







R-FCN: Object Detection via Region-based Fully Convolutional Networks论文阅读笔记
作者做此笔记仅为学习,如有侵权请联系作者删除博文,谢谢!
提出position-sensitive score maps(位置敏感分数图),以解决图像分类中的平移不变性与目标检测中的平移敏感性之间的困境。
为了将平移敏感性引入全卷积网络,作者在全卷积网络的输出位置添加一系列特定的卷积层用于生成position-sensitive的score map,每个score map保存目标的空间位置信息。然后再添加ROI Pooling层,该层后面不再跟卷积层或全连接层。这样整个网络不仅可以end-to-end训练,而且所有层的计算都是在整个图像上共享的。

图1中 k的平方 代表有k的平方个bin(也就是有多少个不同颜色的长方体),每个bin的通道是C+1(C是数据集的类别数),

通过区域提议网络(RPN)提取候选区域,其本身就是一个全卷积架构。之后,在RPN和R-FCN之间的共享特征。有了RoIs之后,R-FCN将RoIs分为目标类别或者背景。在R-FCN中所有可学习的参数在卷积层并在整个图像上计算。最后一个卷积层为每个类别产生一组KxK个position-sensitive score maps,因此具有k x k x(C+ 1)个通道的输出层,其中包含C个对象类别(背景为+1)。k x k个score maps对应于描述相对位置的k x k个空间网格。例如k=3时,这9个score maps对一个对象类别的 {top-left, top-center, top-right, …, bottom-right}进行编码。(利用RPN提取的RoI,其位置信息有(x,y,w,h),然后被划分为k x k个bins,每个bin对应score map上的一个区域。然后对这个区域进行pooling操作—也就是下面的这个分支(图2中灰色部分))
R-FCN以位置敏感( position-sensitive)的RoI池化层结束。该层聚合最后一个卷积层的输出,并为每个RoI生成分数。position-sensitive 的roi层进行选择性池化,并且k×k个组块中的每一个仅聚合k×k个score maps中一个score map的响应。通过端到端的训练,这个RoI层可以管理最后一个卷积层来学习专门的位置敏感分数图。

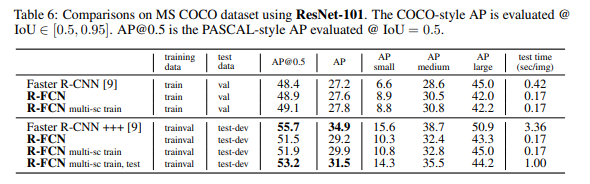
主干网络:ResNet-101中的最后一个卷积块是2048维,我们附加一个随机初始化的1024维的1×1卷积层来降维(准确地说,这增加了表1中的深度)。然后,我们应用k x k(C+1)通道卷积层来生成分数图。
Position-sensitive score maps & Position-sensitive RoI pooling.为了将位置信息显示的编码到每个RoI中,用规则网格将每个RoI矩形分成k×k个bin。对于大小为w×h的RoI矩形,组块的大小为≈w/k×h/k。在我们的方法中,最后的卷积层的目的是为每个类别产生k x k个score maps。在第(i,j)个组块(bin)(0≤i,j≤k−1)中,我们定义了一个位置敏感的RoI池化操作,它只在第(i,j)个score map中进行池化:

然后将k x k 个位置敏感的分数在RoI上vote(we simply vote by averaging the scores),为每一个RoI产生一个(C + 1)维的向量。然后,计算跨类别的softmax响应。用于评估训练时的交叉熵损失以及在推断期间的RoI的排名。
以类似的方式进一步解决边界框回归。除了上面的k2(C+1)维卷积层,在边界框回归上附加了一个4k x k维平行卷积层。在这组4k x k维映射上执行位置敏感的RoI池化,为每个RoI生成一个4k x k维的向量。然后通过平均voting聚合到4维向量中。这个4维向量将边界框参数化为t=(t_x,t_y,t_w,t_h),参见[6]中的参数化。为简单起见,执行类别不可知的边界框回归,但类别特定的对应部分(即,具有4k2C维输出层)是适用的。
总的网络:首先输入图像经过一个全卷积网络(比如ResNet),然后一方面在最后一个卷积层后面添加特殊的卷积层生成position-sensitive的score map,另一方面全卷积网络的某个卷积层(可能是最后一个卷积层)输出作为RPN网络的输入,RPN网络最后生成ROI。最后的POI Pooling层将前面的socre map和ROI作为输入,输出类别信息。另外回归部分和分类部分是并列的。

















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









