






粒子群优化算法
一、算法介绍
粒子群优化算法的基本思想是通过群体中个体之间的协作和信息共享来寻找最优解。PSO的优势在于简单容易实现并且没有许多参数的调节。
1.1 问题提出
设想这样一个场景:一群鸟在随机的搜索食物。在这个区域里只有一块食物,所有的鸟都不知道食物在那。但是它们知道自己当前的位置距离食物还有多远。那么找到食物的最优策略是什么?最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
1.2 问题抽象
- 每只鸟抽象为一个无质量,无体积的“粒子”;
- 每个粒子有一个适应度函数以模拟每只鸟与食物的丰盛程度;
- 每个粒子有一个速度决定它的飞行方向和距离,初始值可以随机确定;
- 每次单位时间的飞行后,所有粒子分享信息,下一步将飞向自身最佳位置(pbest)和全局最优位置(gbest)的加权中心。
1.3 算法描述
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次的迭代中,粒子通过跟踪两个“极值”(pbest,gbest)来更新自己。
在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。
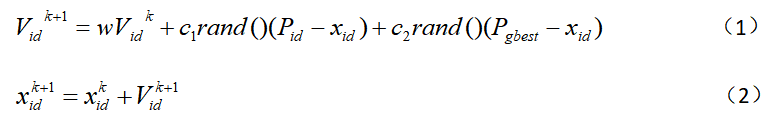
i=1,2,…,M,M是该群体中粒子的总数;Vid是粒子的速度; pbest和gbest是自身最佳位置和全局最优位置; rand()是介于(0、1)之间的随机数; xid是粒子的当前位置。 c1和c2是加速因子。 在每一维,粒子都有一个最大限制速度Vmax,如果某一维的速度超过设定的Vmax ,那么这一维的速度就被限定为Vmax 。( Vmax >0) 以上面两个公式为基础,形成了后来PSO 的标准形式。
1.4 算法流程
标准PSO算法的流程:
Step1:初始化一群微粒(群体规模为m),包括随机位置和速度;
Step2:评价每个微粒的适应度;
Step3:对每个微粒,将其适应值与其经过的最好位置 pbest作比较,如果较好,则将其作为当前的最好位置pbest;
Step4:对每个微粒,将其适应值与其经过的最好位置 gbest作比较,如果较好,则将其作为当前的最好位置gbest;
Step5:根据(1)、(2)式调整微粒速度和位置;
Step6:未达到结束条件则转Step2。
迭代终止条件根据具体问题一般选为最大迭代次数maxgen或微粒群迄今为止搜索到的最优位置满足预定最小适应阈值。
二、代码分析
2.1 Schaffer()函数
数学表达式:
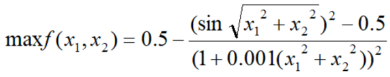
代码:
function y=Schaffer(x)
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=x(1,1);
y2=x(1,2);
temp=y1^2+y2^2;
y=0.5-(sin(sqrt(temp))^2-0.5)/(1+0.001*temp)^2;
y=-y;
2.1 Griewank()函数
数学表达式:
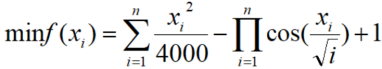
代码:
function y=Griewank(x)
%Griewan函数
%输入x,给出相应的y值,在x=(0,0,…,0)处有全局极小点0.
%编制人:
%编制日期:
[row,col]=size(x);
if row>1
error('输入的参数错误');
end
y1=1/4000*sum(x.^2);
y2=1;
for h=1:col
y2=y2*cos(x(h)/sqrt(h));
end
y=y1-y2+1;
%y=-y;
2.3 Rastrigin()函数
数学表达式:
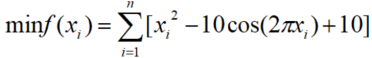
代码:
function y = Rastrigin(x)
% Rastrigin函数
% 输入x,给出相应的y值,在x = ( 0 , 0 ,…, 0 )处有全局极小点0.
% 编制人:
% 编制日期:
[row,col] = size(x);
if row > 1
error( ' 输入的参数错误 ' );
end
y =sum(x.^2-10*cos(2*pi*x)+10);
%y =-y;
2.4 Drawfunc(label)函数
作用:根据lable值画出待优化的函数,只画出二维情况作为可视化输出
部分代码解释:
[X,Y] = meshgrid(x,y)
%基于向量x和向量y中包含的坐标返回二维网格坐标。
%X是一个矩阵,其中每一行都是复制x;Y是一个矩阵,其中每一列都是复制y。
%矩阵X的行数是length(y);矩阵Y的列数是length(x)。
shading interp
%可以实现对不平滑的图像进行平滑
代码:
function Drawfunc(label)
x=-5:0.05:5;%1行201列的向量
if label==1
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Rastrigin([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==2
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Schaffer([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
if label==3
y = x;
[X,Y] = meshgrid(x,y);
[row,col] = size(X);
for l = 1 :col
for h = 1 :row
z(h,l) = Griewank([X(h,l),Y(h,l)]);
end
end
surf(X,Y,z);
shading interp
xlabel('x1-axis'),ylabel('x2-axis'),zlabel('f-axis');
title('mesh');
end
2.5 fun()函数
作用:函数用于计算粒子适应度值
代码:
function y = fun(x,label)
%函数用于计算粒子适应度值
%x input 输入粒子
%y output 粒子适应度值
if label==1
y=-Rastrigin(x);
elseif label==2
y=-Schaffer(x);
else
y=-Griewank(x);
end
2.6 主程序PSO.m
%% 清空环境
clc
clear
%% 参数初始化
%粒子群算法中的三个参数
c1 = 1.49445;%加速因子
c2 = 1.49445;
w=0.8; %惯性权重
maxgen=1000; % 进化次s数
sizepop=200; %种群规模
Vmax=1; %限制速度围
Vmin=-1;
popmax=5; %变量取值范围
popmin=-5;
dim=10; %适应度函数维数
func=2; %选择待优化的函数,1为Rastrigin,2为Schaffer,3为Griewank
Drawfunc(func);%画出待优化的函数,只画出二维情况作为可视化输出
%% 产生初始粒子和速度
for i=1:sizepop
%随机产生一个种群
pop(i,:)=popmax*rands(1,dim); %初始种群
V(i,:)=Vmax*rands(1,dim); %初始化速度
%计算适应度
fitness(i)=fun(pop(i,:),func); %粒子的适应度
end
%% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
gbest=pop(bestindex,:); %全局最佳
pbest=pop; %个体最佳
fitnesspbest=fitness; %个体最佳适应度值
fitnessgbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
fprintf('第%d代,',i);
fprintf('最优适应度%f\n',fitnessgbest);
for j=1:sizepop
%速度更新
V(j,:) = w*V(j,:) + c1*rand*(pbest(j,:) - pop(j,:)) + c2*rand*(gbest - pop(j,:)); %根据个体最优pbest和群体最优gbest计算下一时刻速度
V(j,find(V(j,:)>Vmax))=Vmax; %限制速度不能太大
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.5*V(j,:); %位置更新
pop(j,find(pop(j,:)>popmax))=popmax;%坐标不能超出范围
pop(j,find(pop(j,:)<popmin))=popmin;
if rand>0.98 %加入变异种子,用于跳出局部最优值
pop(j,:)=rands(1,dim);
end
%更新第j个粒子的适应度值
fitness(j)=fun(pop(j,:),func);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnesspbest(j)
pbest(j,:) = pop(j,:);
fitnesspbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnessgbest
gbest = pop(j,:);
fitnessgbest = fitness(j);
end
end
yy(i)=fitnessgbest;
end
%% 结果分析
figure;
plot(yy)
title('最优个体适应度','fontsize',12);
xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
三、参数测试
3.1 加速因子c1、c2,惯性权重w
目标函数有3个,依次测试:
①Rastrigin

②Schaffer

②Griewank

测试惯性权重w
w是保持原来速度的系数,所以叫做惯性权重。
固定参数:
| 迭代次数maxgen | 种群规模sizepop | 加速因子c1 | 加速因子c2 |
|---|---|---|---|
| 500 | 100 | 1.49445 | 1.49445 |
变参:惯性权重w
首先分析不同w值时的PSO算法收敛曲线:
分别取w=0.9、0.8、0.6、0.4,得到最优适应度曲线如下所示:

从上图可以看出,w=0.9时,微粒以更少的迭代次数取得全局最优;w=0.8、0.6时,迭代次数次之,
w=0.2时,迭代次数相对较多。可知,w越大,微粒飞行速度越大,微粒将以较大的步长进行全局搜索;w越小,则微粒步长小,趋向于精细的局部搜索。
虽然较大的权重因子有利于跳出局部最小值,便于全局搜索,而较小的惯性因子则有利于对当前的搜索区域进行精确局部搜索,以利于算法收敛;但是w过大容易导致“早熟收敛”与算法后期在全局最优解附近产生振荡的现象。
w的改进:把wmax逐渐变成wmin
采用线性递减,设置公式:
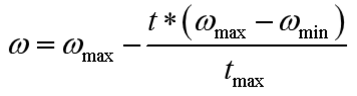
代码如下:
w=wmax-(i*(wmax-wmin))/maxgen;
分别取不同组wmax、wmin,测试最优参数:
①目标函数为Rastrigin
wmax=0.9,wmin=0.1

wmax=0.9,wmin=0.2

wmax=0.8,wmin=0.2

wmax=0.7,wmin=0.3

wmax=0.6,wmin=0.2

②目标函数为Schaffer
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| wmax=0.9,wmin=0.1 | 0 | 32 | 10.299s |
| wmax=0.9,wmin=0.2 | 0 | 30 | 8.493s |
| wmax=0.8,wmin=0.2 | 0 | 56 | 8.256s |
| wmax=0.7,wmin=0.3 | 0 | 78 | 8.476s |
| wmax=0.6,wmin=0.2 | 0 | 85 | 8.213s |
③目标函数为Griewank
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| wmax=0.9,wmin=0.1 | 0 | 37 | 10.657s |
| wmax=0.9,wmin=0.2 | 0 | 31 | 10.818s |
| wmax=0.8,wmin=0.2 | 0 | 30 | 8.871s |
| wmax=0.7,wmin=0.3 | 0 | 31 | 8.980s |
| wmax=0.6,wmin=0.2 | 0 | 35 | 9.874s |
结论:w越大,微粒飞行速度越大,微粒将会以更长的步长进行全局搜索;w较小,则微粒步长小,趋向于精细的局部搜索;因此,我们采用动态改变w的值;在搜索初期设w取一个较大值,然后随着迭代次数的不断增加,逐渐降低w的值;从而达到全局最优。从以上结果来看,对于目标函数Schaffer和Griewank,权重的改变没有引起结果明显的变化,对于目标函数Rastrigin,当取wmax=0.8,wmin=0.2时,可以得到较优化的结果。
测试加速因子c1,c2
c1是粒子跟踪自己历史最优值的权重系数,它表示粒子自身的认识,所以叫“认知”。
c2是粒子跟踪群体最优值的权重系数,它表示粒子对整个群体知识的认识,所以叫做“社会知识”,经常叫做“社会”。
固定参数:
| 迭代次数maxgen | 种群规模sizepop | wmax | wmin |
|---|---|---|---|
| 500 | 100 | 0.8 | 0.2 |
变参:加速因子c1,c2
给c1、c2设置线性变换:
c1=c1a-(i*(c1a-c1b))/maxgen;
c2=c2a-(i*(c2a-c2b))/maxgen;
其中,c1a、c1b表示c1随迭代次数呈线性变化的端点,变化范围为c1a~c1b;
c2a、c2b表示c2随迭代次数呈线性变化的端点,变化范围为c2a~c2b。
①目标函数为Rastrigin
c1:2——>1,c2:1——>2

c1:1——>2,c2:2——>1

c1:1.5——>1,c2:1——>1.5

②目标函数为Schaffer
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| c1:2——>1,c2:1——>2 | 0 | 24 | 6.382s |
| c1:1——>2,c2:2——>1 | 0 | 32 | 6.626s |
| c1:1.5——>1,c2:1——>1.5 | 0 | 30 | 6.405s |
③目标函数为Griewank
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| c1:2——>1,c2:1——>2 | 0 | 53 | 7.549s |
| c1:1——>2,c2:2——>1 | 0 | 55 | 7.296s |
| c1:1.5——>1,c2:1——>1.5 | 0 | 62 | 7.534s |
结论:c1,c2具有自我总结和向优秀个体学习的能力,从而使微粒向群体内或领域内的最优点靠近。c1,c2分别调节微粒向个体最优或者群体最优方向飞行的最大步长,决定微粒个体经验和群体经验对微粒自身运行轨迹的影响。加速因子较小时,可能使微粒在远离目标区域内徘徊;加速因子较大时,可使微粒迅速向目标区域移动,甚至超过目标区域。因此,c1和c2的搭配不同,将会影响到PSO算法的性能。
根据以上运行结果,对于目标函数Schaffer和Griewank,二者对于不同的c1、c2取值均能得到最优解0,从收敛时迭代次数与运行时间判断当变化趋势为c1:2——>1,c2:1——>2时略优于其他组合。对于目标函数Rastrigin,可以看出当c1随迭代次数的增加而递减,c2随迭代次数的增加而递增时可以得到较为优化的效果,可以取c1的变化范围2——>1,c2的变化范围1——>2。
3.2 适应度函数维数dim,种群规模sizepop
测试适应度函数维数dim
固定参数:
| 迭代次数maxgen | 种群规模sizepop | 加速因子c1 (c1a、c1b) | 加速因子c2(c2a、c2b) |
|---|---|---|---|
| 500 | 100 | 2、1 | 1、2 |
①目标函数为Rastrigin
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| dim=5 | 4.394795 | 181 | 7.547s |
| dim=10 | 0.994959 | 97 | 8.843s |
| dim=15 | 2.769735 | 100 | 8.701s |
| dim=20 | 8.975471 | 112 | 8.882s |
| dim=30 | 11.924386 | 108 | 8.406s |
②目标函数为Schaffer
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| dim=5 | 0 | 15 | 4.776s |
| dim=10 | 0 | 40 | 6.995s |
| dim=15 | 0 | 28 | 7.045s |
| dim=20 | 0 | 19 | 8.093s |
| dim=30 | 0 | 30 | 9.405s |
③目标函数为Griewank
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| dim=5 | 0 | 78 | 6.146s |
| dim=10 | 0 | 22 | 6.565s |
| dim=15 | 0 | 26 | 6.126s |
| dim=20 | 0 | 171 | 6.619s |
| dim=30 | 0 | 180 | 7.355s |
结论:如以上结果所示,对于目标函数为Rastrigin:当维度过小时,得到的最优适应度值很大,说明陷入局部最优,当维度过大时,会导致算法执行时间变长。维度10维左右得到的结果接近最优。
对于目标函数为Rastrigin与Griewank,二者在维度取值不同的情况下均能达到最优,所不同的是维度小的运行时间短、迭代次数少,维度多的反之。
测试种群规模sizepop
固定参数:
| 迭代次数maxgen | 维数dim | 加速因子c1 (c1a、c1b) | 加速因子c2(c2a、c2b) |
|---|---|---|---|
| 500 | 10 | 2、1 | 1、2 |
变参:种群规模sizepop
①目标函数为Rastrigin
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| sizepop=50 | 2.984877 | 78 | 5.378s |
| sizepop=100 | 2.874563 | 137 | 6.753s |
| sizepop=150 | 1.346735 | 324 | 7.356s |
| sizepop=200 | 1.364973 | 360 | 7.477s |
| sizepop=300 | 1.415378 | 371 | 8.197s |
②目标函数为Schaffer
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| sizepop=50 | 0 | 61 | 2.758s |
| sizepop=100 | 0 | 39 | 4.892s |
| sizepop=150 | 0 | 44 | 7.537s |
| sizepop=200 | 0 | 46 | 8.885s |
| sizepop=300 | 0 | 51 | 9.588s |
③目标函数为Griewank
| 运行10次取平均值 | 最优适应度 | 收敛时迭代次数 | 运行时间 |
|---|---|---|---|
| sizepop=50 | 0 | 21 | 3.365s |
| sizepop=100 | 0 | 29 | 6.016s |
| sizepop=150 | 0 | 18 | 8.263s |
| sizepop=200 | 0 | 23 | 9.833s |
| sizepop=300 | 0 | 28 | 10.942s |
结论:N设置较小时,算法收敛速度快,但是容易陷入局部最优;N设置较大时,算法收敛速度相对较慢;导致计算时间大幅增加,而且群体数目N增至一定的水平时,再增加微粒数目不再有显著的效果。根据以上测试结果,可以取种群规模为150~200.
四、小结
PSO算法的搜索性能取决于其全局搜索与局部改良能力的平衡,这很大程度上依赖于算法的参数控制,包括N,Vmax,M,w,c1,c2等。选择合适的参数组合,有利于利用该算法求得最优解,参数的选择影响算法的性能和效率,也是一个值得优化的问题。在测试参数时,也需要考虑到该参数在程序中是否呈线性变换,若是,则给出变化范围,测试多组,找出最优参数值。















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









