







前言
讲了这么多章,终于讲到map集合了。之前讲set集合,其底层都是通过map实现的,所以在讲底层结构的时候,都没有怎么细讲。现在终于到map集合了,我们将会详细的讲解各个map集合。首先讲解的是HashMap集合,它可是最常用的一个map集合了,也可能是面试问的最多的一个了。
HashMap的常用方法
和之前的list和set集合不一样,map集合的常用方法为put和get,如下图
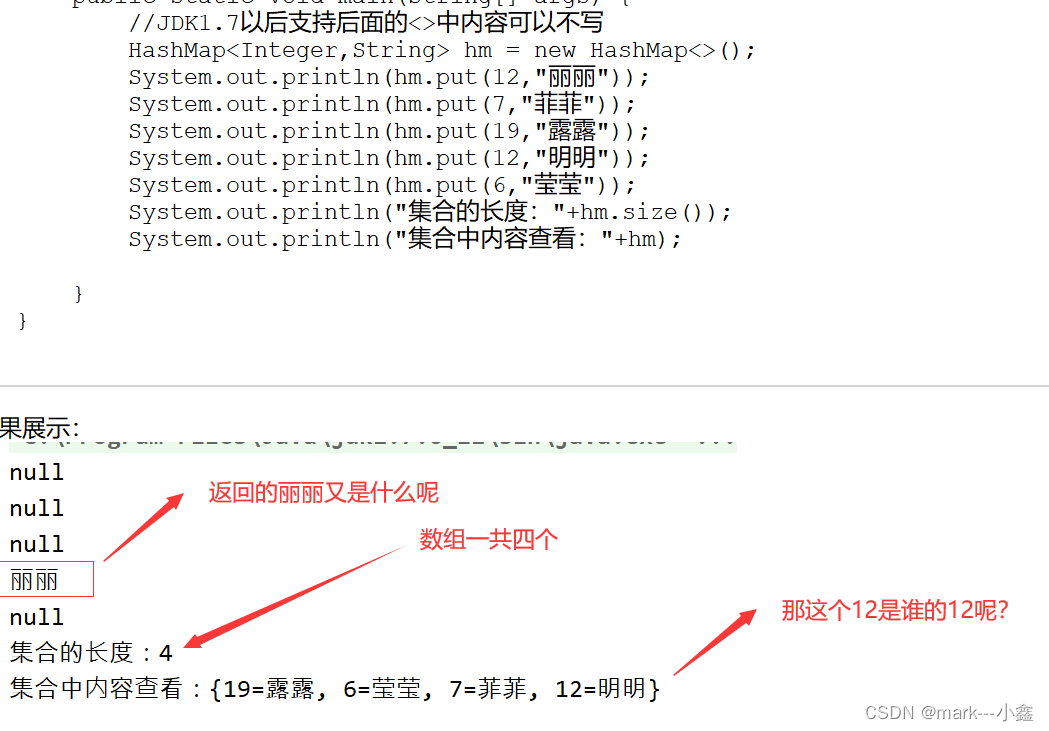
这里我和大家解释下这个丽丽怎么回事。首先呢,之前在set集合的时候,我就和大家说过,hashmap的key是不允许重复的,所以它在添加相同的key的值的时候,它会把之前key对应的value值返回,然后把当前的key对应的value值覆盖掉之前的key对应的value值,所以才会出现上面的哪个丽丽。至于那个12,是丽丽的12,只会替换value值,不会替换key值,所以12是丽丽的12。
HashMap的遍历
Hashmap的遍历方式有四种,这里我们挑一种展示,剩下的就不展开叙述了。
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
for(Map.Entry<Integer, Integer> entry : map.entrySet()){
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue())
}
HashMap的底层原理
在看底层原理之前我们首先的知道,hashmap的底层结构是数组加链表加上红黑树。接着我们先看下HashMap的属性和构造方法

DEFAULT_INITIAL_CAPACITY是初始化的数组长度,MAXIMUM_CAPACITY是最大数组长度,0.75f是加载因子,也叫扩容因子,随便叫什么。TREEIFY_THRESHOLD链表什么长度的时候,转变为红黑树。UNTREEIFY_THRESHOLD树什么时候退化为链表。MIN_TREEIFY_CAPACITY变红黑树的最小数组长度。
上面的是它的属性,接下来,我们看它的方法。首先是构造方法。
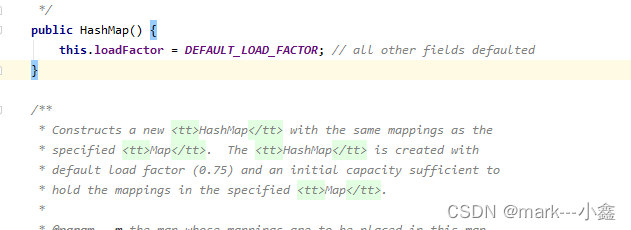
如上图,我们可以看出,它的构造方法只做了一件事,就是给加载因子赋了一个默认值,也就是0.75。那它什么时候初始化数组的呢,接下来看put方法。
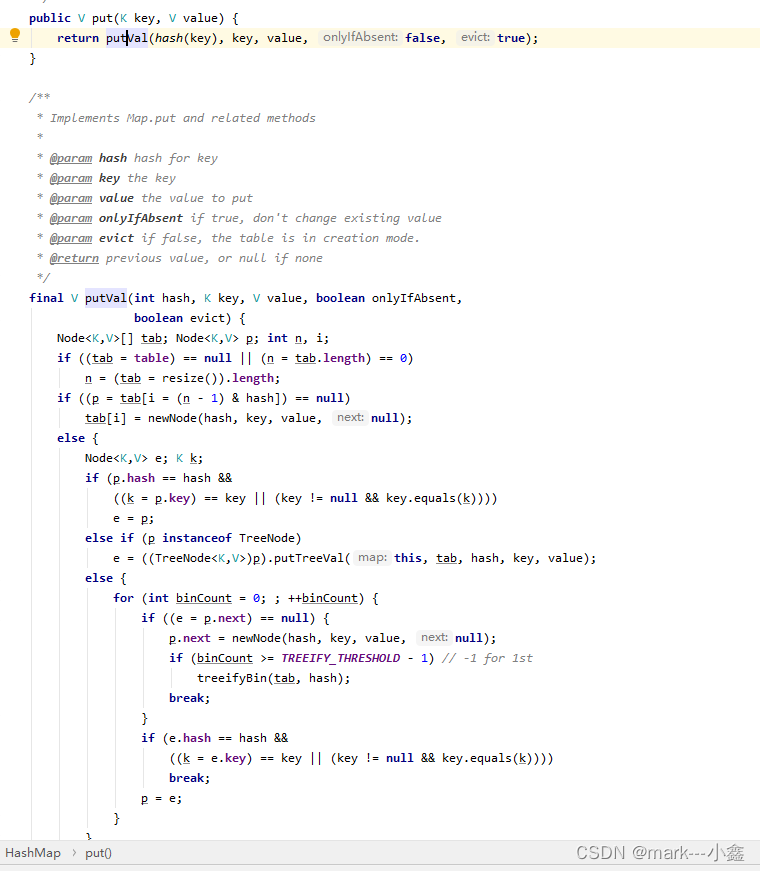
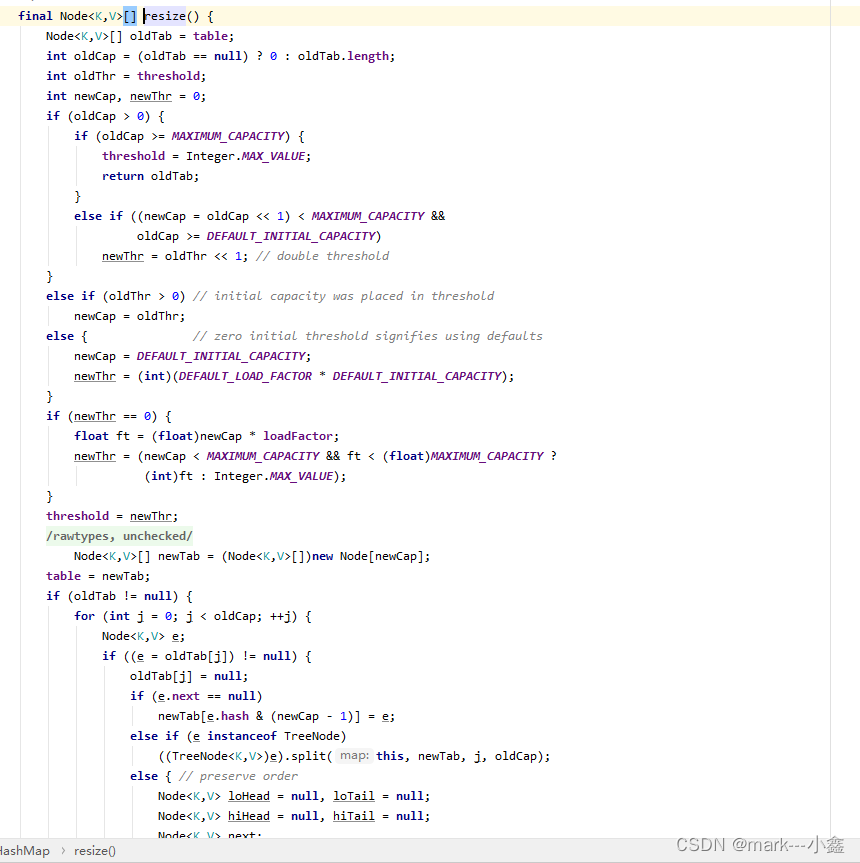
由上面两个图,我们可以看出,初始化实在put的时候进行输出化,首先判断table是不是空,如果事空,再通过resize方法进行数组的初始化。然后通过hash函数,找到再数组上对应的位置,判断该位置是否为空,为空则把数组该位置的值设置为当前值,如果不为空,则添加到该位置的链表上。往链表调价的时候,首先判断是不是变为了树,如果是,则以树添加节点的方式添加该节点,如果不是。首先判断链表长度是不是大于8,也就是之前的属性。如果没大于,就添加到链表的末尾,如果大于,则开始判断如下图

他会判断数组的长度是不是大于变树的长度限制,如果没有,就对数组进行扩容,如果有,则把链表转换为树。最后put方法末尾再对数组内容进行判断,看有比例有没有到加载因子大小,来判断需不需要扩容。
总结
这里只是对源码的主要流程和属性进行介绍,不可能一行一行的介绍,那样篇幅过于长,大家也会看不下去的。从上面的内容我们可以知道,数组扩容的条件是数组的内容长度比例达到加载因子,和某一个链表长度大于8,数组长度小于64,都会导致扩容,这个和jdk1.7还是有很大区别的,还有数组的初始化,也由以前的构造函数挪到put方法里面了,而链表转红黑树的条件,也由之前的链表长度大于8即可,变为现在数组长度大于64,链表长度大于8,才会转换。
















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











