







 探讨Spark在处理空间数据时的关键技术,包括数据分区和数据索引。数据分区关注空间邻近性、数据覆盖完整性等问题,而数据索引则分为全局和局部,旨在提高空间查询和连接操作的效率。
探讨Spark在处理空间数据时的关键技术,包括数据分区和数据索引。数据分区关注空间邻近性、数据覆盖完整性等问题,而数据索引则分为全局和局部,旨在提高空间查询和连接操作的效率。
概述
Spark对空间数据的管理的两个重要方面:数据分区和数据索引
数据分区
数据分区有几个重要的关注点:空间邻近性、数据覆盖完整性、数据均匀分布、数据冗余
空间数据的分区方案一般使用空间索引,控制每一个索引数据项中的数据量,把每一个索引项中的数据作为一个分区,这样可以保证分区中的具有数据良好的空间邻近性。分区空间邻近性有利于使用部分分区即可完成进行空间查询、连接等操作。
为了得到具体的分区结果,需要了解数据的分布。一般使用抽样点利用空间索引进行分区,得到各个分区的范围。根据已有研究[1],1%的数据样本已经足够获取较高质量的分区结果。由于采用了数据样本获取具体的分区范围,所以得到的分区范围很有可能可能不能覆盖完整的数据范围,比如R树。而对于需要对完整数据空间划分的空间索引方法(规则网格、四叉树、KD树等),因为其索引构建时,必须要传入完整数据的空间范围,所以获取到的分区范围一定能覆盖全部数据。
分布式计算具有“木桶效应”,整个计算过程效率取决于计算最慢的节点。所以如果某一个分区的数据过多,则会导致该分区计算时间长,从而降低整个的计算效率。
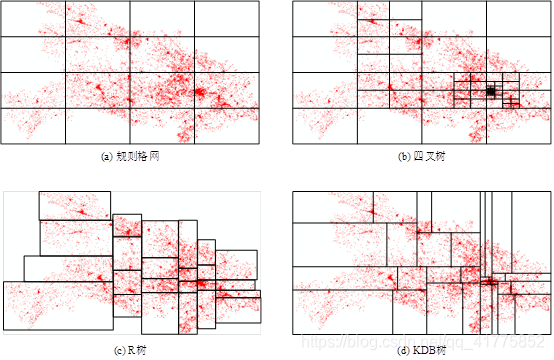
空间索引方案:规则网格、四叉树、R树、KDB树、空间填充曲线。Geospark[5]实现了以上所有方法的数据分区实现。
-
规则网格:数据并不能均匀分布,一些分区数据密度太高,一些数据分区密度太低。
-
四叉树: 数据并不能均匀分布。可以解决分区密度高的问题,但是还是会有分区数据密度太低。
-
R树,一般使用STR树[2],可以保证数据的均匀分布。但是具有覆盖性问题,获取的分区范围是包含样本点的MBR,所以完整数据中可能有数据不属于已有分区,必须另设一个额外的分区保存这些数据,这就破坏了分区数据的空间邻近性。Simba[3]使用的就是STR树进行数据分区,其论文中提到获取到有样本点计算生成的分区结果后,会对分区范围进行扩展,但是具体的扩展方法并没有叙述。
-
KDB树,数据均匀分布,且不会有分区覆盖完整性问题。时空K函数的分布式优化[4],使用的是此方法进行分区。
-
空间填充曲线,其也是需要将空间划分为规则的网格,所以其具有和规则网格一样的问题。
当处理的空间数据是非点数据时,空间对象会和多个分区范围相交。Geospark的处理方法为将空间对象复制,分发到不同分区中。这就造成了数据冗余,当进行空间查询等操作时,会在不同分区中对相同数据进行同样的操作,最后还需要对返回结果进行去重,造成空间和时间的浪费。
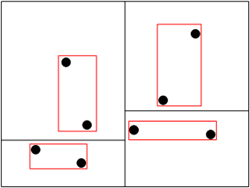
个人想法:分区结果得到各分区的空间范围并不是分区数据真实的MBR。当空间对象是点类型,真实的分区MBR可能比分区范围小。当空间对象是多维对象时,空间对象可能会部分超过分区范围。
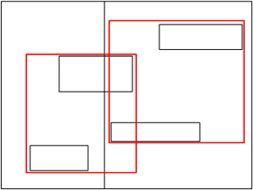
即使使用R树进行数据分区,也由于使用的是样本数据,并不能保证分区范围一定就是分区所有数据的MBR。所以直接使用分区结果范围建立全局索引是不合理的,必须在每个分区中进行数据统计,发送到driver中,建立全局分区索引。
从上述可以看出分区的目的仅仅是将所有数据分发到不同分区中,并保持良好的空间邻近性,不能用于直接建立全局索引。所以可以参考STR树的处理方法,在构建分区的空间索引时,将空间对象转换为空间点进行操作,可以快速的构建索引结构。在数据分区时,也将空间对象作为转换为空间点,由于点只能属于一个空间范围,所以不会造成空间数据冗余。
数据索引
数据索引分为全局索引和局部索引。
局部索引是对RDD分区内的数据建立空间索引。一个分区中的数据不一定都符合我们的处理需求,如果在RDD 原生API中会使用filter算子继续过滤,但filter会遍历所有的数据,逐个判断,效率较低。而利用空间索引,可以直接查询到可能符合要求的数据,直接省略掉不可能的数据,提高了数据的处理效率。
但是由于RDD 分区是一个只能顺序扫描记录的集合,并不持支持随机读写。所以可以将一整个分区的所有记录转换为一条记录(利用mapPartition算子),对这一条记录进行处理。在Geospark,将分区数据转换为SpatialIndex对象(JTS库中的对象,包含数据信息和索引信息);Simba中将分区数据转换为IPartition对象,同样也包含数据信息和索引信息。所以局部索引的实现大同小异,都是讲分区数据转换为一个对象,对象中储存分区所有数据,并建立空间索引。再对分区进行操作时,根据空间索引获取对象中的分区数据。

由于分区具有空间邻近性,所以对于范围查询、KNN查询等操作,涉及到的数据只属于部分分区,所以不需要所有的分区都参与运算,只要求涉及的分区运算,可提高计算效率。所以需要对分区建立全局索引,以查找涉及计算的分区。
局部索引构建完毕之后,可获取整个分区的数据信息(数据范围等),可将其传到driver进程中,driver通过这些分区范围信息,建立分区的全局空间索引。计算时,通过全局索引进行分区剪枝,减少分区处理的数量。
参考文献:
[1] Eldawy A, Alarabi L, Mokbel M F. Spatial partitioning techniques in SpatialHadoop[J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1602-1605.
[2] Leutenegger S T, Lopez M A, Edgington J. STR: A simple and efficient algorithm for R-tree packing[C]. Proceedings 13th International Conference on Data Engineering, 1997: 497-506.
[3] Xie D, Li F, Yao B, et al. Simba: Efficient in-memory spatial analytics[C]. Proceedings of the 2016 International Conference on Management of Data, 2016: 1071-1085.
[4] 面向海量点模式分析的时空Ripley’s K函数优化与加速
[5] Yu J, Wu J, Sarwat M. GeoSpark: A Cluster Computing Framework for Processing Spatial Data[J].


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









