







1.决策树的算法原理
- 从逻辑角度,条件判断语句的组合;
- 从几何角度,根据某种准则划分特征空间;
是一种分治的思想,其最终目的是将样本约分约纯,而划分的核心是在条件的选择或者说是**特征空间的划分标准 **
2.信息熵
1)自信息:
I
(
X
)
=
−
l
o
g
b
p
(
x
)
I(X)=-log_bp(x)
I(X)=−logbp(x)
当b=2时单位为bit,当b=e时单位为nat
2)信息熵(自信息的期望): 度量随机变量X的不确定性,信息熵越大越不确定
H
(
X
)
=
E
[
I
(
X
)
]
=
−
∑
x
p
(
x
)
l
o
g
b
p
(
x
)
H(X)=E[I(X)]=-\sum_xp(x)log_bp(x)
H(X)=E[I(X)]=−x∑p(x)logbp(x)
信息熵计算时约定:若p(x)=0,则
p
(
x
)
l
o
g
b
p
(
x
)
=
0
p(x)log_bp(x)=0
p(x)logbp(x)=0.当X的某个取值的概率为1时信息熵最小,值为0,当X的各个取值的概率均等时信息熵最大,最不缺定,其值为
l
o
g
b
∣
X
∣
log_b|X|
logb∣X∣,其中
∣
X
∣
|X|
∣X∣表示X可能的取值个数。这里可以想象一个例子,一个正常的筛子,它的信息熵最大,而特制的六面都是六的筛子,因为值确定了,所以信息熵最小。
这里的信息熵的最大值的简单的做个推导,在随机变量X的各个取值的概率均等的情况下:
−
∑
x
p
(
x
)
l
o
g
b
p
(
x
)
−
−
−
−
−
−
−
−
−
−
−
=
−
p
(
x
)
l
o
g
b
p
∣
X
∣
(
x
)
−
−
−
−
−
−
−
−
−
−
−
=
−
1
∣
X
∣
l
o
g
b
∣
X
∣
−
∣
X
∣
−
−
−
−
−
−
−
−
−
−
−
=
l
o
g
b
∣
X
∣
-\sum_xp(x)log_bp(x)\newline -----------\newline =-p(x)log_bp^{|X|}(x)\newline -----------\newline =-\frac{1}{|X|}log_b|X|^{-|X|}\newline -----------\newline =log_b|X|
−x∑p(x)logbp(x)−−−−−−−−−−−=−p(x)logbp∣X∣(x)−−−−−−−−−−−=−∣X∣1logb∣X∣−∣X∣−−−−−−−−−−−=logb∣X∣
将样本类别标记y视作随机变量,各个类别在样本集合D中的占比
p
k
(
k
=
1
,
2
,
.
.
.
,
∣
y
∣
)
p_k(k=1,2,...,|y|)
pk(k=1,2,...,∣y∣)视作各个类别取值的概率,则样本集合D(随机变量y)的信息熵(底数取为2)为
E
n
t
(
D
)
=
−
∑
k
=
1
∣
y
∣
p
k
l
o
g
2
p
k
Ent(D)=-\sum^{|y|}_{k=1}p_klog_2p_k
Ent(D)=−k=1∑∣y∣pklog2pk
此时的信息熵所代表的不确定性可以转换理解为集合内样本的纯度。理解一下,我们希望我们划分出来的空间内的样本的y的概率越大越好,这样我们就把各个y的不同值划分的很好了,这就对应了信息熵中的期望信息熵最小的情况,因此可以用信息熵来表示集合内样本的纯度,信息熵越小样本的纯度越高。
3)条件熵:
Y的信息熵关于概率分布X的期望,在已知X后Y的不确定性
H
(
Y
∣
X
)
=
∑
x
p
(
x
)
H
(
Y
∣
X
=
x
)
H(Y|X)=\sum_xp(x)H(Y|X=x)
H(Y∣X)=x∑p(x)H(Y∣X=x)
从单个属性(特征)a的角度来看,假设其可能取值为
a
1
,
a
2
,
.
.
.
,
a
V
{a^1,a^2,...,a^V}
a1,a2,...,aV,
D
v
D^v
Dv表示属性a取值为
a
v
∈
a
1
,
a
2
,
.
.
.
,
a
V
a^v\in{a^1,a^2,...,a^V}
av∈a1,a2,...,aV的样本集合,
∣
D
v
∣
∣
D
∣
\frac{|D^v|}{|D|}
∣D∣∣Dv∣表示占比,那么在已知属性a的取值后,样本集合D的条件熵为
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
\sum^V_{v=1}\frac{|D^v|}{|D|}Ent(D^v)
v=1∑V∣D∣∣Dv∣Ent(Dv)
这里上下两部分的关系,其实下面的部分再更加具体的解释上面的式子。这里第二部分假设X是只有一个维度,也就是特征a,而随机变量X的取值,这里就是a的具体的取值会影响到Y的信息熵,也就是说,
D
v
D
\frac{D^v}{D}
DDv就是
p
(
x
)
p(x)
p(x),而
H
(
Y
∣
X
=
x
)
H(Y|X=x)
H(Y∣X=x)就是
E
n
t
(
D
v
)
Ent(D^v)
Ent(Dv)。这样可能好理解一点?
4)信息增益
在已知属性(特征)a的取值后y的不确定性减少的量,也即纯度的提升:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
v
=
1
D
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
Gain(D,a)=Ent(D)-\sum_{v=1}^D\frac{|D^v|}{|D|}Ent(D^v)
Gain(D,a)=Ent(D)−v=1∑D∣D∣∣Dv∣Ent(Dv)
3.决策树
3.1ID3决策树
以信息增益为准则来选择划分属性的决策树
a
∗
=
arg max
a
∈
A
G
a
i
n
(
D
,
a
)
a_*=\argmax_{a\in A} Gain(D,a)
a∗=a∈AargmaxGain(D,a)
ID3的问题:使用信息增益准则对可能取值数目较多的属性 有所偏好
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
# 加载西瓜数据集
data = {
"编号": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
"色泽": ["青绿", "乌黑", "乌黑", "青绿", "浅白", "青绿", "乌黑", "浅白", "青绿", "浅白", "乌黑", "浅白", "青绿"],
"根蒂": ["蜷缩", "蜷缩", "蜷缩", "蜷缩", "蜷缩", "稍蜷", "稍蜷", "稍蜷", "硬挺", "硬挺", "硬挺", "蜷缩", "蜷缩"],
"敲声": ["浊响", "沉闷", "浊响", "沉闷", "浊响", "浊响", "浊响", "浊响", "清脆", "清脆", "清脆", "浊响", "浊响"],
"纹理": ["清晰", "清晰", "清晰", "清晰", "清晰", "稍糊", "稍糊", "稍糊", "清晰", "清晰", "稍糊", "模糊", "稍糊"],
"脐部": ["凹陷", "凹陷", "凹陷", "凹陷", "凹陷", "稍凹", "稍凹", "稍凹", "平坦", "平坦", "平坦", "稍凹", "稍凹"],
"触感": ["硬滑", "硬滑", "硬滑", "硬滑", "硬滑", "软粘", "硬滑", "硬滑", "软粘", "硬滑", "硬滑", "硬滑", "硬滑"],
"好瓜": ["是", "是", "是", "是", "否", "否", "否", "否", "否", "否", "否", "否", "否"]
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 将'好瓜'列转换为二进制值
df['好瓜'] = df['好瓜'].map({'是': 1, '否': 0})
# 特征和目标变量
features = df.drop(['编号', '好瓜'], axis=1)
target = df['好瓜']
# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)
# 初始化决策树分类器(使用ID3算法)
clf = DecisionTreeClassifier(criterion='entropy', random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = clf.score(X_test, y_test)
print(f'模型的准确率是: {accuracy*100:.2f}%')
# 可视化决策树
plt.figure(figsize=(20,10))
tree.plot_tree(clf, filled=True, feature_names=features_encoded.columns, class_names=['否', '是'])
plt.show()
# 存储决策树模型
import joblib
joblib.dump(clf, 'decision_tree_model.pkl')
# 加载模型并进行预测(示例)
loaded_model = joblib.load('decision_tree_model.pkl')
sample_data = X_test.iloc[0].values.reshape(1, -1)
prediction = loaded_model.predict(sample_data)
print(f'预测结果: {"是" if prediction[0] == 1 else "否"}')
可视化决策树:
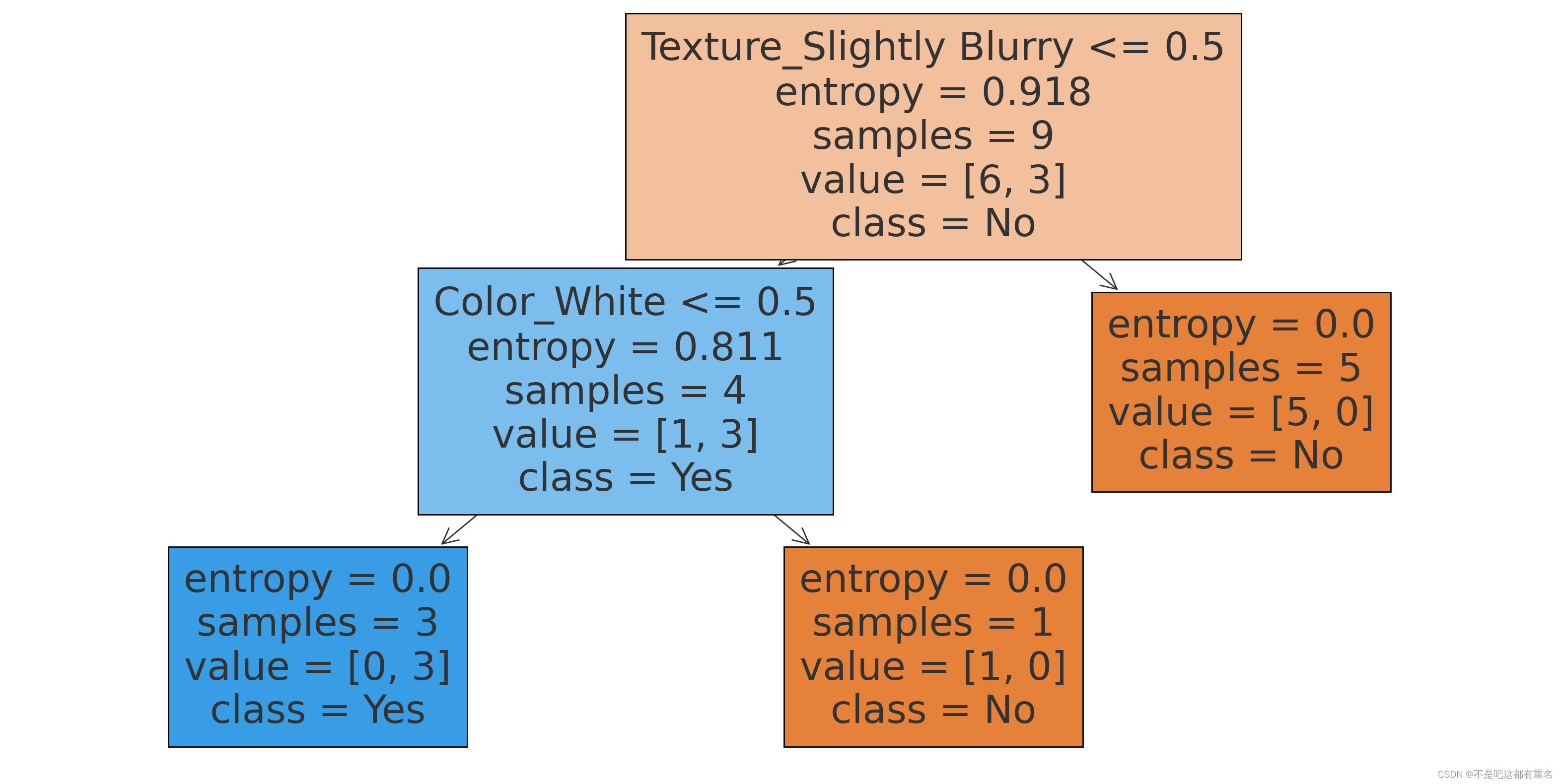
3.2 C4.5决策树
为了解决ID3的问题,C4.5使用增益率代替信息增益,增益率的定义如下:
G
a
i
n
r
a
t
e
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
Gain_rate(D,a)=\frac{Gain(D,a)}{IV(a)}
Gainrate(D,a)=IV(a)Gain(D,a)
其中,
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
l
o
g
2
∣
D
v
∣
∣
D
∣
IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}log_2\frac{|D^v|}{|D|}
IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
称为属性a的固有值,a的可能取值个数V越大,通常其固有值也越大。
C4.5的问题: 增益率对可能取值数目较少的属性有所偏好
因此,C4.5采用启发式方法:先选出信息增益高于平均水平的属性,然后再从中选择增益率最高的。
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
# 创建西瓜数据集
data = {
"Number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
"Color": ["Green", "Black", "Black", "Green", "White", "Green", "Black", "White", "Green", "White", "Black", "White", "Green"],
"Root": ["Curled", "Curled", "Curled", "Curled", "Curled", "Slightly Curled", "Slightly Curled", "Slightly Curled", "Stiff", "Stiff", "Stiff", "Curled", "Curled"],
"Knock": ["Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Clear", "Clear", "Clear", "Dull", "Dull"],
"Texture": ["Clear", "Clear", "Clear", "Clear", "Clear", "Slightly Blurry", "Slightly Blurry", "Slightly Blurry", "Clear", "Clear", "Slightly Blurry", "Blurry", "Slightly Blurry"],
"Navel": ["Indented", "Indented", "Indented", "Indented", "Indented", "Slightly Indented", "Slightly Indented", "Slightly Indented", "Flat", "Flat", "Flat", "Slightly Indented", "Slightly Indented"],
"Touch": ["Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth"],
"Good": ["Yes", "Yes", "Yes", "Yes", "No", "No", "No", "No", "No", "No", "No", "No", "No"]
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 将'Good'列转换为二进制值
df['Good'] = df['Good'].map({'Yes': 1, 'No': 0})
# 特征和目标变量
features = df.drop(['Number', 'Good'], axis=1)
target = df['Good']
# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)
# 初始化决策树分类器(使用C4.5算法,即使用信息增益比)
clf = DecisionTreeClassifier(criterion='entropy', random_state=42, splitter='best')
# 训练模型
clf.fit(X_train, y_train)
# 可视化决策树
plt.figure(figsize=(20,10))
tree_plot = tree.plot_tree(clf, filled=True, feature_names=features_encoded.columns, class_names=['No', 'Yes'])
plt.show()
可视化决策树:
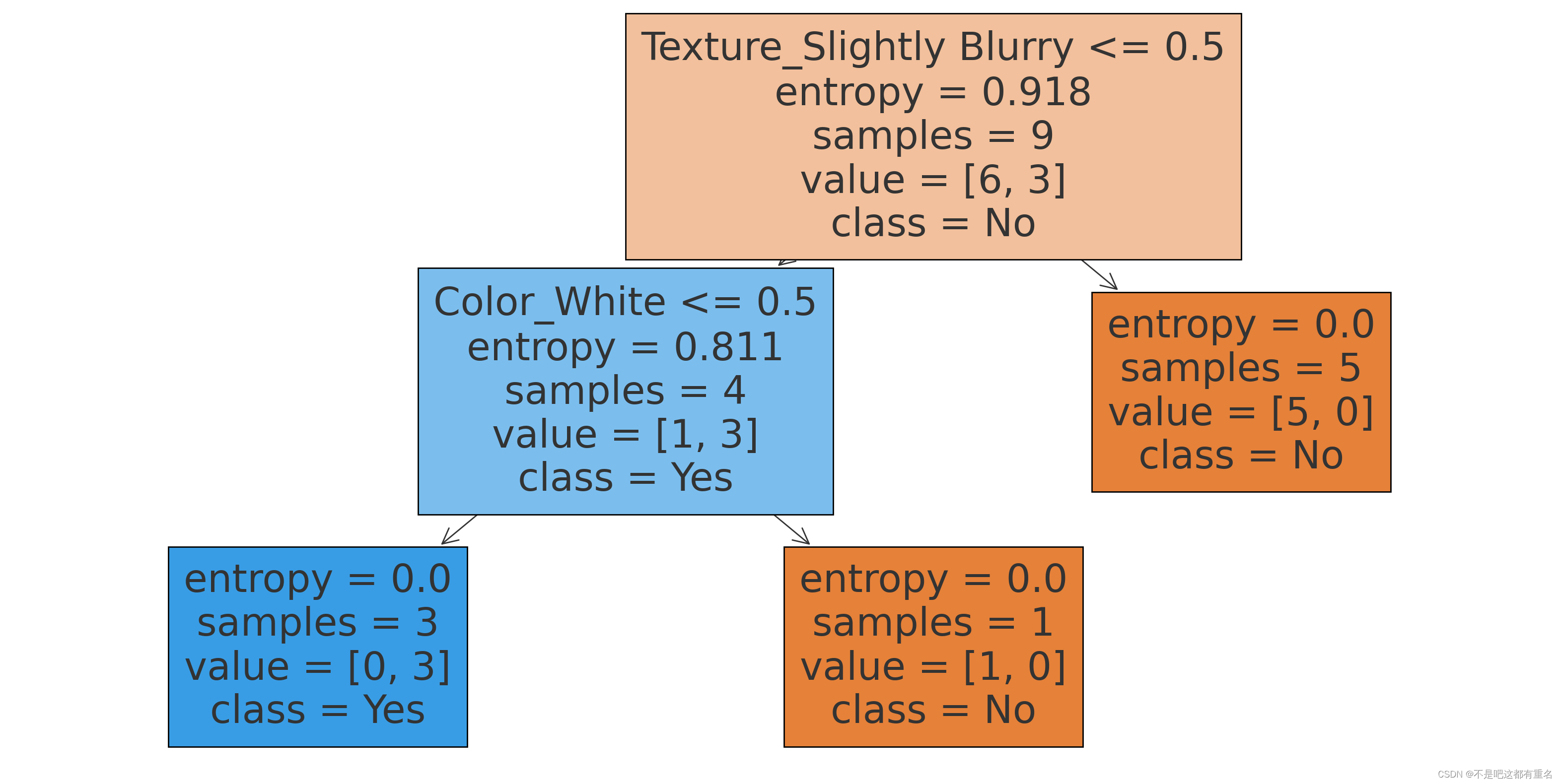
3.3CART决策树
基尼值: 从样本集合D中随机抽取两个样本,其类别标记不一致的概率。因此,基尼值越小,碰到异类的概率就越小,纯度自然越高。(对应信息熵)
G
i
n
i
(
D
)
=
∑
k
=
1
∣
y
∣
∑
k
′
≠
k
p
k
p
k
′
=
∑
k
=
1
∣
y
∣
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
∣
y
∣
p
k
2
Gini(D)=\sum_{k=1}^{|y|}\sum_{k'\neq k}p_kp_{k'}=\sum_{k=1}^{|y|}p_k(1-p_k)=1-\sum^{|y|}_{k=1}p_k^2
Gini(D)=k=1∑∣y∣k′=k∑pkpk′=k=1∑∣y∣pk(1−pk)=1−k=1∑∣y∣pk2
基尼指数: 属性a的基尼指数(对应条件熵):
G
i
n
i
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
Gini_index(D,a)=\sum_{v=1}^V\frac{|D^v|}{|D|}Gini(D^v)
Giniindex(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
CART决策树: 选择基尼指数最小的属性作为最优划分属性,最后构造了一个二叉树。
a
∗
=
arg max
a
∈
A
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
a_*=\argmax_{a\in A} Gini\_index(D,a)
a∗=a∈AargmaxGini_index(D,a)
CART决策树的实际构造算法如下:
- 对每个属性a的每个可能取值v,将数据集D分为a=v和a≠v两部分计算基尼指数,即
G i n i i n d e x ( D , a ) = ∣ D a = v ∣ ∣ D ∣ G i n i ( D a = v ) + ∣ D a ≠ v ∣ ∣ D ∣ G i n i ( D a ≠ v ) Gini_index(D,a)=\frac{|D^{a=v}|}{|D|}Gini(D^{a=v})+\frac{|D^{a\neq v}|}{|D|}Gini(D^{a\neq v}) Giniindex(D,a)=∣D∣∣Da=v∣Gini(Da=v)+∣D∣∣Da=v∣Gini(Da=v) - 选择基尼指数最小的属性及其对应取值作为最优划分属性和最优划分点;
- 重复上述步骤,直至满足停止条件
代码:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
# 创建西瓜数据集
data = {
"Number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13],
"Color": ["Green", "Black", "Black", "Green", "White", "Green", "Black", "White", "Green", "White", "Black", "White", "Green"],
"Root": ["Curled", "Curled", "Curled", "Curled", "Curled", "Slightly Curled", "Slightly Curled", "Slightly Curled", "Stiff", "Stiff", "Stiff", "Curled", "Curled"],
"Knock": ["Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Dull", "Clear", "Clear", "Clear", "Dull", "Dull"],
"Texture": ["Clear", "Clear", "Clear", "Clear", "Clear", "Slightly Blurry", "Slightly Blurry", "Slightly Blurry", "Clear", "Clear", "Slightly Blurry", "Blurry", "Slightly Blurry"],
"Navel": ["Indented", "Indented", "Indented", "Indented", "Indented", "Slightly Indented", "Slightly Indented", "Slightly Indented", "Flat", "Flat", "Flat", "Slightly Indented", "Slightly Indented"],
"Touch": ["Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Soft and Sticky", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth", "Hard and Smooth"],
"Good": ["Yes", "Yes", "Yes", "Yes", "No", "No", "No", "No", "No", "No", "No", "No", "No"]
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 将'Good'列转换为二进制值
df['Good'] = df['Good'].map({'Yes': 1, 'No': 0})
# 特征和目标变量
features = df.drop(['Number', 'Good'], axis=1)
target = df['Good']
# 使用get_dummies进行one-hot编码
features_encoded = pd.get_dummies(features)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_encoded, target, test_size=0.3, random_state=42)
# 初始化决策树分类器(使用CART算法,即使用Gini系数)
clf_cart = DecisionTreeClassifier(criterion='gini', random_state=42)
# 训练模型
clf_cart.fit(X_train, y_train)
# 预测测试集
y_pred_cart = clf_cart.predict(X_test)
# 计算准确率
accuracy_cart = clf_cart.score(X_test, y_test)
print(f'模型的准确率是: {accuracy_cart*100:.2f}%')
# 可视化决策树
plt.figure(figsize=(20,10))
tree_plot_cart = tree.plot_tree(clf_cart, filled=True, feature_names=features_encoded.columns, class_names=['No', 'Yes'])
plt.show()
可视化决策树:

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











