







一、概念
架构:
- Client/Server
- Ensemble(集群,ZK服务器组),最小节点数为3
- ZK Leadera
- ZK Follower
ZooKeeper数据模型
- znode:用于存储数据,分为持久的(default)、临时的、顺序的
- stat(metadata)
Session:
- Client连接到Server的时候分配一个SessionID
- Client发送心跳保持Session
- Session结束时基于该Session创建的znode也会删除
Watches:
- 用于Client 监视 znode,主要用于接收ZooKeeper集合中的znone更改通知
二、部署
2.1.单节点部署
Docker镜像:https://github.com/31z4/zookeeper-docker/tree/master/3.8.0
启动命令:
# 主要是config、data和datalog三个要持久化
docker run -d --name=zookeeper -v /opt/zookeeper/data/:/data/ -v /opt/zookeeper/datalog/:/datalog/ -v /opt/zookeeper/conf/:/conf/ -p 2181:2181 zookeeper:3.8.0
默认的配置(docker-entrypoint.sh写入)
# cat /opt/zookeeper/conf/zoo.cfg
# 存放内存数据结构的snapshot
dataDir=/data
# wal日志存放目录
dataLogDir=/datalog
# zk 使用的基本时间单位,以毫秒为单位。用于做心跳时间的间隔,最小会话超时将是 tickTime 的两倍。
tickTime=2000
# 集群初始化的时候,follower连接leader允许的心跳数(tickTime)
initLimit=5
# flower和leader之间的心跳过期时间
syncLimit=2
# 自动删除 客户端与服务端交互的时候产生的日志snapRetainCount以快照为限制,purgeInterval以时间为限制
# 自动删除的话,可能会影响性能?
autopurge.snapRetainCount=3
autopurge.purgeInterval=0
# 一个客户端的连接数限制
maxClientCnxns=60
standaloneEnabled=true
admin.enableServer=true
# 2888: peer之间通信的端口
# 3888: 选举新的leader使用的端口
# 2818:客户端连接的端口
server.1=localhost:2888:3888;2181
启动后,会在data目录下生成myid文件(zk节点的id)和数据文件(version-2/snapshot.0)
使用Cli连接ZK
docker exec -it zookeeper /apache-zookeeper-3.8.0-bin/bin/zkCli.sh -server 127.0.0.1:2181
Connecting to localhost:2181
...
# 一些基本操作
ls /
create /zk_test my_data # 创建znode, -s顺序znode, -e临时znode
get /zk_test
set /zk_test junk
stat /zk_test # 查看节点状态
delete /zk_test
使用go sdk实现简单的CUR + Watch
package main
import (
"fmt"
"github.com/go-zookeeper/zk"
"time"
)
// https://pkg.go.dev/github.com/go-zookeeper/zk#Conn.Create
func create(c *zk.Conn, path string, data []byte){
// flags
// 0:永久
// zk.FlagEphemeral
// zk.FlagSequence
// 3:Ephemeral和Sequence
var flags int32 = 0
path, err := c.Create(path, data, flags, zk.WorldACL(zk.PermAll))
if err != nil {
fmt.Println("创建失败", err)
return
}
fmt.Println("创建成功", path)
}
func get(c *zk.Conn, path string){
data, state, err := c.Get(path)
if err != nil {
fmt.Println("获取失败")
return
}
fmt.Println("data", string(data))
fmt.Println("state", state)
}
func update(c *zk.Conn, path string, data []byte){
_, sate, _ := c.Get(path)
_, err := c.Set(path, data, sate.Version)
if err != nil {
fmt.Println("更新失败", err)
return
}
fmt.Println("更新成功")
}
func main() {
conn, _, err := zk.Connect([]string{"192.168.56.4"}, time.Second)
if err != nil {
panic(err)
}
defer conn.Close()
path := "/test-path"
data := []byte("test-data")
create(conn, path, data)
get(conn, path)
newData := []byte("new-data")
update(conn, path, newData)
get(conn, path)
exists, state, eventChannel, err := conn.ExistsW("/test-path")
if err != nil {
panic(err)
}
// 如果监听的path有修改,就会收到通知(只会触发一次)
// 有空的时候实现一下循环监听
go func() {
e := <-eventChannel
fmt.Println("========================")
fmt.Println("path:", e.Path)
fmt.Println("type:", e.Type.String())
fmt.Println("state:", e.State.String())
fmt.Println("========================")
}()
fmt.Println("exists", exists)
fmt.Println("state", state)
time.Sleep(100 * time.Second)
}
2.2.Kubernetes部署ZK集群
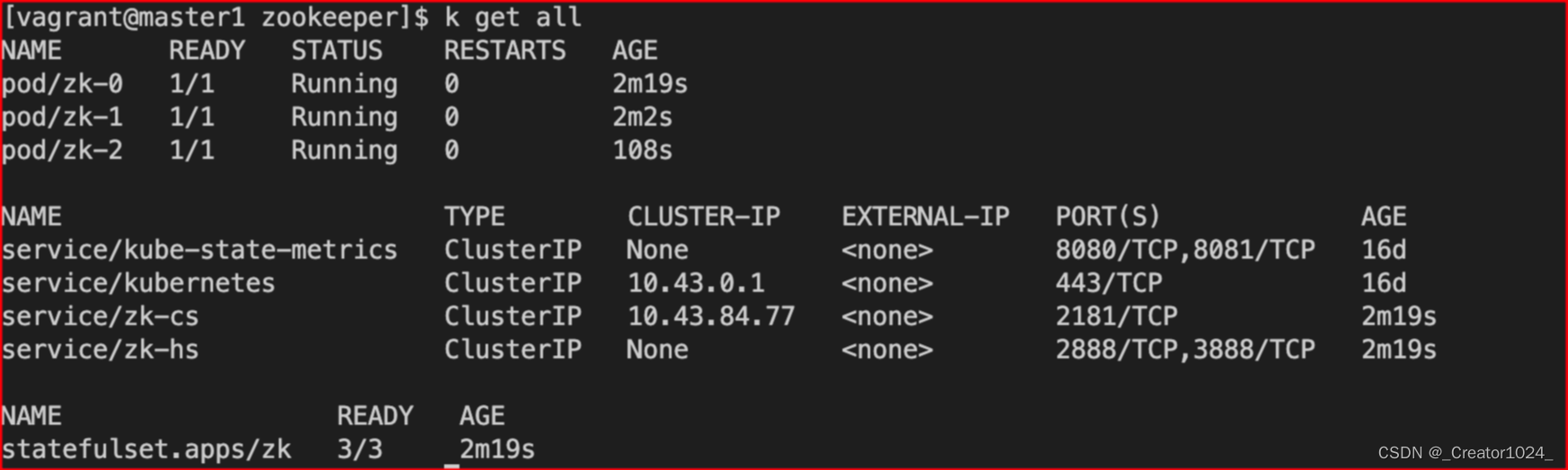
部署zk集群可以使用statefulset,也可以使用zk operator
statefulset实现比较简单,能满足需求的情况下,可以不用引入zk operator
当前用statefulset实现,使用的镜像启动脚本:https://github.com/kow3ns/kubernetes-zookeeper/blob/master/docker/scripts/start-zookeeper
这个启动脚本最重要的通过hostname获取每个zk节点的myid,让statefulset可以支持zk集群。 然后就是把传入的参数转化成配置文件。镜像用的是ubuntu14,可以替换成我们用的统一基础镜像,后续的升级版本或者新增的配置可以修改Dockerfile和启动脚本
zookeeper@zk-0:/var/lib$ cat /opt/zookeeper/conf/zoo.cfg
#This file was autogenerated DO NOT EDIT
clientPort=2181
dataDir=/var/lib/zookeeper/data
dataLogDir=/var/lib/zookeeper/data/log
tickTime=2000
initLimit=10
syncLimit=5
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
autopurge.snapRetainCount=3
autopurge.purgeInteval=12
server.1=zk-0.zk-hs.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-hs.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-hs.default.svc.cluster.local:2888:3888
k8s部署ZK集群实现高可用主要的点:
- 3副本Statefulset(3节点以上,奇数副本数)
- 挂载Volume,主要是给data和datalog使用
- 通过PodAntiAffinity让不同的Pod运行在不同的node之上,最好是不同AZ上的节点
- 配置PDB,至少要保证半数以上的节点存活,比如3节点就要保证2个节点存活
- 创建一个Headless-Service,用于zk peer之间互访
- 创建一个ClusterIP类型的Service,用于client访问zk集群
- 对于各个配置项的优化,目前暂不研究
# 用于zk集群peer之间通信的Headless Service,让zk peer通过dns的方式发现对方
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
# 用于客户端访问zk集群的ClusterIP Service
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
# PDB,主动驱逐场景下保证最多只有1个zk节点不可用
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zk
spec:
# affinity:
# podAntiAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# - labelSelector:
# matchExpressions:
# - key: "app"
# operator: In
# values:
# - zk
# topologyKey: "kubernetes.io/hostname"
containers:
- name: zk
imagePullPolicy: IfNotPresent
image: "guglecontainers/kubernetes-zookeeper:1.0-3.4.10"
resources:
limits:
memory: "512M"
cpu: 0.5
# requests:
# memory: "1Gi"
# cpu: "0.5"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
securityContext:
runAsUser: 1000
fsGroup: 1000
volumes:
- name: "datadir"
emptyDir: {}
# 挂载Volume
# volumeClaimTemplates:
# - metadata:
# name: datadir
# spec:
# accessModes: [ "ReadWriteOnce" ]
# resources:
# requests:
# storage: 10Gi















 9729
9729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









