
x
;
θ
∗
)
,
θ
∗
=
arg
min
x
∈
X
[
L
(
y
^
,
y
)
]
\widehat{y} = F (x; θ^*),θ^* = \arg \min_{x∈X} [L(\widehat{y}, y)]
y
=F(x;θ∗),θ∗=argx∈Xmin[L(y
,y)]
Data-to-Sequence Tokenization
我们提出了一种新颖的元标记化方案,旨在将来自各种模态的数据转换为标记嵌入,全部在一个共享的流形空间内进行。此方法应用于标记化,考虑了模态的实际特征,如图3所示。我们以文本、图像、点云和音频为例进行说明。更多细节可在补充材料中找到。
具体而言,我们使用 x T x_T xT, x I x_I xI, x P x_P xP和 x A x_A xA来表示文本、图像、点云和音频谱图的数据样本。
自然语言。 遵循常见做法[51, 65],我们使用包含30,000个标记的WordPiece嵌入[66]。WordPiece将原始单词分割为子词。例如,原始句子:“The supermarket is hosting a sale”,可以被WordPiece转换为:“_The _super market _is _host ing _a _sale”。在这种情况下,单词“supermarket”被分割成了两个子词“_super”和“market”,单词“hosting”被分割成“_host”和“ing”,而其余单词保持不变仍然是单个单位。每个子词对应于词汇表中的一个唯一标记,然后被投影到具有单词嵌入层的高维特征空间。因此,每个输入文本被转换为一组标记嵌入 x ∈ R n × D x \in \mathbb{R}^{n×D} x∈Rn×D,其中 n n n是标记的数量, D D D是嵌入的维度。
图像。 为了适应2D图像,我们将图像
x
∈
R
H
×
W
×
C
x \in \mathbb{R}^{H×W×C}
x∈RH×W×C重新调整为扁平化的2D块序列
x
p
∈
R
N
s
×
(
S
2
⋅
C
)
xp \in \mathbb{R}^{N_s×(S^2·C)}
xp∈RNs×(S2⋅C),其中
(
H
,
W
)
(H, W)
(H,W)表示原始图像分辨率,
C
C
C表示通道数;
S
S
S是块的大小,
N
s
=
(
H
×
W
/
S
2
)
N_s = (H×W/S^2)
Ns=(H×W/S2)是得到的块数。然后,使用投影层将嵌入维度投影为
D
D
D:
x
I
∈
R
C
×
H
×
W
→
x
I
′
∈
R
N
s
×
(
S
2
⋅
C
)
→
x
I
′
′
∈
R
N
s
×
D
.
x_I\in\mathbb{R}^{C\times H\times W}\to x_I^{\prime}\in\mathbb{R}^{N_s\times(S^2\cdot C)}\to x_I^{\prime\prime}\in\mathbb{R}^{N_s\times D}.
xI∈RC×H×W→xI′∈RNs×(S2⋅C)→xI′′∈RNs×D.
请注意,我们对红外图像使用相同的操作,但对高光谱图像使用线性投影。此外,对于视频识别,我们简单地用3D卷积替换2D卷积。更多细节可参见附录B.1和B.3。
点云。 为了使用转换器学习3D模式,我们将点云从原始输入空间转换为标记嵌入空间。
X
=
{
x
i
}
i
=
1
P
X = \{x_i\}_{i=1}^P
X={xi}i=1P表示包含P个点的点云,其中
x
i
=
(
p
i
,
f
i
)
x_i = (p_i, f_i)
xi=(pi,fi),
p
i
∈
R
3
p_i \in \mathbb{R}^3
pi∈R3表示第i个点的3D坐标,
f
i
∈
R
c
f_i \in \mathbb{R}^c
fi∈Rc是第i个点的特征。通常,
f
i
f_i
fi包含视觉提示,如颜色、视角、法线等。我们使用最远点采样(FPS)操作对原始点云进行采样,得到一个具有固定采样比率(1/4)的代表性骨架。然后,我们使用K-最近邻(KNN)将相邻点分组。基于包含局部几何先验信息的分组集合,我们构建了邻接矩阵,其中心点是分组子集的中心点,进一步揭示了3D对象和3D场景的全面结构信息。最后,我们总体的结构表征从K子集。我们获得点嵌入的:
x
P
∈
R
P
×
(
3
+
c
)
→
x
P
′
∈
R
P
4
×
D
2
→
x
P
′
′
∈
R
P
16
×
D
.
x_P\in\mathbb{R}^{P\times(3+c)}\to x_P^{\prime}\in\mathbb{R}^{\frac{P}{4}\times\frac{D}{2}}\to x_P^{\prime\prime}\in\mathbb{R}^{\frac{P}{16}\times D}.
xP∈RP×(3+c)→xP′∈R4P×2D→xP′′∈R16P×D.
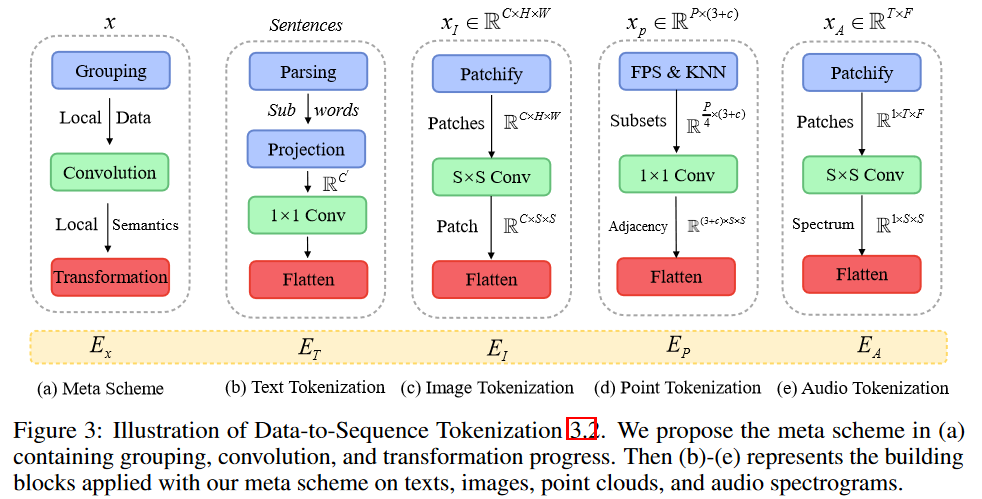
音频谱图。 首先,我们使用对数Mel滤波器组(log Mel filterbank [67])对持续时间为
t
t
t秒的音频波形进行预处理。然后,我们使用汉明窗口对频率为
f
s
f_s
fs的波形进行步长为
t
s
t_s
ts的切分,将原始波形划分为
l
=
(
t
/
t
s
)
l = (t/t_s)
l=(t/ts)个间隔,并进一步将原始波形转换为
l
l
l维滤波器组。
随后,我们将谱图从时间和频率维度切分成大小为
S
S
S的块。与图像块不同的是,音频块在谱图上有重叠。按照AST [6]的方法,我们还选择使用
S
×
S
S \times S
S×S卷积将整个谱图划分为
N
s
=
12
[
100
t
−
16
10
]
N_s = 12 \left[\frac{100t - 16}{10}\right]
Ns=12[10100t−16]个块,然后将这些块扁平化成标记序列。最后,我们总结该过程如下:其中T和F表示时间和频率维度。
x
A
∈
R
T
×
F
→
x
A
′
∈
R
N
s
×
S
×
S
→
x
A
′
′
∈
R
(
N
s
⋅
D
/
S
2
)
×
D
,
x_A\in\mathbb{R}^{T\times F}\to x_A^{\prime}\in\mathbb{R}^{N_s\times S\times S}\to x_A^{\prime\prime}\in\mathbb{R}^{(N_s\cdot D/S^2)\times D},
xA∈RT×F→xA′∈RNs×S×S→xA′′∈R(Ns⋅D/S2)×D,
Unified Encoder
将原始输入转换为标记嵌入空间后,我们利用具有固定参数的统一Transformer编码器来对来自不同模态的标记嵌入序列进行编码。
预训练。 我们使用ViT [13]作为骨干网络,并使用对比学习在LAION-2B数据集上对其进行预训练,从而增强通用标记编码的能力。预训练后,我们冻结骨干网络的参数。此外,为了对文本进行理解,我们使用CLIP [24]的预训练文本标记器将句子分段为子词并将子词转换为单词嵌入。
无模态偏见学习。 遵循常见做法[51, 13],我们在标记嵌入序列前加入可学习的特殊标记
x
C
L
S
x_{CLS}
xCLS,
x
C
L
S
x_{CLS}
xCLS的最终隐藏状态
z
0
L
z_{0}^{L}
z0L作为输入序列的汇总表示,通常用于执行识别任务。为了加强位置信息,我们将位置嵌入(position embeddings)融合到标记嵌入中。由于我们将输入数据标记化为1D嵌入,因此我们采用标准的可学习1D位置嵌入。此外,我们在图像识别中并未观察到使用更复杂的2D位置嵌入会带来显著性能改进。我们简单地通过逐元素的加法操作将位置嵌入和内容嵌入融合在一起,然后将得到的嵌入序列输入到编码器中。
具有深度
L
L
L的Transformer编码器由多个堆叠的多头自注意力(MSA)层和MLP块组成。输入的标记嵌入首先经过一个MSA层,然后经过一个MLP块。然后,第(ℓ-1)个MLP块的输出作为第ℓ个MSA层的输入。
在每个层之前加入Layer Normalization (LN),并在每个层之后应用残差连接。MLP包含两个线性全连接层和一个GELU非线性激活函数。Transformer的公式为:
zo
=
[
x
C
L
S
;
E
x
1
;
E
x
2
;
⋯
;
E
x
n
]
+
E
p
o
s
,
E
∈
R
n
×
D
,
E
p
o
s
∈
R
(
n
+
1
)
×
D
z
e
=
M
S
A
(
L
N
(
z
ℓ
−
1
)
)
+
z
ℓ
−
1
,
ℓ
=
1
…
L
z
ℓ
=
M
L
P
(
L
N
(
z
ℓ
′
)
)
+
z
ℓ
′
,
ℓ
=
1
…
L
′
=
L
N
(
z
L
0
)
\begin{aligned} &\text{zo} =[x_{\mathrm{CLS}};\boldsymbol{E_{x_1}};\boldsymbol{E_{x_2}};\cdots;\boldsymbol{E_{x_n}}]+\boldsymbol{E_{pos}}, && E\in\mathbb{R}^{n\times D},E_{pos}\in\mathbb{R}^{(n+1)\times D} \\ &z_e =\mathrm{MSA}(\mathrm{LN}(\boldsymbol{z}_{\ell-1}))+\boldsymbol{z}_{\ell-1}, && \ell=1\ldots L \\ &\text{z} _\ell=\mathrm{MLP}(\mathrm{LN}(z_{\ell}^{\prime}))+z_{\ell}^{\prime}, && \ell=1\ldots L \\ &\prime=\mathrm{LN}(\boldsymbol{z}_{L}^{0}) \end{aligned}
zo=[xCLS;Ex1;Ex2;⋯;Exn]+Epos,ze=MSA(LN(zℓ−1))+zℓ−1,zℓ=MLP(LN(zℓ′))+zℓ′,′=LN(zL0)E∈Rn×D,Epos∈R(n+1)×Dℓ=1…Lℓ=1…L
其中
E
x
E_x
Ex表示来自提议的标记器的标记嵌入,
n
n
n表示标记的数量。我们使用位置嵌入
E
pos
E_{\text{pos}}
Epos来增强块嵌入和可学习嵌入。
Task-Specific Heads
在获得学习表示后,我们将这些表示馈送到任务特定的头部
h
(
⋅
;
θ
h
)
h(·; θ_h)
h(⋅;θh),这些头部主要由MLP组成,并根据不同的模态和任务而变化。Meta-Transformer的学习目标可以总结为:
y
^
=
F
(
x
;
θ
∗
)
=
h
∘
g
∘
f
(
x
)
,
θ
∗
=
arg
min
θ
L
(
y
^
,
y
)
,
\hat{\boldsymbol{y}}=\mathcal{F}(\boldsymbol{x};\theta^{*})=h\circ g\circ f(\boldsymbol{x}),\quad\theta^{*}=\arg\min_{\theta}\mathcal{L}(\hat{y},y),
y^=F(x;θ∗)=h∘g∘f(x),θ∗=argθminL(y^,y),
其中,
f
(
⋅
)
f(·)
f(⋅),
g
(
⋅
)
g(·)
g(⋅)和
h
(
⋅
)
h(·)
h(⋅)分别表示标记器、骨干网络和头部的函数。
实验
此处不在翻译详细的实验结果分析。
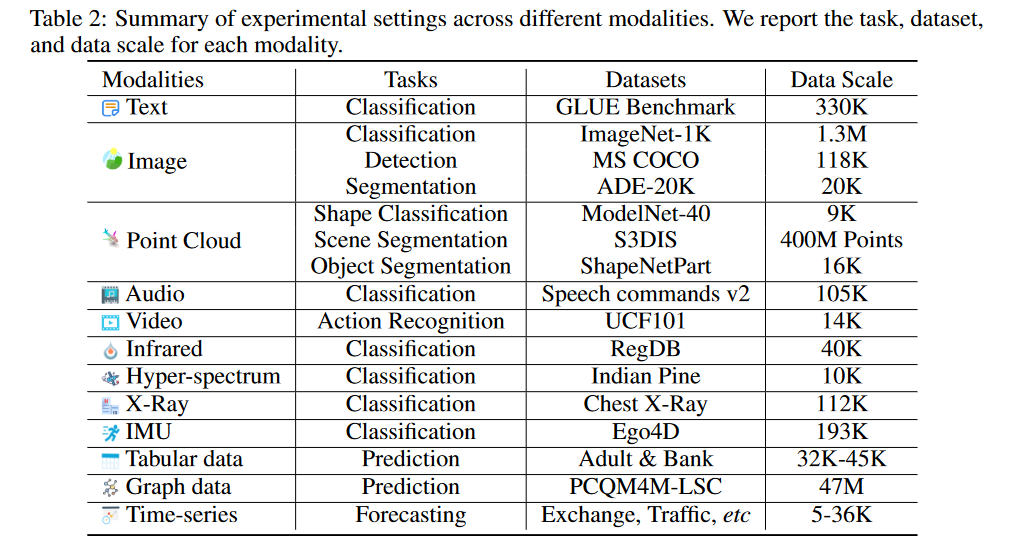
本文所使用的数据集:
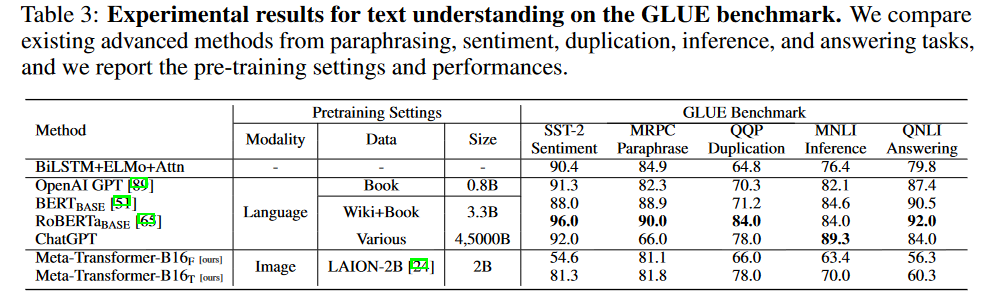
文本实验结果:
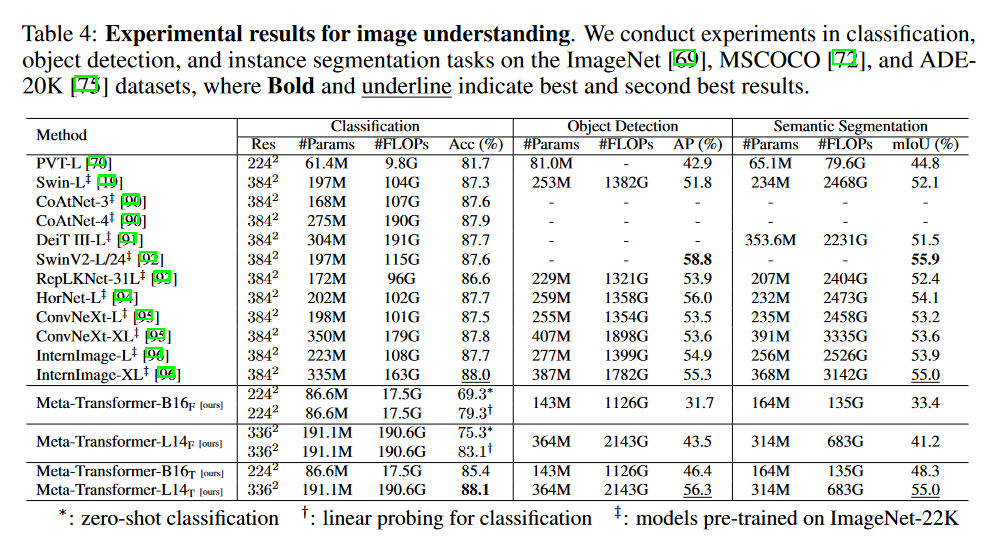
图像实验结果:
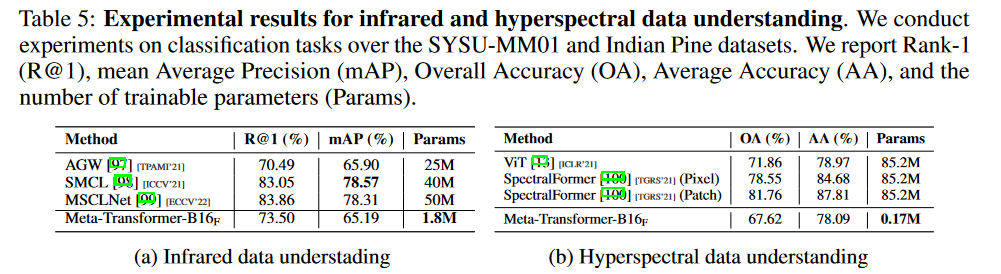
红外和高光谱数据:
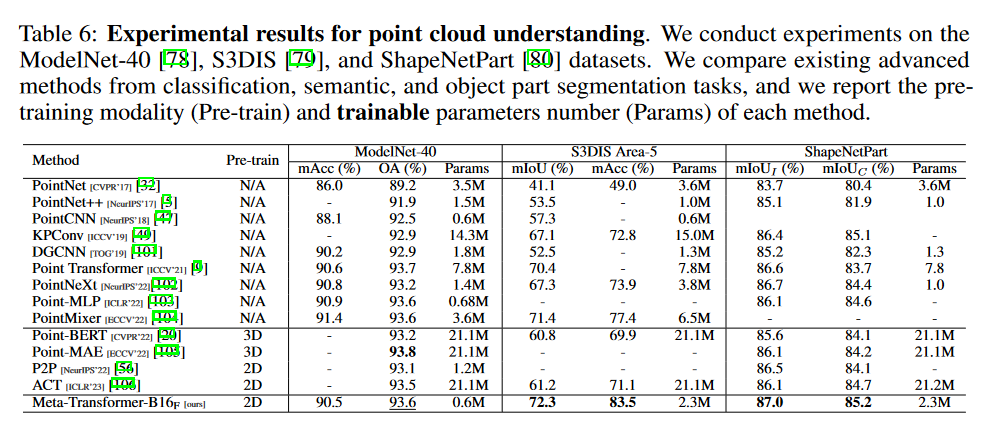
点云:
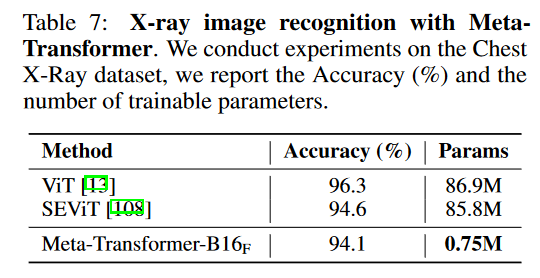
X光图片:
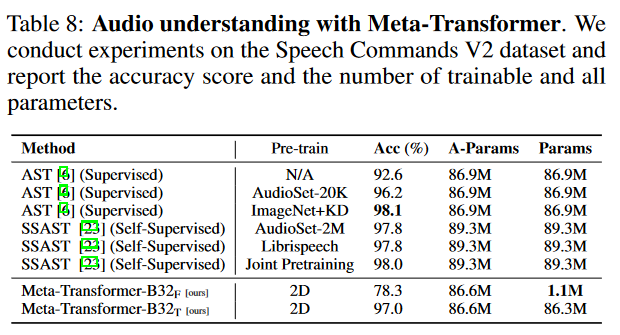
音频:
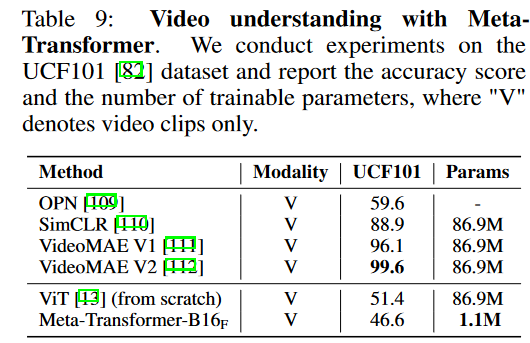
视频:
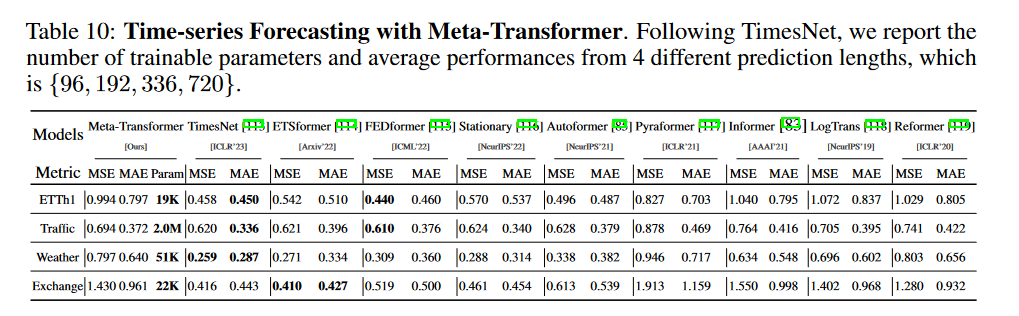
时序:
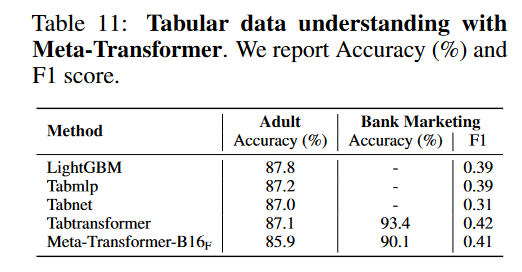
表格数据:
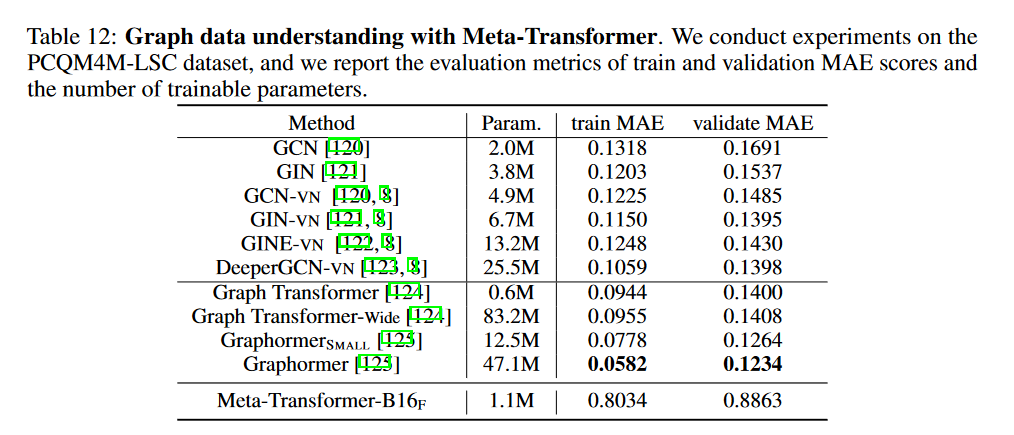
图数据:
此外,作者在附录中给出了更为详细的讨论,具体内容可以去看原文。

















 5290
5290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









