






最强OLAP分析引擎-Clickhouse快速上手四
五、配置优化
这一章主要分享如何优化clickhouse的配置。
对于clickhouse的配置优化,最为重要的,也就是对服务资源分配的优化。而对于clickhouse来说,消耗最多的系统资源其实就是CPU,CPU使用率也是对clickhouse服务进行监控的一个很重要的指标。**CPU使用率一般达到50%左右会出现查询波动,达到70%会出现大范围的查询超时。**所以通常建议clickhouse服务要进行单独的部署,尽量不要跟其他服务共用服务器。相比而言,对于内存和磁盘,由于clickhouse的数据压缩效率是非常高的,所以通常不会形成性能瓶颈。
clickhouse极简化的设计方式,使得这些配置项相比其他数据库是得到非常多的精简的。并且大部分的配置信息,clickhouse也都给出了默认值,大部分场景下,这些默认值都是最优化的。例如,对于内存,clickhouse并不像flink这类框架一样,设定框架内存、任务内存等等各种各样的内存参数。只在users.xml中设定了单个任务使用的内存上限,设置的值也是简单粗暴的10000000000 , 10G。具体配置在
users.xml中 -> -> <max_memory_usage> 参数。
clickhouse的配置文件集中在config.xml和users.xml两个配置文件里。config.xml的配置项参见官方文档:https://clickhouse.com/docs/zh/operations/server-configuration-parameters/settings/ users.xml的配置项参见官方文档:https://clickhouse.com/docs/zh/operations/settings/settings-users/ 。
其中config.xml主要是服务端参数,主要包含一些在session和query级别无法修改的参数,例如服务的集群配置,zookeeper配置等。而users.xml则是运行时参数,大部分可能对session和query产生影响。当然,这种拆分方式在clickhouse中其实并不是很严格。
对于运行时参数,有几个地方可以配置,读取的优先级依次如下:
- users.xml配置文件中。主要配置在 标签中,以不同配置文件的方式进行配置。默认提供了一个default的profile。另外,clickhouse也可以自行指定外部的配置
文件。 - Session配置。在一个客户端中执行 SET [settings] = [value] 语句的方式指定。
只对当前会话生效。 - 查询时指定。查询时可以有多个方式指定参数。HTTP接口可以直接在后面添加参数。使用clickhouse-client脚本的–settings=value 参数方式指定。或者在select 语句中直接指定。
下面列出clickhouse使用过程中比较有用的几个配置:
- background_pool_size 后台线程池的大小。默认16,实际生产中可以修改为CPU个数的2倍。
- max_concurrent_queries:最大并发请求数,默认值 100 。 通常不建议调整,如果并发要求高,可以以50为阶段调整。
- max_memory_usage: 单次查询使用的最大内存大小。默认100G。如果服务器的内存资源很丰富,可以适量调大一点。
- default_session_timeout :默认session断开时间,默认60秒。另外还有
- max_session_timeout。最大session断开时间,默认3600秒。需要控制客户端连接时长时可以定制。
- http_port: http接口访问端口,默认8123。clickhouse最重要的端口。不光在
- HTTP接口中用,jdbc,obdc驱动也使用这个端口。与Grafana等监控平台集成也可以通过这个端口。
- mysql_port:默认值9004。clickhouse在这个端口上,将会假装成一个mysql数据库。直接使用mysql的jdbc驱动包就可以连接。
- postgresql_port:默认值9005。clickhouse在这个端口上,将会假装成一个postgresql数据库。
- tcp_port: TCP协议与客户端通信的端口自。默认9000
- interserver_http_port: 默认9009。 clickhouse内部通信的端口。
六、查询优化
1、查看执行计划
执行计划是进行查询调优的重要参考。clickhouse中,可以使用explain语句很方便的查看SQL语句的执行计划。完整的explain使用语法如下:
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] SELECT ...
[FORMAT ...]
其中
- AST: 查看抽象语法树
支持查看所有类型的语句,不光是SELECT语句。
explain ast select number from system.numbers limit 10;
- SYNTAX:查询优化后的SQL语句
EXPLAIN SYNTAX SELECT * FROM system.numbers AS a, system.numbers AS b,system.numbers AS c;
- PLAN: 用于查看执行计划。
可以指定五个参数 - header: 打印各个执行步骤的header说明。默认0
- description: 打印执行步骤。默认1
- indexes: 显示索引使用情况。默认0。只对MergeTree表引擎有用。
- actions: 打印执行计划的详细信息。默认0.
- json: 以JSON格式打印执行计划。默认0.
EXPLAIN SELECT sum(number) FROM numbers(10) GROUP BY number % 4;
EXPLAIN json = 1, description = 0 SELECT 1 UNION ALL SELECT 2 FORMAT TSVRaw;
- PIPELINE: 用于查看pipeline计划。
可以指定三个参数: - header: 打印各个步骤的header信息。默认0
- graph: 打印以DOT图形语法描述的结果。默认0
- compact: 如果开启了graph,紧凑打印行。默认开启。
EXPLAIN PIPELINE SELECT sum(number) FROM numbers_mt(100000) GROUP BY number % 4;
2、clickhouse内置的语法优化规则
clickhouse底层提供了基于规则的SQL优化实现,会对一些低效的查询语句自动进行优化。这些优化的方式实际上也是我们写高效查询的一些指导。
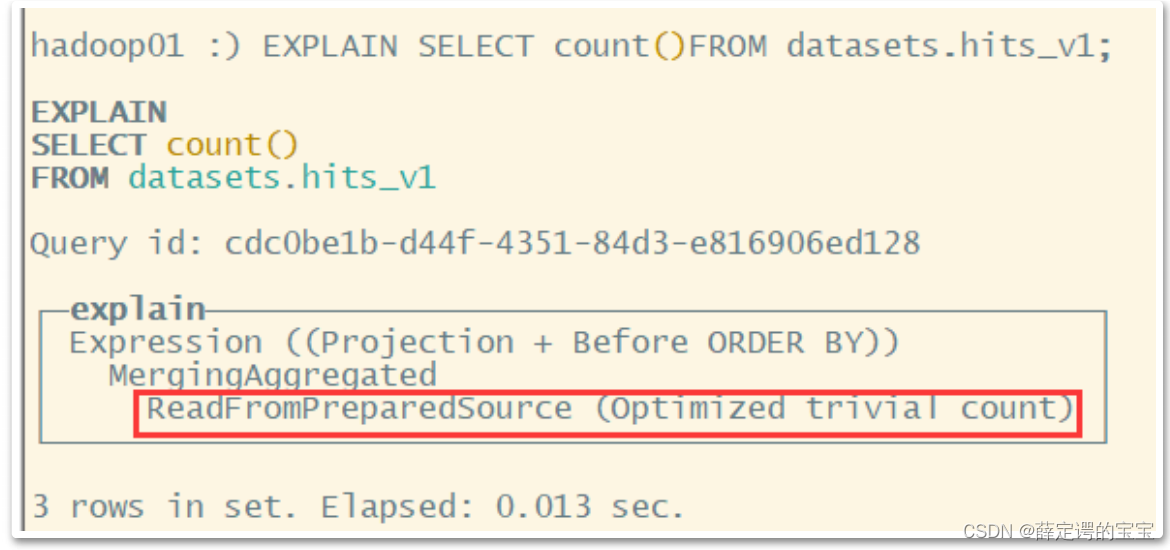
2.1、COUNT优化
在调用count时,如果使用的是count()或者count(*),且没有where条件时,会直接使用system.tables的total_row。
2.2、聚合计算外推
explain syntax select sum(UserID*2) from datasets.visits_v1;
优化为
SELECT sum(UserID) * 2 FROM datasets.visits_v1
2.3、谓词下推
当group by有having子句,但是没有with cube、with rollup或者with totals修饰的时候,having条件会提前到where过滤。
谓词下推优化规则涉及到一个参数enable_optimize_predicate_expression。默认是1,打开谓词下推。设置为0就会关闭谓词下推优化。
EXPLAIN SYNTAX SELECT UserID FROM datasets.hits_v1 GROUP BY UserID HAVING UserID = '8585742290196126178';
优化为
SELECT UserID FROM datasets.hits_v1 WHERE UserID = '8585742290196126178' GROUP BY UserID
2.4、三元运算优化
三元运算符会被替换成为multif函数。需要设定一个参数optimize_if_chain_to_multiif=1
EXPLAIN SYNTAX SELECT number = 1 ? 'yes' : (number = 2 ? 'no' : 'inknown') FROM numbers(10) settings optimize_if_chain_to_multiif = 1;
优化为
SELECT multiIf(number = 1, 'yes', number = 2, 'no', 'inknown') FROM numbers(10) SETTINGS optimize_if_chain_to_multiif = 1
2.5、聚合函数消除
如果对聚合建,也就是group by 使用min\max\any等无意义的聚合函数,则会将这些聚合函数消除掉
EXPLAIN SYNTAX
SELECT
sum(UserID * 2),
max(VisitID),
max(UserID)
FROM visits_v1
GROUP BY UserID
//返回优化后的语句
SELECT
sum(UserID) * 2,
max(VisitID),
UserID
FROM visits_v1
GROUP BY UserID
3、高性能查询优化
3.1、选择合适的表引擎
虽然MergeTree是clickhouse中最为常用的表引擎,但是也不意味着MergeTree适合所有的场景。
3.2、建表时不要使用Nullable
Nullable类型虽然在处理空值问题时非常简单好用,但是,官方已经指出
Nullable类型几乎总是会拖累性能,所以要尽量少用。在实际项目中,尽量使用字
段的默认值表示空,或者自行指定一个在业务中无意义的值。
这是因为存储Nullable列时需要创建一个额外的文件来存储NULL的标记,并且
Nullable列无法被索引。
3.3、合适的划分分区和索引
实际使用中,Partition by分区基本上是必须的。在划分分区时,通常建议按天分
区。如果自行分区的话,单分区的数据最好不要超过一百万行。
3.4、数据变更优化
对clickhouse数据的增删改操作都会产生新的临时分区,会给MergeTree带来额外的合并任务。因此,数据变更操作不宜太频繁,这样会产生非常多的临时分区。一次操作的数据也不能太快。临时分区写入过快会导致Merge速度跟不上而报错。
官方一般建议一秒钟发起一次左右的写入操作,每次操作写入的数据量保持在2W~5W之间。具体根据服务器性能而定。
3.5、使用Prewhere替代where
clickhouse还提供了一个Prewhere关键字。他的用法与where基本上一样的。但是不同之处在于prewhere只支持*MergeTree系列引擎。他会先读取指令的列数据,来判断数据过滤。等待数据过滤完成之后再读取select声明的列字段来补全其他属性。与之对比,where语句是读取整行各个列的数据,再进行过滤,IO性能明显下降。
默认情况下,clickhouse就会使用prewhere语句代替where。
explain syntax select WatchID from datasets.hits_v1 where UserID='3198390223272470366';
优化为:
select WatchID from datasets.hits_v1 prewhere UserID='3198390223272470366';
有一参数 set optimize_move_to_prewhere=0; 可以关闭where自动转化为prewhere的优化规则。但是通常没有必要。
6.6、指定列和分区
首先 在数据量很大时,应该避免使用select *。 而应该指定具体需要查询的列名。并且列应该越少越好。
这很好理解,因为clickhouse是以列来存储数据的。查询的列越少,需要读取的文件就越少。消耗的IO资源减少了,性能自然就提高了。
然后 在查询分区表时,应该尽量在where条件中指定分区键的查询条件。
clickhouse中的分区实际上对应一个本地目录。指定分区键的查询条件,同样可以减少查询所需要遍历的数据文件,减少IO资源消耗。
6.7、避免构建虚拟列
如非必要,尽量直接使用clickhouse中的表已有的列,不要将计算结果构建成不存在的虚拟列。这样会非常消耗资源,浪费性能。通常情况下,都可以在数据进入clickhouse之前进行处理。
反例:构建除了一个虚拟的IncRate列
SELECT Income,Age,Income/Age as IncRate FROM datasets.hits_v1;
正例:拿到 Income 和 Age 后,考虑在前端进行处理,或者在表中构造实际字段进行额外存储
SELECT Income,Age FROM datasets.hits_v1;
6.8、用IN代替JOIN
clickhouse支持使用JOIN进行关联查询,但是他的实现机制是将后面的表全部加载到内存中,然后跟前表数据在内存中进行合并。
当表的数据比较大时,对内存的消耗是非常大的。所以通常情况下,可以用IN代替JOIN。如果非要用JOIN时,也要尽量把大表写在前面,小表写在后面。这跟mysql建议用小表驱动大表恰好相反。
例如下面两个语句的查询逻辑基本上是一样的。但是查询耗时差距却非常大。
select a.CounterID from datasets.hits_v1 a where a.CounterID in (select
CounterID from datasets.visits_v1) limit 100;
-- 结果 100 rows in set. Elapsed: 0.047 sec. Processed 262.02 thousand rows,
1.05 MB (5.55 million rows/s., 22.21 MB/s.)
select a.CounterID from datasets.hits_v1 a left join datasets.visits_v1 b on
a. CounterID=b.CounterID limit 100;
--结果 100 rows in set. Elapsed: 0.156 sec. Processed 1.68 million rows, 6.71
MB (10.74 million rows/s., 42.98 MB/s.)
eg:
下一章该总结常见问题啦!持续关注!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









