









1.场景描述
近日,在进行数据整理时,需要根据某些列来找出具体重复的数据有哪些,废话不多说,先把图放上先。
import pandas as pd
test_df=pd.DataFrame({'name':['张三','李四','王五','张三','李四','王五','张三'],
'level':[10,3,8,14,2,3,18],
'info':['吵闹','安静','中等','吵闹','安静','安静','吵闹'],
'change_times':[1,2,3,1,2,4,9]
})
test_df
数据截图:
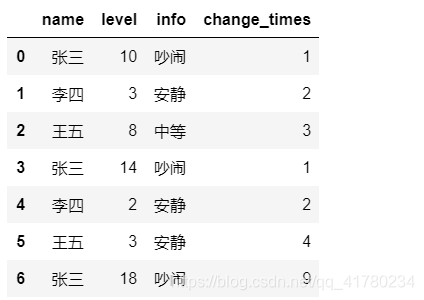
需要根据name和info两个字段,找出重复的数据,结果如下:
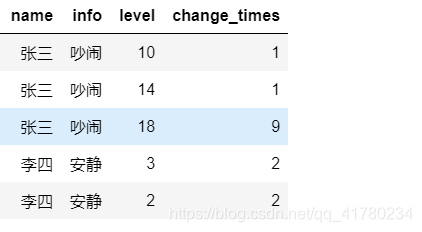
2.实现方法
2.1 方法1
利用groupby查看重复情况,然后进行merge操作.该方法可以查看具体重复的个数,还可以灵活更改重复次数来筛选数据。
df1=test_df.groupby(["name","info"]).size()
col=df1[df1>1].reset_index()[["name","info"]]
pd.merge(col,test_df,on=["name","info"])
输出结果如下:
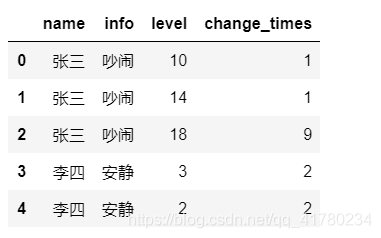
2.2 方法2
先取出重复的字段,然后生成唯一的name列和info列,再进行merge。
df1=test_df[test_df.duplicated(subset=cols)].drop_duplicates(cols)[cols]
pd.merge(df1,test_df,on=cols,how="left")
实现截图:
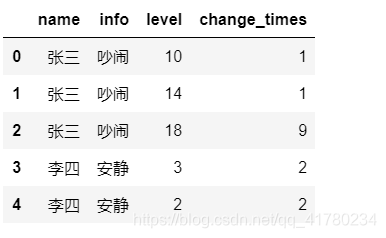
2.3 方法3
获取重复索引,然后取交集,然后筛选出来。该方法保留了原来的索引,缺点是数据原索引不能有重复。
index1=test_df[test_df[["name","info"]].duplicated(keep="last")].index
index2=test_df[test_df[["name","info"]].duplicated(keep="first")].index
test_df.loc[index1 | index2,:]
截图如下:
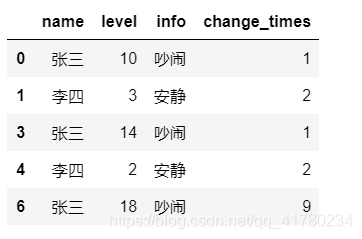
2.4 方法4
先获取所有索引,然后去除不重复的索引,即差集,然后筛选出来。该方法也可以保留原来的索引,缺点也是数据原索引不能有重复。
test_df.loc[set(test_df.index) -set(test_df.drop_duplicates(subset=["name","info"],keep=False).index),:]
结果如下:
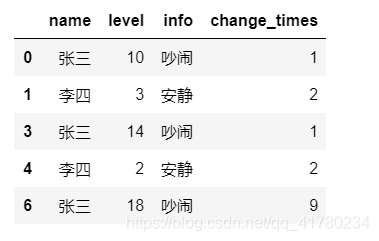
2.5 方法5
网友提供的方法,该方法可以保存原始索引,在数据原索引重复的情况下也可以使用。
#写法1
test_df[test_df[["name","info"]].duplicated(keep=False)]
#写法2
test_df[test_df.duplicated(subset=["name","info"],keep=False)]
完整代码如下:
import pandas as pd
test_df=pd.DataFrame({'name':['张三','李四','王五','张三','李四','王五','张三'],
'level':[10,3,8,14,2,3,18],
'info':['吵闹','安静','中等','吵闹','安静','安静','吵闹'],
'change_times':[1,2,3,1,2,4,9]
})
test_df
#方法1
cols=["name","info"]
df1=test_df.groupby(cols).size()
col=df1[df1>1].reset_index()[cols]
pd.merge(col,test_df,on=cols)
#方法2
df1=test_df[test_df.duplicated(subset=cols)].drop_duplicates(cols)[cols]
pd.merge(df1,test_df,on=cols,how="left")
#方法3
index1=test_df[test_df[cols].duplicated(keep="last")].index
index2=test_df[test_df[cols].duplicated(keep="first")].index
test_df.loc[index1 | index2,:]
#方法4
test_df.loc[set(test_df.index) -set(test_df.drop_duplicates(subset=cols,keep=False).index),:]
#方法5
#写法1
test_df[test_df[["name","info"]].duplicated(keep=False)]
#写法2
test_df[test_df.duplicated(subset=["name","info"],keep=False)]
3.后记
上述方法各有优劣,具体使用哪个方法,看业务场景和个人喜好啦。如果你们还有更好的方法,欢迎私聊我或者给我留言~
pandas的使用,可以看我另外一篇:Pandas参考手册、常用函数及方法汇总


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











