









这篇博客主要讲述使用srs_librtmp拉音频流(aac),srs版本为3.0版本。关于flv介绍,以及srs_librtmp拉视频流(h264),可以看《RTMP拉流保存h264(flv保存为h264)》https://blog.csdn.net/qq_41824928/article/details/103876328
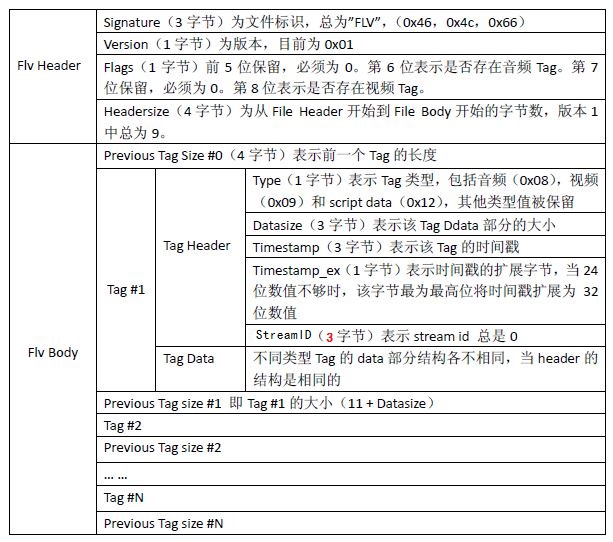
srs通过接口 srs_rtmp_read_packet 来从rtmp拉流获取音视频数据包,即上表中的Tag Data. 函数原型为:
int srs_rtmp_read_packet(srs_rtmp_t rtmp, char* type, uint32_t* timestamp, char** data, int* size);
可以通过type来过滤是数据包是音频数据、视频数据、script数据。例如:
char *data = nullptr;
int size = 0;
uint32_t timestamp = 0;
char type = 0;
if (srs_rtmp_read_packet(_rtmp, &type, ×tamp, &data, &size) != 0) {
return -1;
}
if (type == SRS_RTMP_TYPE_VIDEO) {
//video data
} else if (type == SRS_RTMP_TYPE_AUDIO) {
//audio data
} else if (type == SRS_RTMP_TYPE_SCRIPT) {
//script data
} else {
//ignore
}本博客只解析Audio Data. 通过srs_rtmp_read_packet得到的data为Audio Tag Data, 由Header + Data两部分组成。
特别注意的是:当SoundFormat == 10(AAC)时,才会多出一个字节,表示AACPacketType。当SoundFormat != 10时,则SoundType后紧跟就是音频数据了,而没有AACPacketType。
AudioTag Header
| Field | Type | Comment | notice |
| SoundFormat | UB [4] | Format of SoundData. The following values are defined: 0 = Linear PCM, platform endian 1 = ADPCM 2 = MP3 3 = Linear PCM, little endian 4 = Nellymoser 16 kHz mono 5 = Nellymoser 8 kHz mono 6 = Nellymoser 7 = G.711 A-law logarithmic PCM 8 = G.711 mu-law logarithmic PCM 9 = reserved 10 = AAC 11 = Speex 14 = MP3 8 kHz 15 = Device-specific sound Formats 7, 8, 14, and 15 are reserved. AAC is supported in Flash Player 9,0,115,0 and higher. Speex is supported in Flash Player 10 and higher. | |
| SoundRate | UB [2] | Sampling rate. The following values are defined: 0 = 5.5 kHz 1 = 11 kHz 2 = 22 kHz 3 = 44 kHz | Sampling rate For AAC: always 3 |
| SoundSize | UB [1] | Size of each audio sample. This parameter only pertains to uncompressed formats. Compressed formats always decode to 16 bits internally. 0 = 8-bit samples 1 = 16-bit samples | Size of each sample. This parameter only pertains to uncompressed formats. Compressed formats always decode to 16 bits internally. |
| SoundType | UB [1] | Mono or stereo sound 0 = Mono sound (单声道) 1 = Stereo sound (双声道、立体声) | Mono or stereo sound For Nellymoser: always 0 For AAC: always 1 |
| AACPacketType (IF SoundFormat == 10) | UI8 | The following values are defined: 0 = AAC sequence header 1 = AAC raw |
If the SoundFormat indicates AAC, the SoundType should be 1 (stereo) and the SoundRate should be 3 (44 kHz).
However, this does not mean that AAC audio in FLV is always stereo, 44 kHz data. Instead, the Flash Player ignores
these values and extracts the channel and sample rate data is encoded in the AAC bit stream.
AudioSpecificConfig
当AACPacketType == 0 时,data数据部分是 AAC sequence header。 AAC sequence header 也就是 AudioSpecificConfig,在ISO14496-3 Table 1.15 – Syntax of AudioSpecificConfig()中有定义。
AudioSpecificConfig在FLV文件中一般情况也是出现1次,也就是第一个audio tag。
当AACPacketType == 1时,是AAC raw原始音频数据,在组成 AAC ADTS Header时需要用到AudioSpecificConfig中的信息。
AudioSpecificConfig的结构异常复杂(ISO14496-3表1.15)但实际上我们并不需要全部解析出来。图中蓝色圈框出的部分,为ffmpeg解析的部分,连ffmpeg都没有做全部的解析,那我们还管其他的干鸟!!实际上,AAC ADTS Header只需要红色圈框出来的部分,所以我们只用解析红色圈框出来的部分即可。

audioObjectType定义如下表(ISO14496-3表1.1):

由Table1.1可以看出,当audioObjectType == SBR时(HE-AAC v1),使用了“频段复制”(SBR,英语:Spectral Band Replication)提高频域的压缩效率;当audioObjectType == PS时(HE-AAC v2),结合使用SBR和参数立体声(PS,英语:Parametric Stereo)提高立体声信号的压缩效率。
HE:“high efficiency”(高效性)。
HE-AAC v1(又称AACPlusV1,SBR)用容器的方法加了原AAC(LC)+SBR技术。SBR其实代表的是Spectral Band Replication(频段复制)。简单概括一下,音乐的主要频谱集中在低频段,高频段幅度很小,如果对整个频段编码,要么为了保护高频造成低频段编码过细以致文件巨大,要么为了保存了低频的主要成分而失去高频成分以致丧失音质。SBR把频谱切割开来,低频单独编码保存主要成分,高频单独放大编码保存音质,在相同音质下降低了文件大小。
HEv2(又称为HEPS)它用容器的方法包含了HE-AAC v1和PS技术。PS指“Parametric Stereo”(参数立体声)。这个其实好理解,原来的立体声文件,文件大小是一个声道的两倍。但是两个声道的声音存在某种相似性,根据香农信息熵编码定理,相关性应该被去掉才能减小文件大小。所以PS技术存储了一个声道的全部信息,然后,花很少的字节用参数描述另一个声道和它不同的地方。
参考文档: https://zh.wikipedia.org/wiki/%E9%80%B2%E9%9A%8E%E9%9F%B3%E8%A8%8A%E7%B7%A8%E7%A2%BC
AAC各种规格的英文介绍:
AAC = MPEG2 AAC ~= MP3 + TNS + TP (It is not an upgrade of MP3 since it is not backward compatible but uses all MP3's features in a better way).
MPEG4 AAC = MPEG2 AAC + LTP + PNS
There are several profliles depending on the decoding/encoding complexity, required power, delay, bandwith characteristics, error resilience characteristics, etc... The most used profile in the PC arena is the AAC LC (Low Complexity) = MPEG4 AAC without LTP.
HE-AAC = SBR + AAC LC
Coding Technologies, developers of SBR, named this coding aacPlus&S482;, also known as AAC+, HE-AAC, AACP, AAC-LC+SBR, etc... SBR technology was prevously introduced in the MP3pro codec.
HE-AAC v2= PS + HE-AAC
Coding Technologies, developers of the MPEG Parametric Stereo, named this coding aacPlus&S482; v2 as a new revision of the previous release. It is also known as AAC++, EAAC+, Enhanced HE-AAC, EAACP, HE-AAC+PS, etc... Recently it was standarized by ISO as HE-AAC v2.
S-AAC...(Just guessing, not yet released but in Reference Model 0 stage)
Since MPEG is focusing in multichannel, the next standard will be something based in the Spatial Audio Coding tool standarized as MPEG Surround, that allows to do someting similar to PS but aimed to 5.1ch or 7.1ch content. This could be named as S-AAC, AAC Surround or AACS, Surround HE-AAC, [Put your favorite name here]. There isn't an official name for it yet.
Terms and acronyms:
AAC Advanced Audio Coding, developed by Dolby Laboratories.
TNS Temporal Noise Shaping is a tool designed to control the location, in time, of the quantization noise by transmission of filtering coefficients.
找到的中文文献:
1. TNS是用来消除由激发讯号所造成pre-echo现象的一个模组,它可以控制量化误差并且将误差塑形在遮避能力较大的激发讯号里,进而改进音乐品质。
2. TNS 是感官式音訊編碼(Perceptual Audio Coding) 中的一個新的觀念,目的在於使單一區塊在經過時間 -頻率轉換、量化及編碼之後,音訊在區塊內時間上 的噪音遮蔽效果仍然能夠維持。
TP Temporal Prediction is a tool designed to enhance compressibility of stationnary signals.
LTP Long Term Prediction is once again a prediction tool. This one requires less computation power but it is far more complex than the one used in MPEG-2 AAC, while providing comparable coding performance.
PNS Perceptual Noise Substitution, allows to replace coding of noise-like parts of the signal by some noise generated on the decoder side, so the decoding result is not deterministic among multiple decoding processes of the same encoded data.
SBR Spectral Band Replication is a tool that creates associated higher frequency content based on the lower frequencies and coding it as statistical information: level, distribution and ranges. Each of these parameters is encoded separately, taking account of their distinctive characteristics. It involves reconstruction of a noise-like frequency spectrum by employing a noise generator with some statistical information (level, distribution, ranges), so the decoding result is not deterministic among multiple decoding processes of the same encoded data. Both ideas are based on the principle that the human brain tends to consider high frequencies to be either harmonic phenomena associated with lower frequencies or noise, and is thus less sensitive to the exact content of high frequencies in audio signals.
PS Parametric Stereo, the stereo image information is separated from the mono signal being represented as a small amount of high quality parametric stereo information. The scheme relies on dissecting the incoming audio signal into three ‘objects’ that are a common constituent of all audio signals: transients, sinusoids and noise The stereo information is efficiently parameterized. Each of these objects is encoded separately, taking account of their distinctive characteristics. Like PNS and SBR the decoding result is not deterministic among multiple decoding processes of the same encoded data.
SAC Spatial Audio Coding exploits inter-channel differences in level, phase and coherence to capture the spatial image of a multi-channel audio signal relative to a transmitted downmix signal. It encodes each of these cues separately taking account of their distinctive characteristics such that the cues, and the transmitted signal, can be decoded to synthesize a high quality multi-channel representation allowing higher compression than separate channel coding.
参考文档:https://www.cnblogs.com/goodloop/archive/2008/10/10/1308032.html
samplingFrequencyIndex 和 samplingFrequency对应关系如下(ISO14496-3表1.18):

Channel Configuration 和 number of Channels的对应关系如下(ISO14496-3表1.19):

ffmpeg解析AudioSpecificConfig的代码在函数 ff_mpeg4audio_get_config_gb() 中,如下:
/* XXX: make sure to update the copies in the different encoders if you change
* this table */
const int avpriv_mpeg4audio_sample_rates[16] = {
96000, 88200, 64000, 48000, 44100, 32000,
24000, 22050, 16000, 12000, 11025, 8000, 7350
};
const uint8_t ff_mpeg4audio_channels[8] = {
0, 1, 2, 3, 4, 5, 6, 8
};
static inline int get_object_type(GetBitContext *gb)
{
int object_type = get_bits(gb, 5);
if (object_type == AOT_ESCAPE)
object_type = 32 + get_bits(gb, 6);
return object_type;
}
static inline int get_sample_rate(GetBitContext *gb, int *index)
{
*index = get_bits(gb, 4);
return *index == 0x0f ? get_bits(gb, 24) :
avpriv_mpeg4audio_sample_rates[*index];
}
int ff_mpeg4audio_get_config_gb(MPEG4AudioConfig *c, GetBitContext *gb,
int sync_extension, void *logctx)
{
int specific_config_bitindex, ret;
int start_bit_index = get_bits_count(gb);
c->object_type = get_object_type(gb);
c->sample_rate = get_sample_rate(gb, &c->sampling_index);
c->chan_config = get_bits(gb, 4);
if (c->chan_config < FF_ARRAY_ELEMS(ff_mpeg4audio_channels))
c->channels = ff_mpeg4audio_channels[c->chan_config];
else {
av_log(logctx, AV_LOG_ERROR, "Invalid chan_config %d\n", c->chan_config);
return AVERROR_INVALIDDATA;
}
c->sbr = -1;
c->ps = -1;
if (c->object_type == AOT_SBR || (c->object_type == AOT_PS &&
// check for W6132 Annex YYYY draft MP3onMP4
!(show_bits(gb, 3) & 0x03 && !(show_bits(gb, 9) & 0x3F)))) {
if (c->object_type == AOT_PS)
c->ps = 1;
c->ext_object_type = AOT_SBR;
c->sbr = 1;
c->ext_sample_rate = get_sample_rate(gb, &c->ext_sampling_index);
c->object_type = get_object_type(gb);
if (c->object_type == AOT_ER_BSAC)
c->ext_chan_config = get_bits(gb, 4);
} else {
c->ext_object_type = AOT_NULL;
c->ext_sample_rate = 0;
}
specific_config_bitindex = get_bits_count(gb);
if (c->object_type == AOT_ALS) { //36
skip_bits(gb, 5);
if (show_bits(gb, 24) != MKBETAG('\0','A','L','S'))
skip_bits(gb, 24);
specific_config_bitindex = get_bits_count(gb);
ret = parse_config_ALS(gb, c);
if (ret < 0)
return ret;
}
if (c->ext_object_type != AOT_SBR && sync_extension) {
while (get_bits_left(gb) > 15) {
if (show_bits(gb, 11) == 0x2b7) { // sync extension
get_bits(gb, 11);
c->ext_object_type = get_object_type(gb);
if (c->ext_object_type == AOT_SBR && (c->sbr = get_bits1(gb)) == 1) {
c->ext_sample_rate = get_sample_rate(gb, &c->ext_sampling_index);
if (c->ext_sample_rate == c->sample_rate)
c->sbr = -1;
}
if (get_bits_left(gb) > 11 && get_bits(gb, 11) == 0x548)
c->ps = get_bits1(gb);
break;
} else
get_bits1(gb); // skip 1 bit
}
}
//PS requires SBR
if (!c->sbr)
c->ps = 0;
//Limit implicit PS to the HE-AACv2 Profile
if ((c->ps == -1 && c->object_type != AOT_AAC_LC) || c->channels & ~0x01)
c->ps = 0;
return specific_config_bitindex - start_bit_index;
}我们解析AudioSpecificConfig的目的就是为了封装AAC的头 adif_header 和 adts_header.
AAC的音频文件格式
(这里照搬雷大的博客 https://blog.csdn.net/leixiaohua1020/article/details/11822537/)
AAC的音频文件格式有以下两种:
ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。
ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。这种格式可以用于广播电视。
简言之。ADIF只有一个文件头,ADTS每个包前面有一个文件头。所以在直播等领域用的最多的还是ADTS。
AAC的ADIF格式见下图:

AAC的ADTS的一般格式见下图:

图中表示出了ADTS一帧的简明结构,其两边的空白矩形表示一帧前后的数据。(error_check()即CRC校验,总计2个字节(16位))
adif_header(ISO14496-3表1.A.2)
(ADIF用的较少,所以简单介绍一下。)

其中每个字段什么意思,我在文档中并没有找到相关解释,以后若有使用,再搜寻相关资料补上。这里不做详述。
adts_header
adts_header由固定头、可变头两部分组成,即 adts_header = adts_fixed_header + adts_variable_header
adts_fixed_header如下:(ISO14496-3表1.A.6)

- syncword:帧同步标识一个帧的开始,固定为0xFFF
- ID:MPEG 标示符。0表示MPEG-4,1表示MPEG-2
- layer:固定为'00'
- protection_absent:标识是否进行误码校验。0表示有CRC校验,1表示没有CRC校验,CRC校验总共2个字节(16bit)
- profile:标识使用哪个级别的AAC。1: AAC Main 2:AAC LC (Low Complexity) 3:AAC SSR (Scalable Sample Rate) 4:AAC LTP (Long Term Prediction)
- sampling_frequency_index:标识使用的采样率的下标
- private_bit:私有位,编码时设置为0,解码时忽略
- channel_configuration:标识声道数
- original_copy:编码时设置为0,解码时忽略
- home:编码时设置为0,解码时忽略
文档中英文的注释:
- syncword: The bit string ‘1111 1111 1111’. (ISO13818-7)
- ID: MPEG identifier, set to ‘1’ if the audio data in the ADTS stream is MPEG-2 AAC(see ISO/IEC 13818-7) and set to ‘0’ if the audio data is MPEG-4. (ISO14496-3)
- layer: Indicates which layer is used. Set to ‘00’. (ISO13818-7)
- protection_absent: Indicates whether error_check() data is present or not. (ISO13818-7)
- profile_ObjectType: The interpretation of this data element depends on the value of the ID bit. If ID is equal to ‘1’ this field holds the same information as the profile field in the ADTS stream defined in ISO/IEC 13818-7. If ID is equal to ‘0’ this element denotes the MPEG-4 Audio Object Type (profile_ObjectType+1) according to the table defined in subclause 1.5.2.1. (ISO14496-3)
- sampling_frequency_index: Indicates the sampling frequency used according to the table defined in
subclause 1.6.3.4. The escape value is not permitted. (ISO14496-3) - private_bit: bit for private use. This bit will not be used in the future by ISO. (ISO11172-3)
- channel_configuration: (ISO14496-3)
Indicates the channel configuration used. In the case of (channel_configuration > 0), the channel configuration is given in Table 1.19. In the case of (channel_configuration == 0), the channel configuration is not specified in the header, but as follows:
MPEG-2/4 ADTS: A single program_config_element() following as first syntactic element in the first raw_data_block() after the header specifies the channel configuration. Note that the program_config_element() might not be present in each frame. An MPEG-4 ADTS decoder should not generate any output until it received a program_config_element(), while an MPEG-2 ADTS decoder may assume an implicit channel configuration.
MPEG-2 ADTS: Beside the usage of a program_config_element(), the channel configuration may be assumed to be given implicitly (see ISO/IEC13818-7) or may be known in the application.
-
original_copy: see ISO/IEC 11172-3, definition of data element copyright. (ISO13818-7)
-
(copyright): if this bit equals '0' there is no copyright on the coded bitstream, '1' means copyright protected. (ISO11172-3)
-
home: see ISO/IEC 11172-3, definition of data element original/copy. (ISO13818-7)
-
(original/copy): this bit equals '0' if the bitstream is a copy, '1' if it is an original. (ISO11172-3)
adts_variable_header如下:(ISO14496-3表1.A.7)

- copyrighted_id_bit:编码时设置为0,解码时忽略
- copyrighted_id_start:编码时设置为0,解码时忽略
- aac_frame_length:ADTS帧长度包括ADTS长度和AAC声音数据长度的和。即 aac_frame_length = (protection_absent == 0 ? 9 : 7) + audio_data_length (当protection_absent == 0 时会多出2个字节的CRC校验,即error_check())
- adts_buffer_fullness:固定为0x7FF。表示是码率可变的码流
- number_of_raw_data_blocks_in_frame:表示当前帧有number_of_raw_data_blocks_in_frame + 1 个原始帧(一个AAC原始帧包含一段时间内1024个采样及相关数据)。
文档中英文的注释:
- copyright_identification_bit: One bit of the 72-bit copyright identification field (see copyright_id above). The bits of this field are transmitted frame by frame; the first bit is indicated by the copyright_identification_start bit set to '1'. The field consists of an 8-bit copyright_identifier, followed by a 64-bit copyright_number. The copyright identifier is given by a Registration Authority as designated by SC29. The copyright_number is a value which identifies uniquely the copyrighted material. See ISO/IEC 13818-3, subclause 2.5.2.13 (Table 9). (ISO13818-7)
- copyright_identification_start: One bit to indicate that the copyright_identification_bit in this audio frame is the first bit of the 72-bit copyright identification. If no copyright identification is transmitted, this bit should be kept '0'.'0' no start of copyright identification in this audio frame '1' start of copyright identification in this audio frame See ISO/IEC 13818-3, subclause 2.5.2.13 (Table 9). (ISO13818-7)
- aac_frame_length: Length of the frame including headers and error_check in bytes. (ISO13818-7)
- adts_buffer_fullness:state of the bit reservoir in the course of encoding the ADTS frame, up to and including the first raw_data_block() and the optionally following adts_raw_data_block_error_check(). It is transmitted as the number of available bits in the bit reservoir divided by NCC divided by 32 and truncated to an integer value (Table 9). A value of hexadecimal 7FF signals that the bitstream is a variable rate bitstream. In this case, buffer fullness is not applicable. (ISO13818-7)
- number_of_raw_data_blocks_in_frame:Number of raw_data_block()’s that are multiplexed in the adts_frame() is equal to number_of_raw_data_blocks_in_frame + 1. The minimum value is 0 indicating 1 raw_data_block() (Table 9). (ISO13818-7)
维基百科也有对 adts_header 每个字段的解释,如下:
( https://wiki.multimedia.cx/index.php?title=ADTS )
Audio Data Transport Stream (ADTS) is a format, used by MPEG TS or Shoutcast to stream audio, usually AAC.
Structure
Header consists of 7 or 9 bytes (without or with CRC).
| Letter | Length (bits) | Description |
|---|---|---|
| A | 12 | syncword 0xFFF, all bits must be 1 |
| B | 1 | MPEG Version: 0 for MPEG-4, 1 for MPEG-2 |
| C | 2 | Layer: always 0 |
| D | 1 | protection absent, Warning, set to 1 if there is no CRC and 0 if there is CRC |
| E | 2 | profile, the MPEG-4 Audio Object Type minus 1 |
| F | 4 | MPEG-4 Sampling Frequency Index (15 is forbidden) |
| G | 1 | private bit, guaranteed never to be used by MPEG, set to 0 when encoding, ignore when decoding |
| H | 3 | MPEG-4 Channel Configuration (in the case of 0, the channel configuration is sent via an inband PCE) |
| I | 1 | originality, set to 0 when encoding, ignore when decoding |
| J | 1 | home, set to 0 when encoding, ignore when decoding |
| K | 1 | copyrighted id bit, the next bit of a centrally registered copyright identifier, set to 0 when encoding, ignore when decoding |
| L | 1 | copyright id start, signals that this frame's copyright id bit is the first bit of the copyright id, set to 0 when encoding, ignore when decoding |
| M | 13 | frame length, this value must include 7 or 9 bytes of header length: FrameLength = (ProtectionAbsent == 1 ? 7 : 9) + size(AACFrame) |
| O | 11 | Buffer fullness |
| P | 2 | Number of AAC frames (RDBs) in ADTS frame minus 1, for maximum compatibility always use 1 AAC frame per ADTS frame |
| Q | 16 | CRC if protection absent is 0 |
Usage in MPEG-TS
ADTS packet must be a content of PES packet. Pack AAC data inside ADTS frame, than pack inside PES packet, then mux by TS packetizer.
Usage in Shoutcast
ADTS frames goes one by one in TCP stream. Look for syncword, parse header and look for next syncword after.
最后我们看ffmpeg对adts_header的封装代码,如下:
可以看出,除了objecttype, sample_rate_index, channel_conf, aac_frame_length其他都是固定写死的。
static int adts_write_frame_header(ADTSContext *ctx,
uint8_t *buf, int size, int pce_size)
{
PutBitContext pb;
//#define ADTS_MAX_FRAME_BYTES ((1 << 13) - 1)
unsigned full_frame_size = (unsigned)ADTS_HEADER_SIZE + size + pce_size;
if (full_frame_size > ADTS_MAX_FRAME_BYTES) {
av_log(NULL, AV_LOG_ERROR, "ADTS frame size too large: %u (max %d)\n",
full_frame_size, ADTS_MAX_FRAME_BYTES);
return AVERROR_INVALIDDATA;
}
init_put_bits(&pb, buf, ADTS_HEADER_SIZE); //#define ADTS_HEADER_SIZE 7
/* adts_fixed_header */
put_bits(&pb, 12, 0xfff); /* syncword */
put_bits(&pb, 1, 0); /* ID */
put_bits(&pb, 2, 0); /* layer */
put_bits(&pb, 1, 1); /* protection_absent */
put_bits(&pb, 2, ctx->objecttype); /* profile_objecttype */
put_bits(&pb, 4, ctx->sample_rate_index);
put_bits(&pb, 1, 0); /* private_bit */
put_bits(&pb, 3, ctx->channel_conf); /* channel_configuration */
put_bits(&pb, 1, 0); /* original_copy */
put_bits(&pb, 1, 0); /* home */
/* adts_variable_header */
put_bits(&pb, 1, 0); /* copyright_identification_bit */
put_bits(&pb, 1, 0); /* copyright_identification_start */
put_bits(&pb, 13, full_frame_size); /* aac_frame_length */
put_bits(&pb, 11, 0x7ff); /* adts_buffer_fullness */
put_bits(&pb, 2, 0); /* number_of_raw_data_blocks_in_frame */
flush_put_bits(&pb);
return 0;
}总结:
- 建立rtmp连接,循环拉流,当type == SRS_RTMP_TYPE_AUDIO时,读取到的是Audio Tag Data (由AudioTagHeader + AudioTagData组成)。
- 解析AudioTag Header, 当SoundFormat == 10时,音频数据为AAC编码的音频。AAC音频的AudioTag Header会比其他编码格式的音频的Header多出一个字节表示AACPacketType。
- 当AACPacketType == 0时表示紧接着的数据内容是AAC sequence header; 当AAC sequence header == 1表示紧接着的数据内容是AAC raw。
- AAC sequence header就是AudioSpecificConfig,我们对其进行解析,解析出audioObjectType, samplingFrequencyIndex, channelConfiguration。
- 通过audioObjectType, samplingFrequencyIndex, channelConfiguration,封装adts_header(由adts_fixed_header 和 adts_variable_header两部分组成)。
- 当收到的数据为AAC raw时,在AAC raw之前加上adts_header,再一起保存在文件中(二进制保存)。
- 最后得到AAC文件,可以直接通过播放器进行播放了。
代码部分:
基于windows vs2017, 库srs_librtmp3.0(使用vs2017编译)的代码如下(使用其他vs版本请重新相应的vs编译库文件):
(ffmpeg.hpp: 提取ffmpeg的部分源码,用于位的解析,和组装adts_header。 如果有自己定义的位解析接口,则不需要该头文件,并在main.cpp中解析、组装adts_header中稍作修改即可)
代码中已经做了很多注释,不再累述.
main.cpp
#include <cstring>
#include <cstdint>
#include <string>
#include <cstdio>
#include "srs_librtmp.hpp"
#include "ffmpeg.hpp"
typedef struct AudioSpecificConfig_st{
bool isValid = false;
unsigned int objectType = 0;
unsigned char samplingFreqIndex = 0;
unsigned char channelCfg = 0;
} AudioSpecificConfig;
AudioSpecificConfig asConfig;
uint32_t getAudioObjectType(GetBitContext *gb) {
uint32_t objectType = get_bits(gb, 5);
if(objectType == 31) {
uint32_t audioObjectTypeExt = get_bits(gb, 6);
objectType = 32 + audioObjectTypeExt;
}
return objectType;
}
// AAC sequence header就是AudioSpecificConfig,我们对其进行解析,
// 解析出audioObjectType, samplingFrequencyIndex, channelConfiguration。
int parseAudioSpecificConfig(const uint8_t *data, int size) {
if (!data || !size) {
return -1;
}
GetBitContext gb;
int ret = init_get_bits(&gb, data, size*8);
if (ret < 0) {
return ret;
}
asConfig.objectType = getAudioObjectType(&gb);
asConfig.samplingFreqIndex = get_bits(&gb, 4);
if (asConfig.samplingFreqIndex == 0xf) {
skip_bits(&gb, 24); //samplingFrequency
}
asConfig.channelCfg = get_bits(&gb, 4);
if (asConfig.objectType == 5 || asConfig.objectType == 29) {
unsigned char exSamplingFreqIndex = get_bits(&gb, 4);
if (exSamplingFreqIndex == 0xf) {
skip_bits(&gb, 24);
}
asConfig.objectType = getAudioObjectType(&gb);
}
if (get_bits_left(&gb) >= 0) {
asConfig.isValid = true;
return 0;
} else {
asConfig.isValid = false;
return -1;
}
}
// 通过audioObjectType, samplingFrequencyIndex, channelConfiguration,
// 封装adts_header(由adts_fixed_header 和 adts_variable_header两部分组成)。
std::string buildAdtsHeader(int dataSize, bool CRC = false) {
if(!asConfig.isValid) {
return "";
}
uint8_t aacHead[7] = {0};
PutBitContext pb;
init_put_bits(&pb, aacHead, sizeof(aacHead));
/* adts_fixed_header */
put_bits(&pb, 12, 0xfff); /* syncword */
put_bits(&pb, 1, 0); /* ID */
put_bits(&pb, 2, 0); /* layer */
put_bits(&pb, 1, 1); /* protection_absent */
put_bits(&pb, 2, asConfig.objectType); /* profile_objecttype */
put_bits(&pb, 4, asConfig.samplingFreqIndex);
put_bits(&pb, 1, 0); /* private_bit */
put_bits(&pb, 3, asConfig.channelCfg); /* channel_configuration */
put_bits(&pb, 1, 0); /* original_copy */
put_bits(&pb, 1, 0); /* home */
/* adts_variable_header */
put_bits(&pb, 1, 0); /* copyright_identification_bit */
put_bits(&pb, 1, 0); /* copyright_identification_start */
int full_frame_size = CRC ? 9 + dataSize : 7 + dataSize;
put_bits(&pb, 13, full_frame_size); /* aac_frame_length */
put_bits(&pb, 11, 0x7ff); /* adts_buffer_fullness */
put_bits(&pb, 2, 0); /* number_of_raw_data_blocks_in_frame */
flush_put_bits(&pb);
return std::string((char *)aacHead, 7);
}
int connectRtmpServer(srs_rtmp_t &_rtmp, const std::string &rtmpUrl) {
_rtmp = srs_rtmp_create(rtmpUrl.c_str());
srs_rtmp_set_timeout(_rtmp, 200, 200);
if (srs_rtmp_handshake(_rtmp) != 0) {
fprintf(stderr, "srs_rtmp_handshake() failed.\r\n");
return -1;
}
if (srs_rtmp_connect_app(_rtmp) != 0) {
fprintf(stderr, "srs_rtmp_connect_app() failed.\r\n");
return -1;
}
if (srs_rtmp_play_stream(_rtmp) != 0) {
fprintf(stderr, "srs_rtmp_play_stream() failed.\r\n");
return -1;
}
return 0;
}
int parseAudioTagData(char *data, int size, std::string &outAacData) {
outAacData.clear();
char *ptr = data;
char soundFormat = (*ptr & 0xf0) >> 4; //4
char soundRate = (*ptr & 0x0c) >> 2; //2 useless for aac
char soundSize = (*ptr & 0x02) >> 1; //1 useless for aac
char soundType = (*ptr & 0x01); //1 useless for aac
if(soundFormat != 10) { //当SoundFormat == 10时,音频数据为AAC编码的音频
fprintf(stderr, "soundFormat Error(%#02x), Only support AAC(soundFormat = 10)\n", soundFormat);
return -1;
}
ptr++;
char AACPacketType = *ptr++; //AAC音频的AudioTag Header会比其他编码格式的音频的Header多出一个字节表示AACPacketType。
int restSize = size - (int)(ptr - data);
if(AACPacketType == 0) { //当AACPacketType == 0时表示紧接着的数据内容是AAC sequence header
if(parseAudioSpecificConfig((const uint8_t *)ptr, restSize) < 0 || !asConfig.isValid) {
fprintf(stderr, "parseAudioSpecificConfig Error\n");
return -1;
}
} else if (AACPacketType == 1) { //当AAC sequence header == 1表示紧接着的数据内容是AAC raw
std::string adtsHead = buildAdtsHeader(restSize);
if(adtsHead.empty()) {
return -1;
}
//当收到的数据为AAC raw时,在AAC raw之前加上adts_header
std::string aacStr = std::move(adtsHead);
aacStr.append(ptr, restSize);
outAacData.swap(aacStr);
} else {
fprintf(stderr, "AACPacketType Error(%#02x)\n", AACPacketType);
return -1;
}
return 0;
}
int main() {
const std::string rtmpUrl = "rtmp://127.0.0.1:1935/live/aaa";
srs_rtmp_t _rtmp = nullptr;
if (connectRtmpServer(_rtmp, rtmpUrl) && _rtmp) {
srs_rtmp_destroy(_rtmp);
_rtmp = nullptr;
return 0;
}
FILE * fp = fopen("D:\\test.aac", "wb");
if (!fp) {
perror("fopen:");
return -1;
}
uint32_t timestamp;
char type, *data;
int size, ret;
std::string aacData;
while(true) {
data = nullptr;
size = 0;
if (srs_rtmp_read_packet(_rtmp, &type, ×tamp, &data, &size)) {
continue;
}
if(type == SRS_RTMP_TYPE_VIDEO) {
//todo video data
continue;
} else if (type == SRS_RTMP_TYPE_AUDIO) {
//当type == SRS_RTMP_TYPE_AUDIO时,读取到的是Audio Tag Data (由AudioTagHeader + AudioTagData组成)
ret = parseAudioTagData(data, size, aacData);
if (ret < 0 || aacData.empty()) {
continue;
}
fwrite(aacData.data(), 1, aacData.size(), fp);
} else {
continue;
}
}
fclose(fp);
}需要的头文件和库文件因为较大这里不再贴出,已经打包上传到CSDN。
CSDN下载地址:https://download.csdn.net/download/qq_41824928/12732651















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









