






最强OLAP分析引擎-Clickhouse 快速上手三
四、集群机制
这一章来分享clickhouse的集群机制。其实clickhouse的单机性能通常已经非常优秀了,底层的数据压缩效率是很高的。例如之前看到过,官方提供的Github Evnets数据集三十多亿数据,用200G硬盘也就存下来了,这种配置要求,在服务器级别是压力不大的。另外,单机查询性能如果CPU配置足够好的话,查询速度也基本可以达到秒级。
clickhouse提供了集群机制的支持。clickhouse的集群主要有两个作用,一是数据副本,也就是将数据冗余到另外的机器上,用以保证高可用。二是分布式表,也就是将一个表的数据分散到多个节点上保存。
在这其中,数据副本是相对比较重要的,而至于分布式表,大部分场景下其实是不需要的。这是因为clickhouse的单机性能通常已经非常优秀了,底层的数据压缩效率是很高的。例如之前看到过,官方提供的Github Evnets数据集三十多亿数据,用200G硬盘也就存下来了,这种配置要求,在服务器级别是压力不大的。另外,单机查询性能如果CPU配置足够好的话,查询速度也基本可以达到秒级。分布式表反而会消耗网络资源,降低查询速度。
1、数据副本
副本的目的是保障数据的高可用。当一台clickhouse节点宕机了,也可以从其他备份服务器获得相同的数据。clickhosue只有MergeTree系列的表引擎可以支持副本。针对MergeTree系列的表引擎,clickhouse都提供了对应的Replicated*MergeTree表引擎来支持数据副本。
具体参看官方文档:https://clickhouse.com/docs/zh/engines/tableengines/mergetree-family/replication/
clickhouse的数据副本机制是表级别的,也就是说只针对表进行复制,一个数据库中可以同时包含复制表和非复制表。副本机制对于select查询是没有影响的,查询复制表和非复制表的速度是一样的。而写入数据时,clickhouse的集群没有主从之分,大家都是平等的。只不过配置了复制表后,insert以及alter操作会同步到对应的副本机器中。对于复制表,每个Insert语句会往Zookeeper中写入十来条记录,相比非复制表,写ZK会导致Insert语句的延迟时间略长。但是,在clickhouse建议的每秒不超过一个Insert语句的执行频率下,这个延迟时间不会有太大的影响。
集群数据写入流程如下:
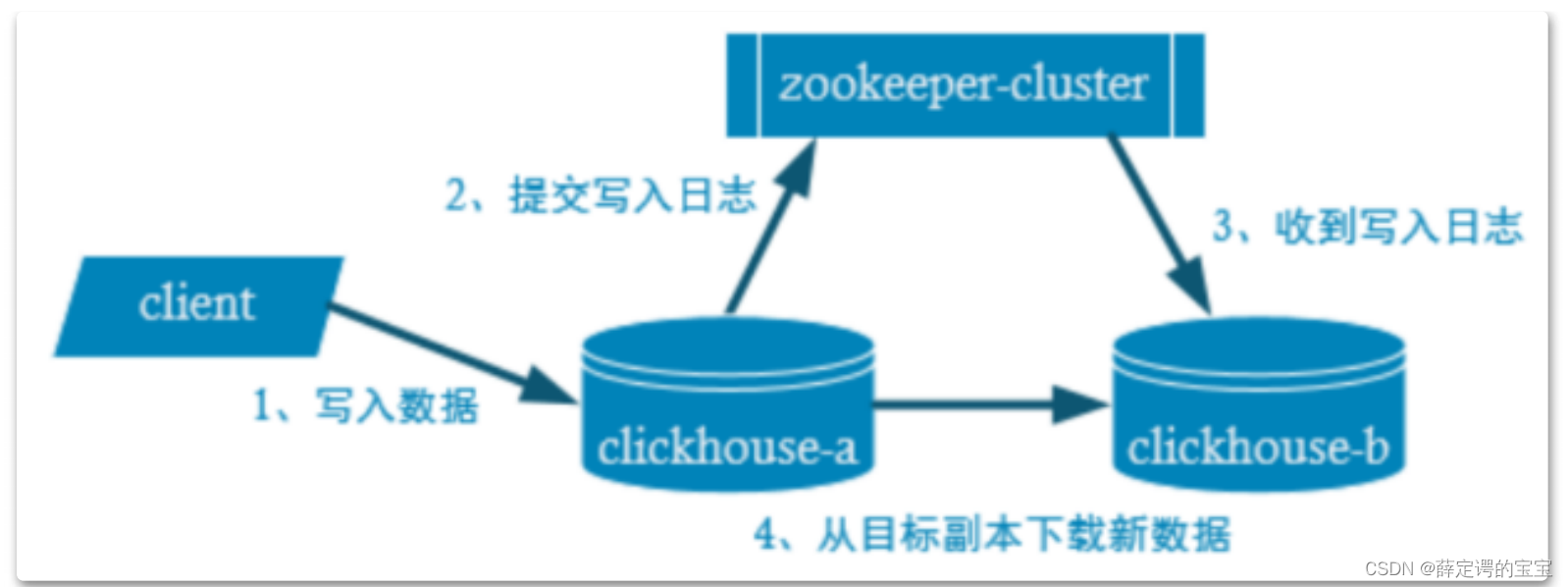
在这其中,其实还有很多的实现细节。数据副本需要经过网络传输,所以副本中写入数据是有延迟的。默认情况下,clickhouse对于Insert语句,只会等待一个副本写入成功后就会返回。如果有多个副本的情况下,clickhouse是有可能丢失数据的。写入数据时,clickhouse只保证单个数据块的写入是原子的,而不能保证所有的数据写入是原子的。一个数据块的大小可以根据max_insert_block_size=1048576行进行分块。数据块写入时是会去重的,一个同样的Insert语句多次重复执行,数据库块只会执行一次。这是为了防止用户重复插入数据或者网络波动等原因造成的数据重发。这个去重机制只对应Replicated*MergeTree系列的表引擎,普通的MergeTree是不带这个去重功能
的。
clickhouse数据副本使用实例:
1、启动一个Zookeeper集群。
clickhouse的集群搭建依赖zookeeper。如果没有配置zookeeper的话,依然可以创建复制表,但是这些复制表都将变成只读。另外,官方建议,不要在clickhouse所在的服务器上运行zookeeper。因为zookeeper对数据延迟非常敏感,而clickhouse可能会占用所有可用的系统资源。
注意当前版本的clickhouse要求zookeeper版本不低于3.4.5。并且,官方对zookeeper的优化配置也提出了指导意见。具体参见官方文档:https://clickhouse.com/docs/zh/operations/tips/
2、在clickhouse中进行配置。
打开clickhouse的配置文件 /etc/clickhouse-server/config.xml,在配置文件中指定你的zookeeper集群地址,然后重启服务器。在730行左右找到标签进行配置:
<zookeeper>
<node>
<host>hadoop01</host>
<port>2181</port>
</node>
<node>
<host>hadoop02</host>
<port>2181</port>
</node>
<node>
<host>hadoop03</host>
<port>2181</port>
</node>
</zookeeper>
3、创建复制表
建表的方式与之前使用MergeTree系列表引擎基本都是一样的,只不过在Engine上要加上Replicated。
CREATE TABLE t_stock_replicated
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/t_stock','hadoop01')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);
在ReplicatedMergeTree中传入两个参数,一个参数是zk的路径。一个参数是备份的名字。
在多个节点中,同一个集群的复制表,他们的zk路径应该是一样的,但是备份名应该是不相同的。
在这两个参数中,支持使用占位符例如 /clickhouse/tables/{layer}-{shard}/t_stock 和 ${replicate}。这些占位符的取值都在config.xml中
配置的 宏配置这一片段当中。打开注释即可。
<macros>
<layer>05</layer>
<shard>02</shard>
<replica>example05-02-1.yandex.ru</replica>
</macros>
例如之前的clickhouse数据库是安装在hadoop01机器上。完成上述的操作之后。在hadoop02机器上,同样安装一个clickhouse服务,config.xml文件同步配置。hadoop02机器上只需要创建一个表。
CREATE TABLE t_stock_replicated
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/t_stock','hadoop02')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);
那么两个机器上的t_stock_replicated表的数据就会同步。而且这个数据同步是双向的,也就是说写入到hadoop02机器上的数据,同样会同步到hadoop01机器上。
同样的方式,你可以将clickhouse中的数据复制到更多的集群中。在这个过程中,你基本不需要担心zookeeper的性能问题。一个Zookeeper集群能给整个clickhouse集群支撑协调每秒几百个INSERT,数据的吞吐量可以跟不用复制的数据一样高。官方给出的Yandex.Metrica集群,大约有300台服务器,依然一个zookeeper搞定了。
clickhouse这种集群机制相比很多数据库产品简直不要太简单了。
2、分布式表
副本机制能够提高数据的可用性,降低丢失数据的风险,但是每台服务器上都需要容纳全量的数据,没有解决数据的横向扩容的问题。在clickhouse中,可以通过水平切分的方式,将完整的数据集切分成不同的分片。这些分片只保存一部分数据,分布在不同的节点上。然后再通过Distributed表引擎将数据拼接起来作为一个完整的表使用。Distributed表引擎本身不存储数据,就有点像ShardingSphere与MySQL,只是一个中间件,通过分布式逻辑表来写入、分发、路由操作多台节点不同分片的分布式数据。
之前分析过,clickhouse的单机性能是很强的。很多企业在实际运用过程中,会配置副本机制来做高可用,但是通常不会做分片,这样可以降低查询时的性能消耗。
具体参看官方文档: https://clickhouse.com/docs/zh/engines/tableengines/special/distributed/
使用分片表需要先配置集群。一个集群由多个分片shard,每个分片下可以配置一个或多个副本replica。这些replica副本可以配置成数据副本,当然这也不是必须的。分片表是可以和数据副本混合使用的。在声明分片表时需要指定一个集群。
数据分片之后,写入的流程是这样的
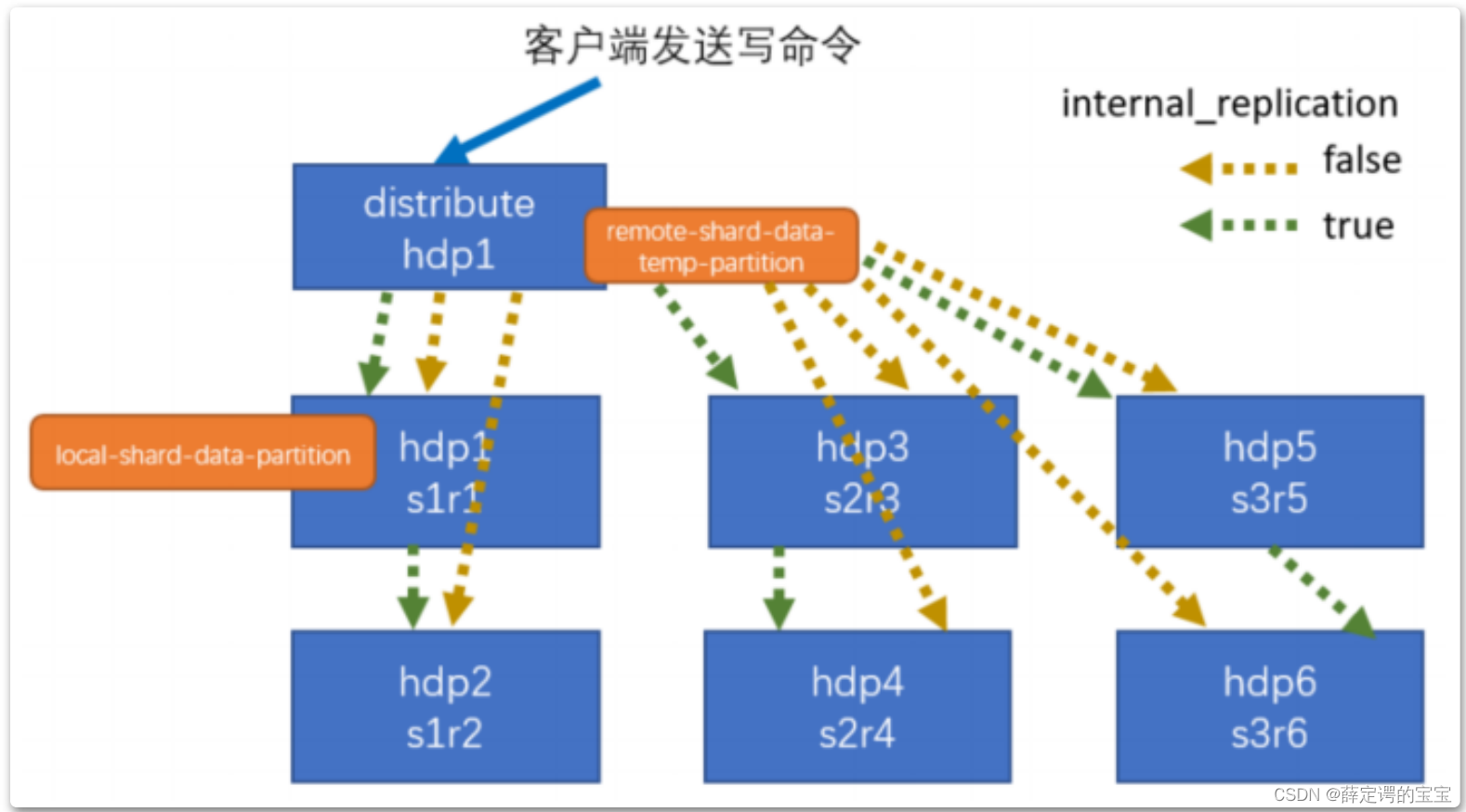
配置分片时可以指定一个 internal_replication 参数。为true时,写操作只选一个正常的副本写入数据。如果分片内的子表都是复制表(Replicated*MergeTree引擎),那就请使用这个配置。如果参数设置为false,写操作就会将数据写入所有副本。实际上,这种方式还不如使用复制表更好。因为这种机制不会检查副本的一致性,并且随着时间推移,副本数据可能会有些不一致。
在配置集群时,会给每个分片shard分配一个权重weight,默认是1。数据会一句分片的权重按比例分发到对应的分片上。这样,你可以选择在配置比较好的机器上分配更多的权重。
另外要注意,分布式表的数据也是异步写入的。对于分布式表的INSERT,数据块只写本地文件系统。之后会尽快地在后台发送给远程服务器。如果在INSERT的时候机器节点丢失了,则会造成插入的数据丢失,并且不会再进行后续的检查。而之前介绍的数据副本机制,会在机器服务恢复过来后,继续同步之前丢失的数据。
数据读取的流程是这样的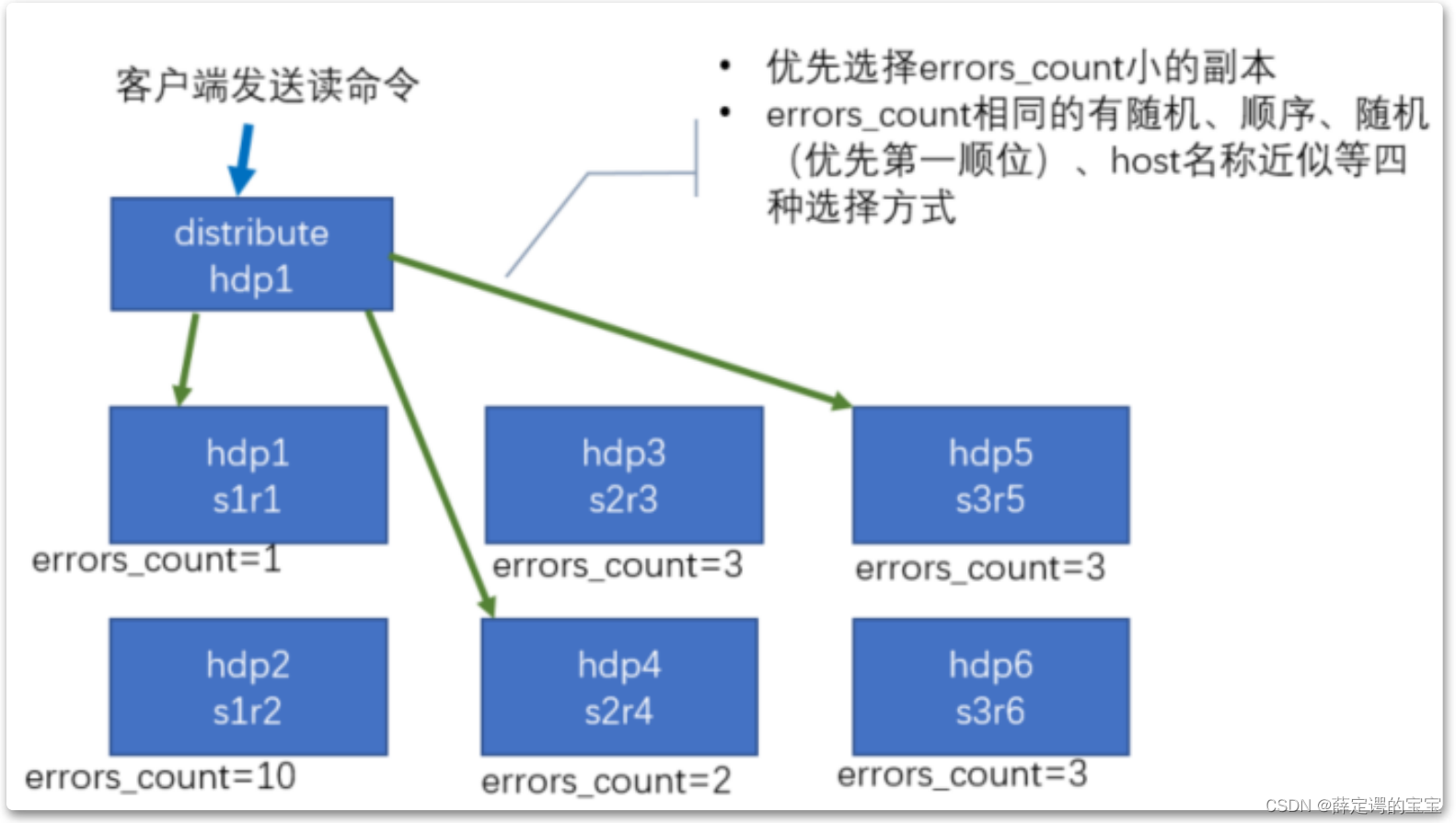
通过分布式引擎,可以像使用本地服务器一样使用集群。但是,集群不是自动扩展的,需要修改配置文件,再重启服务。使用分布式引擎时,如果集群信息发生了变动,分布式表中的集群信息也会即时更新,无需重启服务器。但是,通常分布式表的集群结构是不建议经常变动的,如果集群结构不稳定的话,这时就不建议使用分布式表了,可以使用远程表函数remote来访问。
SELECT查询会被发送到所有分片,并且无论数据在分片中如何分布(即使数据完全随机分布)都可以正常工作。添加新分片时,也不必将旧数据传输到该分片。你可以给新分片分配较大的权重然后写新数据,数据可能会一段时间分布不均,但是查询会正常高效的运行。
对于同一个分片下的多个副本,分布式表肯定只能读取其中的一个副本。那如何选择要读取数据的副本呢?在服务端会维护一个errors_count,也就是读取当前副本出现错误的次数。默认情况下,clickhouse会优先选择errors_count出错次数比较小的副本来读取。
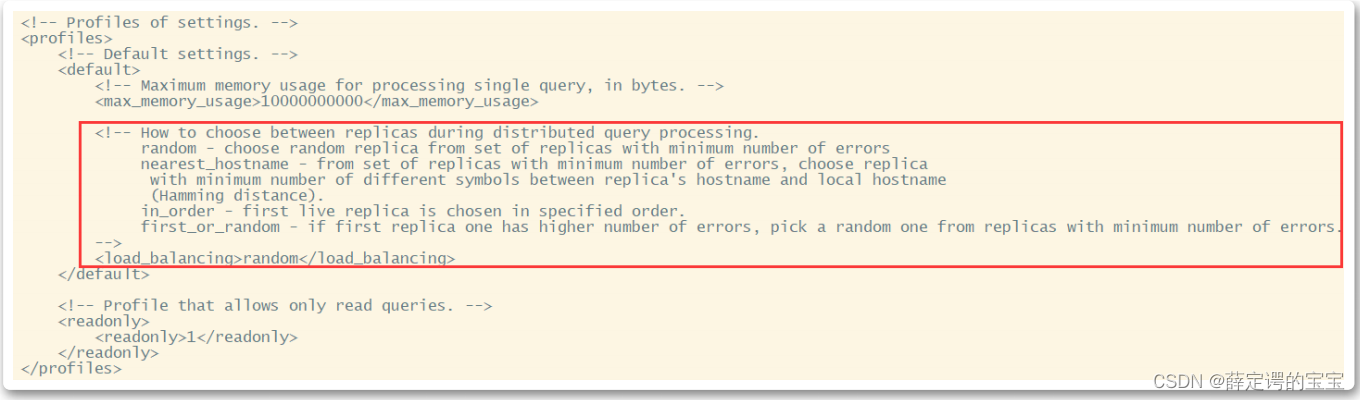
关于副本选择机制,参见clickhouse的配置文件users.xml
clickhouse分布式表使用实例
1、同样需要zookeeper支持。
2、在clickhouse中配置集群。
同样是打开clickhouse的配置文件 /etc/clickhouse-server/config.xml,在配置文件中配置一个分布式集群,然后重启服务器。在590行左右找到标签进行配置:
<remote_servers>
<logs>
<shard>
<!-- Optional. Shard weight when writing data. Default: 1. -->
<weight>1</weight>
<!-- Optional. Whether to write data to just one of the
replicas. Default: false (write data to all replicas). -->
<internal_replication>false</internal_replication>
<replica>
<host>hadoop01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>2</weight>
<internal_replication>false</internal_replication>
<replica>
<host>hadoop02</host>
<port>9000</port>
</replica>
</shard>
</logs>
</remote_servers>
配置文件中默认已经配置了几个分布式集群,生产上建议删掉这段配置。实验中最好注释掉。
在这一段配置中,配置了一个名为logs的集群,他由两个分片shard组成,每个分片只包含一个副本replica。在标签中配置包含副本的所有机器节点(实际使用时当然还是建议配置多个副本)。两个分片所包含的副本节点不要求相同,实际使用时也只有不相同才有意义。在标签中,除了已经配置过的这些外,还可以配置一些子标签。
- port: 消息传递的TCP端口。由config.xml中的<tcp_port>属性配置,默认是9000。另外还一个http_port配置的是8123,这两个不要搞混了
- user 这个标签是用于连接远程clickhouse服务器的用户名。默认是default。在users.xml中可以进行更多的用户权限配置。如果配置了其他用户,这个标签就必须添加。
- password 这个标签是用于连接远程clickhouse服务器的密码。默认是空字符串。我们的实验环境中,当初安装clickhouse服务时并没有设定密码,所以不用添加。
- secure 配置是否使用ssl进行连接。默认true
- compression: 是否使用数据压缩,默认true。
配置集群时,集群名字不能带点号。配置文件需要在集群服务上进行同步。
配置的集群可以在System.cluster表中查看到。也可以通过show clusters中看到。
在我们的实验中为了专注于分布式表引擎,在每个shard下只配置了一个副本replica。实际上,clickhouse的每个分片下都支持配置多个副本replica。具体参见配置文件中的示例。
3、使用分片表
在建表时,通过 on cluster 关键字指定集群名
CREATE TABLE t_stock_local on cluster logs
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
-- ENGINE =
ReplicatedMergeTree('/clickhouse/tables/{shard}/t_stock','{replica}')
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);
在hadoop01机器上执行这个建表语句,这个表就会同步到hadoop02机器上。
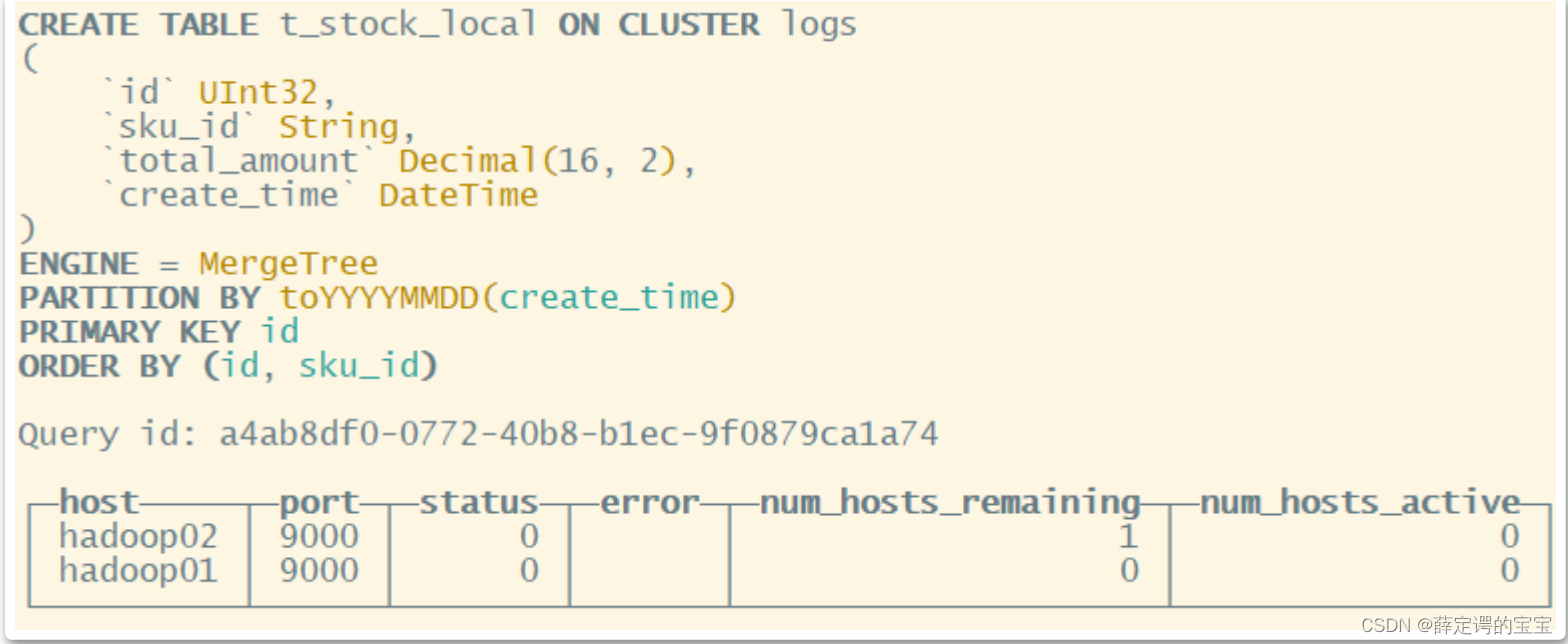
这里要注意下,我们示例中每个分片只有1个分片,并没有配置副本。通常还是建议在一个分片下建立多个副本,在多个副本上建立复制表。但是这时,之前配置副本时说到不同节点上的replica副本名称不可以相同。这时,如果replica副本名称还是在SQL语句中指定的话,就会造成两边的副本名重复了。这时的做法就是将副本名改为使用配置文件中配置的macros宏,在两台机器上将副本名称区分开。
4、使用Distributed表引擎创建分布式表
CREATE TABLE t_stock_distributed on cluster logs
(
`id` UInt32,
`sku_id` String,
`total_amount` Decimal(16, 2),
`create_time` DateTime
)
ENGINE = Distributed(logs,default, t_stock_local,hiveHash(sku_id));
在Destributed引擎中,需要指定几个参数,依次是: 集群名称、库名、本地表名、分片键。其中分片键必须是整型数字,可以使用rand()来返回一个随机数字,也可以是id这样一个int字段,如果id的数据分布不够均匀,也可以使用intHash64()函数进行一下散列。而对于sku_id,他是string类型的,所以要用 hiveHash函数转换一下。如果是随机分片可以用rand()。
后续就可以像使用一个普通表一样使用这个分布式表了。数据会分开存储到不同
分片的t_stock_local表当中。
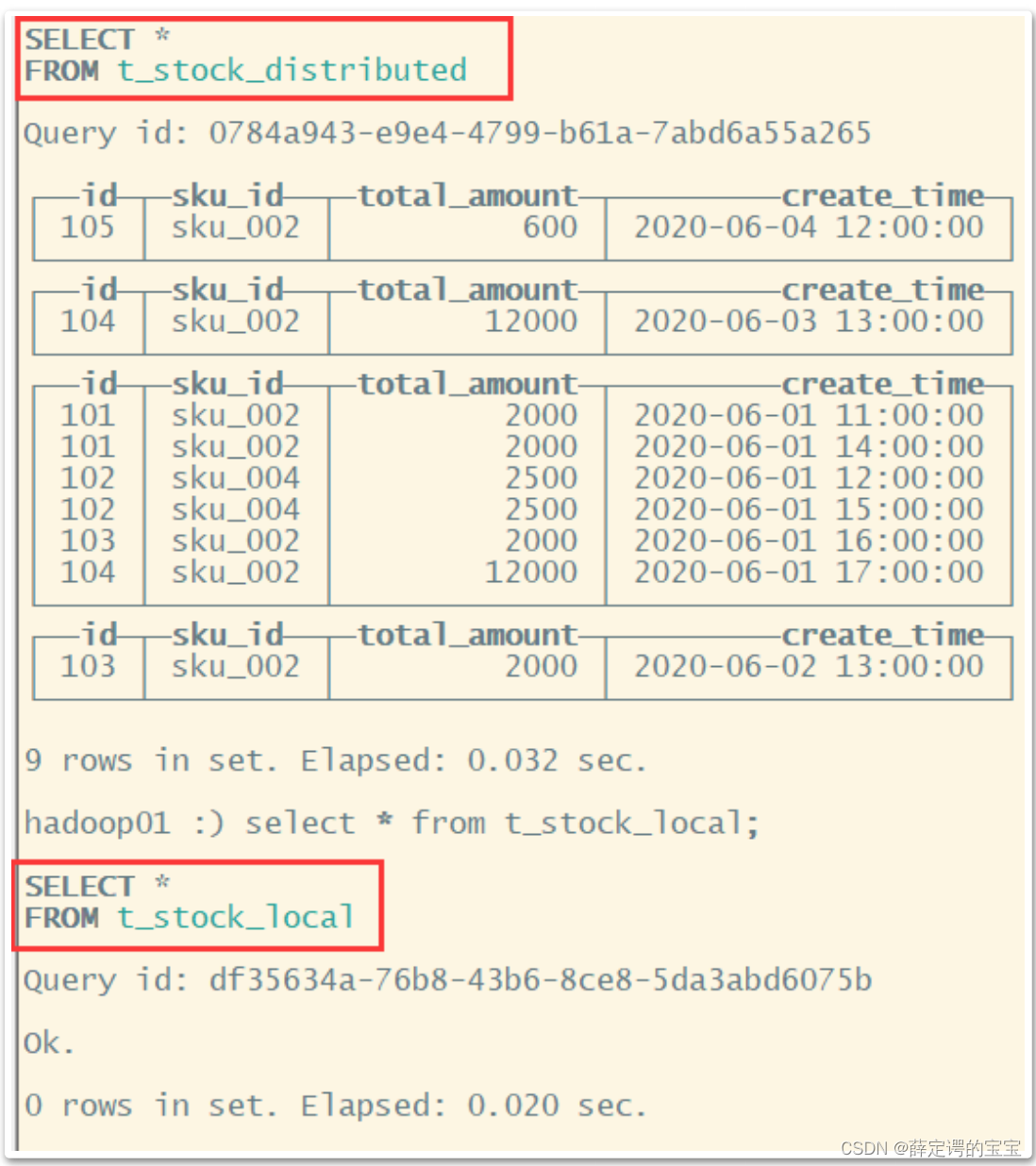
例如从下图中可以看到,在hadoop01机器上的t_stock_distributed表中可以查
到数据,但是在t_stock_local表中就没有数据。而数据全部写到了hadoop02机器
上的t_stock_local中。hadoop02机器上的分片有更大的权重。
最后注意,使用clickhouse,通常只建议使用数据副本,不建议使用分布式表!















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









