






 本文详细阐述了WebRTC音视频通话的四个关键步骤,包括PCFactory创建、媒体组件构建、SDP协商以及多线程模型。重点介绍了Capturer、Source、Track和Transceiver的角色,以及P2P、SFU和MCU的不同网络结构在大规模通话中的优缺点。
本文详细阐述了WebRTC音视频通话的四个关键步骤,包括PCFactory创建、媒体组件构建、SDP协商以及多线程模型。重点介绍了Capturer、Source、Track和Transceiver的角色,以及P2P、SFU和MCU的不同网络结构在大规模通话中的优缺点。
音视频通话步骤

核心API
-
Capturer:负责数据采集,只有视频才有这一层抽象,有多种实现,包括相机采集、录屏采集、视频文件采集等;
-
Source:数据源,数据来自于Capturer,把数据交给Track;
-
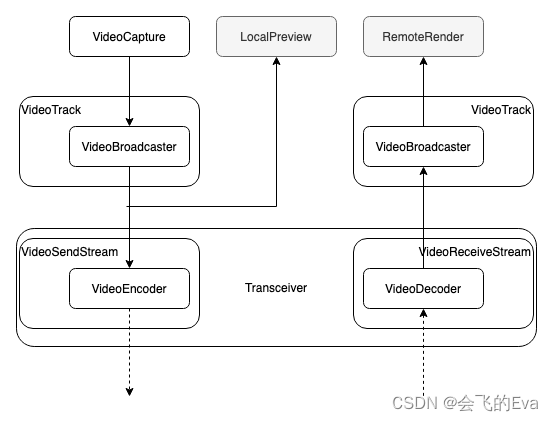
Track:媒体数据交换的载体,发送端把本地的Track发送给远程的接收端;
-
Sink:Track数据的消费者,只有视频才有这一层封装。发送端视频的本地预览、接收端收到远程视频后的渲染都是Sink;
Transceiver:负责收发媒体数据(以Track为载体);
以视频为例,数据由发送端的Capturer采集,交给Source,再交给本地的Track,然后兵分两路:一路由本地Sink进行预览,一路由Transceiver发送给接收端。接收端Track把数据交给Sink渲染。
音视频通话关键4步:
-
创建PC Factory,创建PC;
-
创建Capturer、Source、Track、Transceiver;
-
创建Offer,Answer,并互相交换;
-
互相交换ICE Candidate;
了解SDP
SDP是用来协商绘画能力的协议,通过Offer/Answer机制进行协商;
线程模型
WebRTC 作为一个实时音视频通信系统,包含了信令控制、音视频传输、音视频采集、音视频编码、音视频解码、音视频渲染等所有功能。由于其功能多样性,注定了系统结构的复杂性,再加上音视频需要做很多编码前后的处理,算法非常复杂,逻辑结构也复杂。为了在复杂网络环境下,保证音视频通信的流畅性,WebRTC 还做了很多流控、带宽预测、拥塞控制算法。
为此,为了降低系统的复杂性,提高系统的运行效率,WebRTC 设计了一套多线程框架,并且做了精心的设计。下来我们就分析一下 WebRTC 中的线程模型。
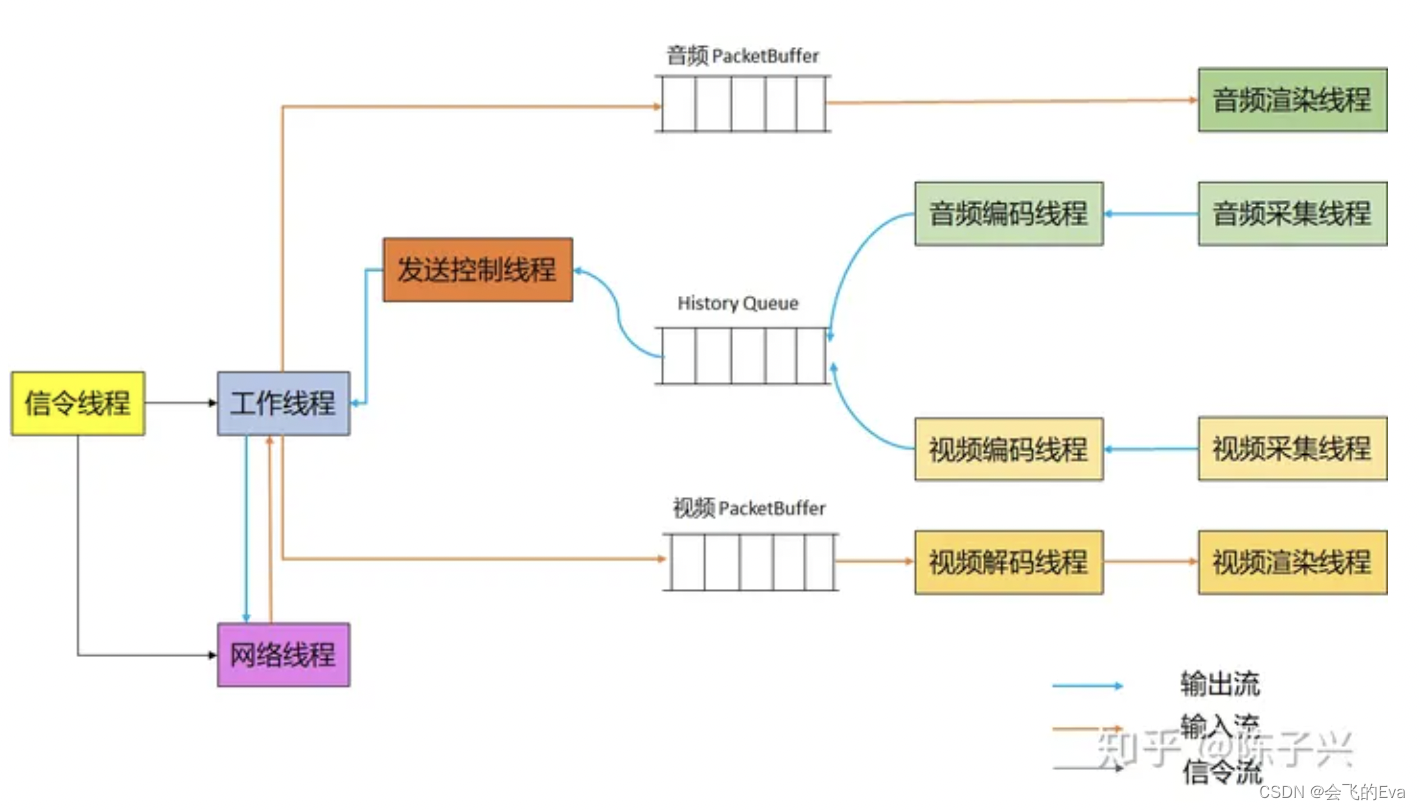
图中每一个矩形框都代表了一个线程,我们这里列出了 11 个线程,当然这些是最主要的线程。线程之间的通信要么是通过图中标出的 Packet 队列,要么是通过 WebRTC 的 MessageQueue 来实现的。图中蓝色的线和橘色的线分别标出了数据包输出和输入时,在各个线程流向情况。
图中标出的信令线程、工作线程、网络线程,WebRTC 是允许定制的。
-
信令线程(Signal Thread)
一般是工作在 PeerConnection 层,主要是完成控制平面的逻辑,用于和应用层交互。比如,CreateOffer,SetRemoteSession 等接口都是通过 Signal threa 完成的。默认是采用 PeerConnectionFactory 初始化线程作为信令线程。 -
工作线程(Worker Thread)
主要是工作在媒体引擎层(media engine),具体工作如下:-
音频设备初始化
-
视频设备初始化
-
流对象的初始化
-
从网络线程接收数据,传给解码器线程
-
从编码器线程接收数据,传给网络线程
-
-
网络线程(Network thread )
主要是工作在传输(transport)层,具体工作如下:-
Transport 的初始化
-
从网络接收数据,发送给 Worker thread
-
从 Worker thread 接收数据,发送到网络
-
-
视频采集线程
主要工作是完成视频原始数据的采集。在 Windows 上,这个线程是由directshow 提供。视频数据接收函数是 CaptureInputPin::Receive,实现文件是http://sink_filter_ds.cc。 -
视频编码线程
主要工作是对视频的原始数据进行编码,从 Capture 接收 VideoFrame,然后调用编码器执行编码逻辑,将编码后的视频数据发送到 PacerSender。视频编码线程是通过 TaskQueue 实现的,线程名称是 EncodeThread。具体实现位置是 VideoStreamEncoder::TaskQueue,文件名是 video/video_stream_encoder.h。 -
视频解码线程
主要工作就是视频解码,具体如下:-
从工作线程接收数据,然后调用视频解码器执行解码逻辑。
-
将解码后的视频数据发送给渲染线程。
-
具体实现的线程函数是 VideoReceiveStream::DecodeThreadFunction ,实现文件是 video/http://video_receive_stream.cc。
-
视频渲染线程
主要工作是将解码后的视频图像发送给上层应用,进行渲染。具体实现类是
IncomingVideoStream::NewFrameTask,通过 rtc::QueuedTask 实现的。 -
音频采集线程
主要工作是音频输入采集,比如采集麦克风声音。在 Windows 平台的线程函数 是 AudioDeviceWindowsCore::WSAPICaptureThread。线程名称是“webrtc_core_audio_capture_thread”,实现文件是
http://audio_device_core_win.cc。 -
音频编码线程
主要工作是从音频采集线程接收数据,调用音频编码器进行编码,然后将编码后的数据发送给 PaceSender。实现类是 Channel,通 rtc::TaskQueue 实现的。线程名称是 call_worker_queue,实现文件是 audio/channel.h。 -
音频渲染线程
音频渲染线程也是音频解码线程。在 Windows 平台下,线程函数是 AudioDeviceWindowsCore::WSAPIRenderThread,线程名称是“webrtc_core_audio_render_thread”。 -
发送控制线程
主要工作是定时发送音频、视频 rtp 包,线程名称是 SendControllerThread。
列出了主要的线程。之所以要分析线程模型,因为 WebRTC 明确规定了哪些模块在哪些线程下执行,在 Debug 版本中增加了很多检测,如果哪个模块没有在自己的线程下执行,会产生 abort 异常,程序自动退出。
视频数据流程
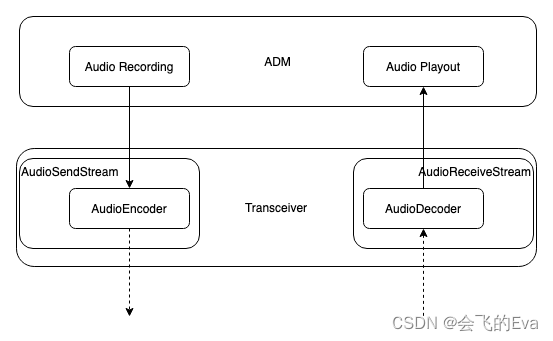
音频数据流程
DataChannel
DataChannel是WebRTC提供的传输任意数据的API,使用SCTP协议,可以灵活配置是否可靠传输。可以用它实现文字聊天、文件分享、实时对战游戏等场景下的数据传输,传输的数据都会通过DTLS协议进行加密,保证了传输数据的安全性。
多人通话
1、P2P 网状结构:参与通话的每个用户都和其他所有用户一一建立P2P连接,进行音视频数据的发送和接收;
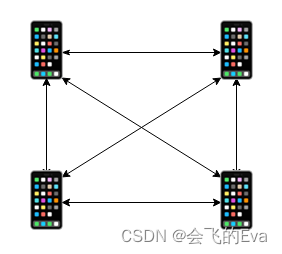
上图可以看到每个用户都有三路P2P连接,且都需要发送和接收数据,即每个用户都有三路上传和三路下载。这种结构在用户数量不多的时候还能正常运行,但是每增加一个用户,其他所有用户都会增加一路上传和一路下载,目前常见的互联网接入方式都是上传宽带比下载带宽低很多,所以上传很快就会出现带宽不够的情况。如果通话用户数量增加到十几个时,下载也可能会出现带宽问题,所以P2P网状结构只能应对人数较少的情况。
P2P模式最大的好处是可以减少对媒体服务器的需求,降低成本,不过在P2P模式下的网络情况不受控制,服务质量难以保证。
2、SFU 结构:参与通话的每个用户都把音视频数据发送给媒体服务器,并从媒体服务器接收其他所有用户的音视频数据,这些接收的音视频数据都是各自独立的;
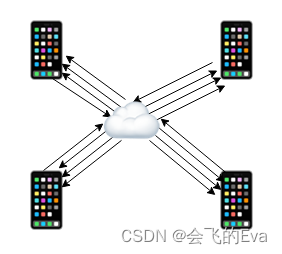
上图可以看到每个用户都有四路和服务器的连接,其中一路发送数据、三路用于接收数据,即每个用户都有一路上传和三路下载。SFU结构相比于P2P网络结构,最明显的优点是只需要一路上传,不过每增加一个用户,其他所有用户仍会增加一路下载,所有SFU结构仍然无法应对人数很多的情况。
SFU结构引入了媒体服务器,服务器的网络情况比较可控,更容易保证服务质量。SFU结构下的服务器值需要转发音视频数据,不需要做转码处理,所以计算成本不会很高,主要是宽带成本。同时,没有转码处理也就意味着不会引入中间处理的延迟,用户之间的通话的延迟可以得到保障。
3、MCU结构:参与通话的每个用户都把音视频数据发送给媒体服务器,媒体服务器把所有用户发送的音视频数据合成一体后,下发给每个用户,这样每个用户只需要从媒体服务器接受一路音视频数据;
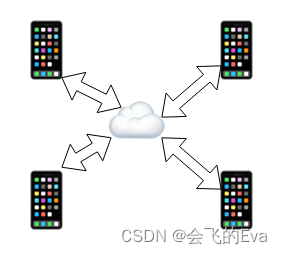
图上可以看到每个用户都只有一路和服务器的连接,用户发送和接收数据,即每个用户都只有一路上传和一路下载,有服务器负责把多个用户的音频和视频合成为一路音视频后下发给每个用户。这样增加新的用户,其他用户都不会增加上传和下载,可以应对人数很多的情况。
MCU结构最大的好处就是可以支持很多用户的情况,不过音视频的合成过程需要大量的计算资源,尤其是视频的解码和编码过程。此外MCU结构所需的带宽资源也比SFU结构低很多,因为每个用户都只需要下载一路音视频数据。同时,音视频的合成不仅会占用大量的计算资源,还会引入额外的处理延迟,因此MCU结构的延迟通常比SDU结构高不少。
视频编码格式
VP8、VP9和H.264三种编码格式,VP9是VP8的下一代编码格式,压缩效率更好,复杂度也更高。H.265是H.264的下一代编码格式。实践表明H.265压缩效率比VP9高出20%左右。
为了增加一种新的视频编码格式,主要涉及三大块工作:
-
让新的编码格式出现在SDP中;
-
实际数据的编解码;
-
RTP载荷的封包与解包;















 2736
2736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









