










1. 数据载入与总览
1.1 数据加载
#绘图工具
import matplotlib.pyplot as plt
%matplotlib inline
#数据处理工具
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#数据路径自己指定,本案例数据路径就在当前文件夹下面子文件夹usa_elect中
contb1 = pd.read_csv('./usa_elect/contb_01.csv')
contb2 = pd.read_csv('./usa_elect/contb_02.csv')
contb3 = pd.read_csv('usa_elect/contb_03.csv')
1.2 数据集成
#axis = 0 表示在行方向进行集成
contb = pd.concat([contb1,contb2,contb3],axis = 0)
1.3 数据预览
#查看前5行数据
contb.head()
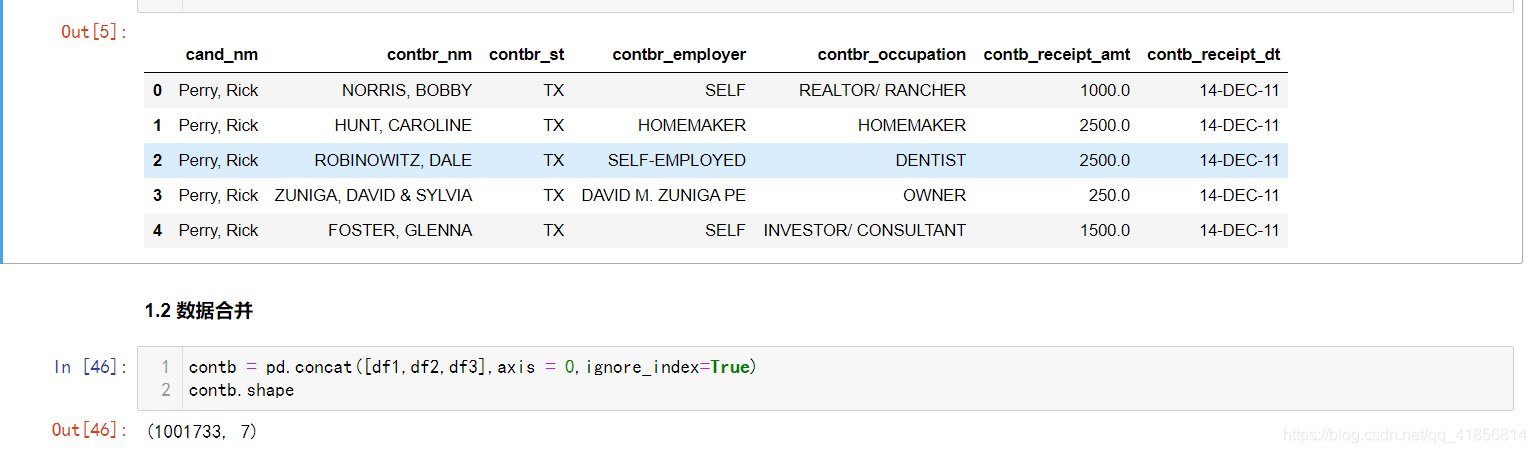
字段解释:
cand_nm :候选人姓名
contbr_nm : 捐赠人姓名
contbr_st :捐赠人所在州
contbr_employer : 捐赠人所在公司
contbr_occupation : 捐赠人职业
contb_receipt_amt :捐赠数额(美元)
contb_receipt_dt : 捐款的日期
#查看数据形状
contb.shape
输出:(1001733, 7)
说明数据共计1001733行数据,共7列属性
#该方法查看数据总览
#查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型等
contb.info()
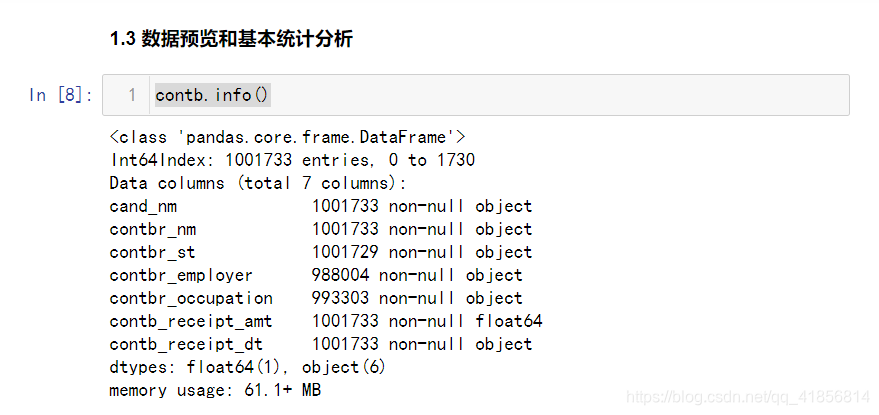
通过info我们可以知道contbr_employer和contbr_occupation与contbr_st存在空数据
#用统计学指标快速描述数值型属性的概要
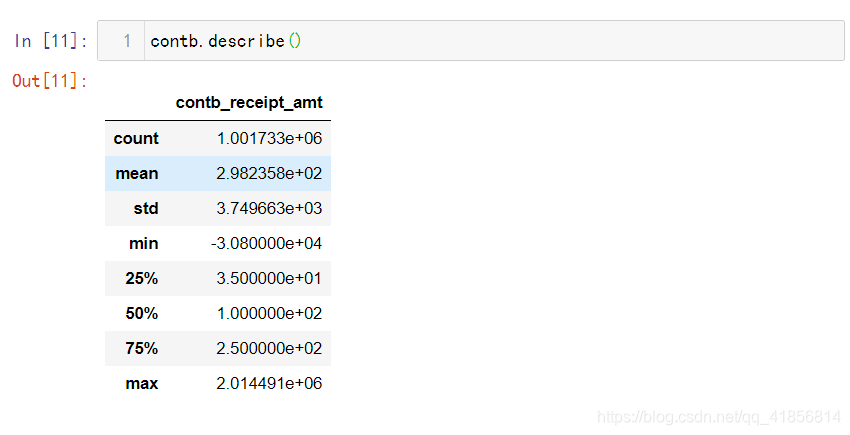
contb.describe()
2. 数据预处理
2.1 空值处理
#属性contbr_employer存在空数据,有可能因为忘记填写或者保密等等原因
#使用fillna方法填充固定值:NOT PROVIDE
contb['contbr_employer'].fillna('NOT PROVIDE',inplace = True)
#对属性contbr_occupation职业进行数据填充
contb['contbr_occupation'].fillna('NOT PROVIDE',inplace = True)
#对属性contbr_st进行数据填充
contb['contbr_st'].fillna('NOT PROVIDE',inplace = True)
此时我们的数据contb已经不存在空数据了
2.2 数据变换
2.2.1 字典映射进行转换:党派分析
#通过搜索引擎等途径,获取到每个总统候选人的所属党派,建立字典parties,候选人名字作为键,所属党派作为对应的值
parties = {'Bachmann, Michelle': 'Republican',
'Cain, Herman': 'Republican',
'Gingrich, Newt': 'Republican',
'Huntsman, Jon': 'Republican',
'Johnson, Gary Earl': 'Republican',
'McCotter, Thaddeus G': 'Republican',
'Obama, Barack': 'Democrat',
'Paul, Ron': 'Republican',
'Pawlenty, Timothy': 'Republican',
'Perry, Rick': 'Republican',
"Roemer, Charles E. 'Buddy' III": 'Republican',
'Romney, Mitt': 'Republican',
'Santorum, Rick': 'Republican'}
%%time
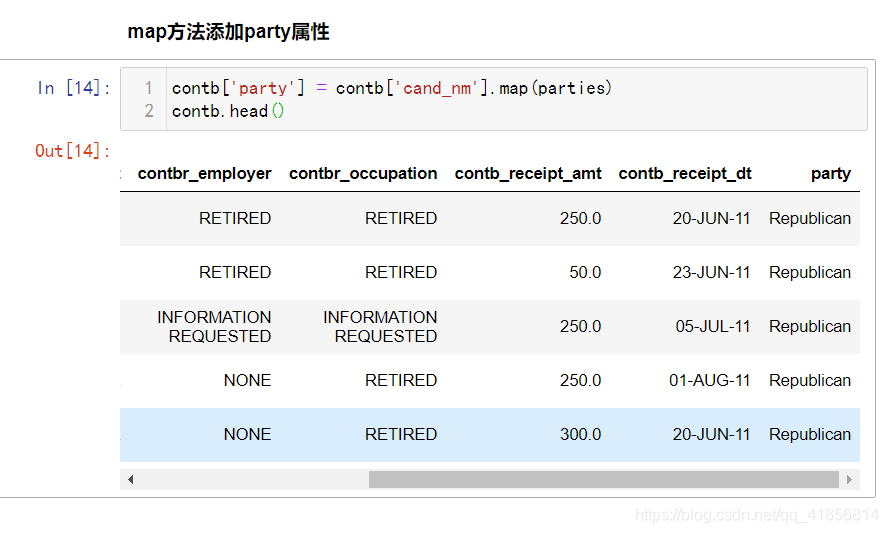
# map中可以传递字典,100万数据,增加一列耗时大约125ms
contb['party'] = contb['cand_nm'].map(parties)
#查看数据,最后一列增加了party
contb.head()
2.2.2 按照职业或公司分组聚合对赞助总金额进行排序
按照职业进行分组聚合:
grouped_occupation = contb.groupby(['contbr_occupation'])['contb_receipt_amt'].sum()
grouped_occupation.sort_values(ascending=False)[:50]

按照职位进行汇总,计算赞助总金额,展示前50项,发现不少职业是相同的,只不过是表达不一样而已,如C.E.O.与CEO,都是一个职业
按照公司进行分组聚合:
# 按照公司进行统计,汇总
group_employer = contb.groupby(['contbr_employer'])['contb_receipt_amt'].sum()
group_employer.sort_values(ascending = False)[:50]
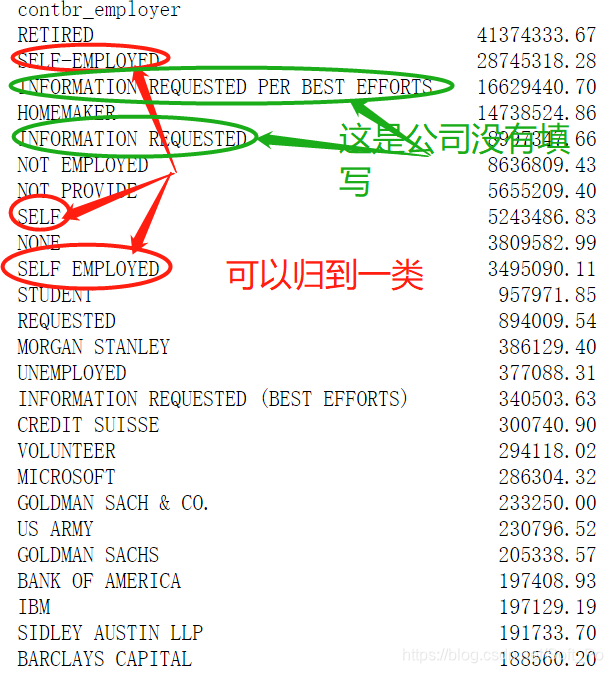
2.2.3 利用函数进行数据转换:职业与雇主信息分析
#整理一部分相同的职业,如果全部整理需要花费很长时间
occupation = {'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDE',
'INFORMATION REQUESTED':'NOT PROVIDE',
'C.E.O.':'CEO',
'LAWYER':'ATTORNEY',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED ':'SELF-EMPLOYED'}
f = lambda x : occupation.get(x,x)
#进行map转换
contb['contbr_occupation'] = contb['contbr_occupation'].map(f)
#整理一部分相同的公司,如果全部整理需要花费很长时间
#示例
employer = {'INFORMATION REQUESTED PER BEST EFFORTS':'NOT PROVIDE',
'INFORMATION REQUESTED':'NOT PROVIDE',
'SELF':'SELF-EMPLOYED',
'SELF EMPLOYED':'SELF-EMPLOYED'}
f = lambda x : employer.get(x,x)
contb['contbr_employer'] = contb['contbr_employer'].map(f)
2.3 数据删选
2.3.1 献金金额删选
contb.shape
输出:(1001733, 8)
未经过过滤的数据
# 捐赠金额大于0
contb_ = contb[contb['contb_receipt_amt'] > 0]
contb_.shape
输出:(991477, 8)
数据和原来相比减少,这说明过滤了一些异常数据(捐款为负数就是异常值)
捐款为负数就是‘耍流氓’行为。
2.3.2 两巨头(奥巴马与罗姆尼)删选
共和党与民主党竞争最后其实就是奥巴马与罗姆尼的竞争,所以删选两位候选人的子集
#选取候选人为Obama、Romney的子集数据
# 方式一:
cond1 = contb_['cand_nm'] == 'Obama, Barack'
cond2 = contb_['cand_nm'] == 'Romney, Mitt'
cond = cond1|cond2
contb_vs = contb_[cond]
# 方式二
contb_vs = contb_.query("cand_nm == 'Obama, Barack' or cand_nm == 'Romney, Mitt'")
# 方式三
cond = contb_['cand_nm'].isin(['Romney, Mitt','Obama, Barack'])
contb_vs = contb_[cond]
用哪种方式都可以
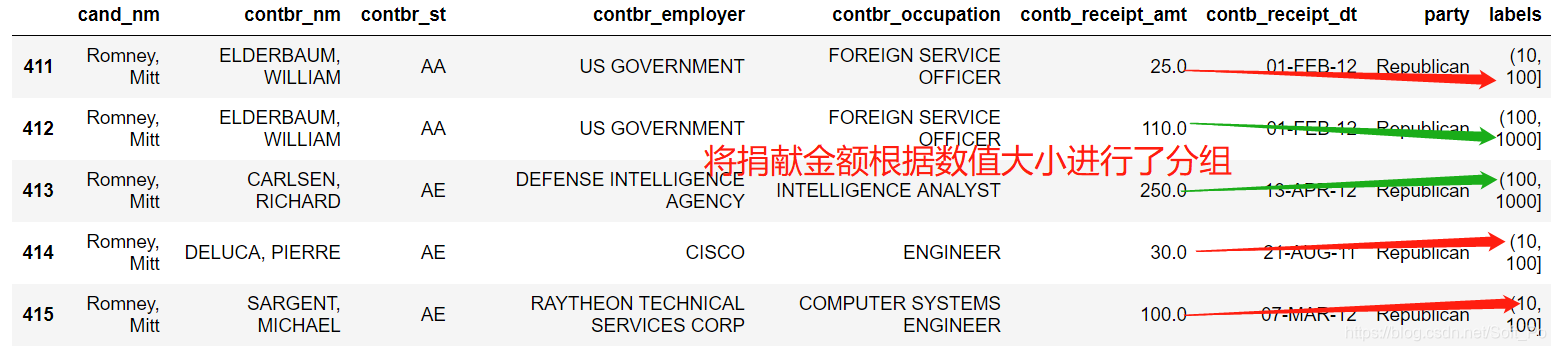
2.4 离散化和分箱操作
接下来我们对该数据做另一种非常实用的分析,利用cut函数根据出资额大小将数据离散化到多个面元中
bins = [0,1,10,100,1000,10000,100000,1000000,10000000]
labels = pd.cut(contb_vs['contb_receipt_amt'],bins)
contb_vs['labels'] = labels
contb_vs.head()
3. 数据聚合与分组运算
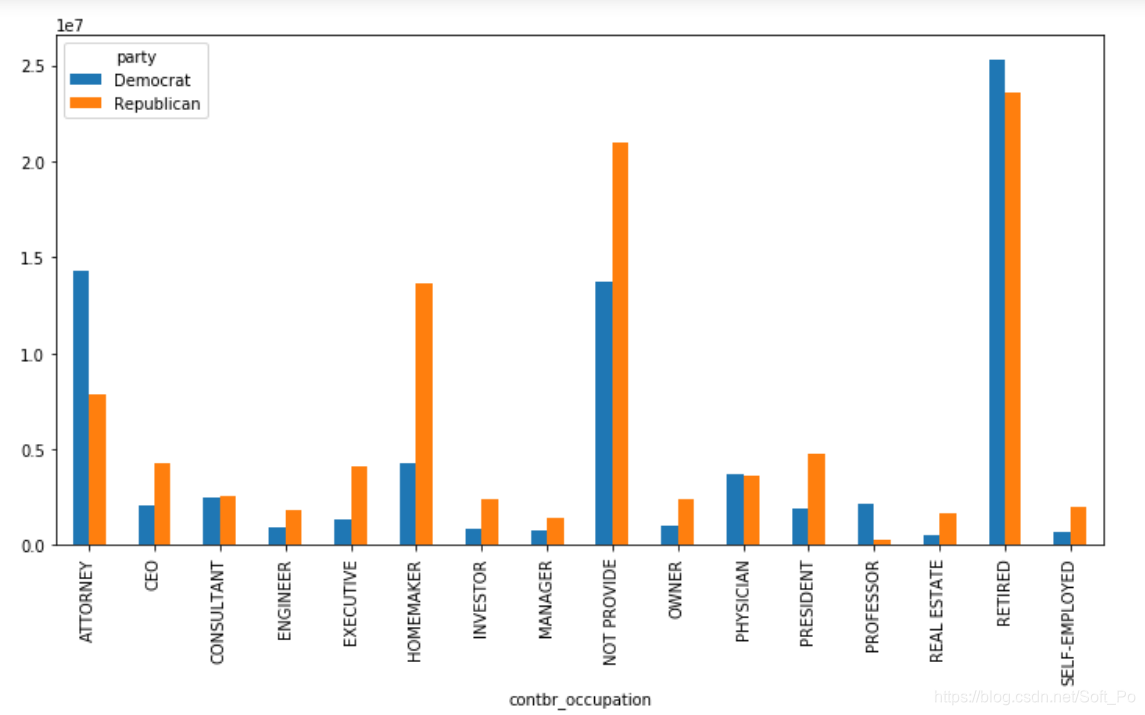
3.1 透视表(pivot_table)分析党派和职业
#按照党派、职业对赞助金额进行汇总,类似excel中的透视表操作,聚合函数为sum
pivot_sum = contb_.pivot_table('contb_receipt_amt',index='contbr_occupation',columns='party',aggfunc='sum',fill_value=0)
#过滤掉赞助金额小于200W的数据
pivot_sum = pivot_sum[pivot_sum.sum(axis = 1)>2000000]
pivot_sum

可以看出律师、CEO、公司高管、医生、投资人、咨询师、教授等是捐献金额比较多的职业
数据可视化
plt.figure(figsize=(12,6))
ax = plt.subplot(1,1,1)
pivot_sum.plot(kind = 'bar',ax = ax)
3.2 分组级运算和转换
3.2.1 根据职业与雇主信息分组聚合运算
根据职业与雇主信息分组运算统计候选人被支持情况
#由于职业和雇主的处理非常相似,我们定义函数get_top_amounts()对两个字段进行分析处理
#参数二是继续分组的key
#参数三是返回前多少个结果
def get_top_amounts(grouped,key,n):
# !!!先分组,grouped,然后继续再分
return grouped.groupby(key)['contb_receipt_amt'].sum().sort_values(ascending = False)[:n]
# 职业对各候选人献金影响
grouped = contb_vs.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_occupation',7).unstack(level = 0)
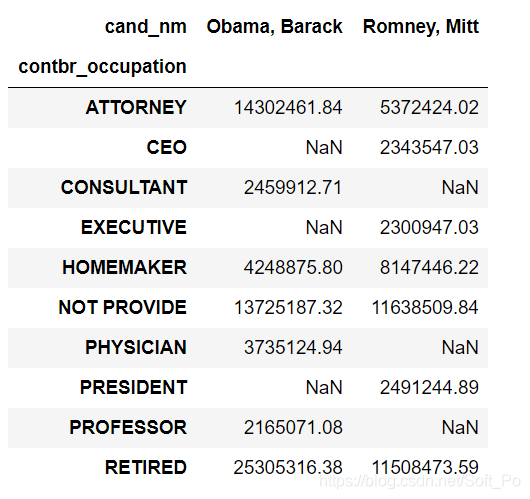
从数据可以看出,Obama更受精英群体(律师、医生、咨询顾问)的欢迎,Romney则得到更多企业家或企业高管的支持
# 同样的,使用get_top_amounts()对雇主进行分析处理
grouped = contb_vs.groupby('cand_nm')
grouped.apply(get_top_amounts,'contbr_employer',10)
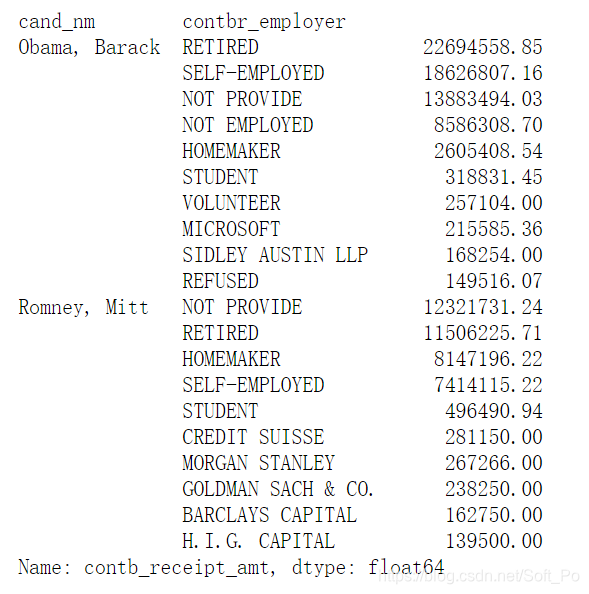
有分析结果可知:
Obama:微软、盛德国际律师事务所; Romney:瑞士瑞信银行、摩根斯坦利、高盛公司、巴克莱资本、H.I.G.资本
3.2.1 对赞助金额进行分组分析并可视化
前面我们已经利用pd.cut()函数,根据出资额大小将数据离散化到多个面元中,接下来我们就要对每个离散化的面元进行分组分析
首先统计各出资区间的赞助笔数,这里用到unstack(),stack()函数是堆叠,unstack()函数就是不要堆叠,即把多层索引变为表格数据
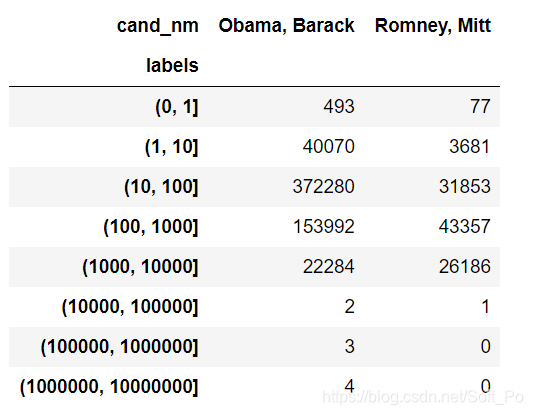
# 统计各区间Obama、Romney接收捐赠次数
contb_vs.groupby(['cand_nm','labels']).size().unstack(level = 0,fill_value = 0)
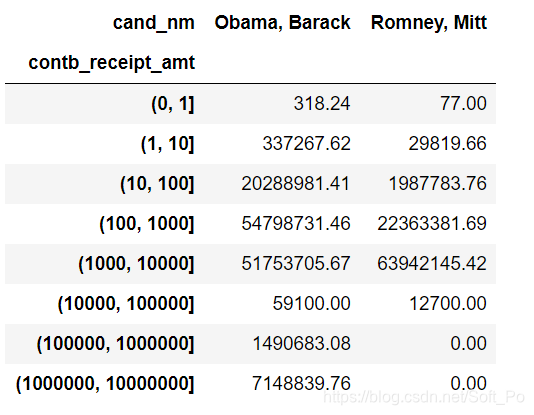
#绘制Obama、Romney各区间赞助总金额
amt_vs = contb_vs.groupby(['cand_nm',labels])['contb_receipt_amt'].sum().unstack(level = 0,fill_value = 0)
amt_vs
# 个人捐款(捐献额大于100000 的都是团体捐款)
# 绘制图形只显示个人捐献情况
amt_vs[:-2].plot(kind = 'bar')
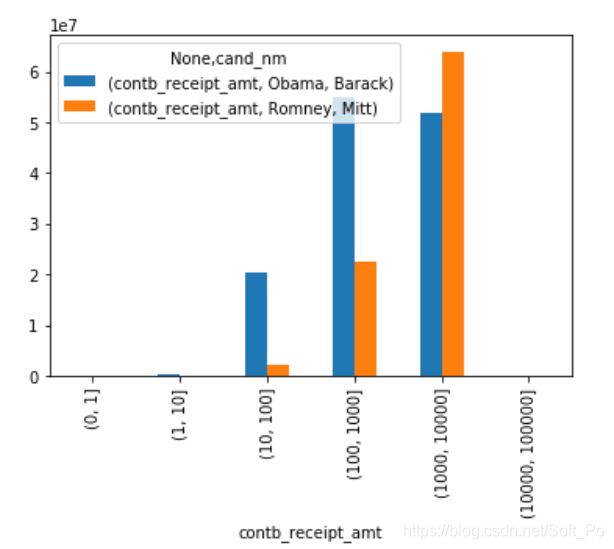
上图虽然能够大概看出Obama、Romney的赞助金额区间分布,但对比并不够突出,如果用百分比堆积图效果会更好,下面我们就实现以下
#算出每个区间两位候选人收到赞助总金额的占比
amt_vs_percent = amt_vs.div(amt_vs.sum(axis = 1),axis = 0)
# 百分比堆积图
amt_vs_percent[:-2].plot(kind = 'bar',stacked = True)
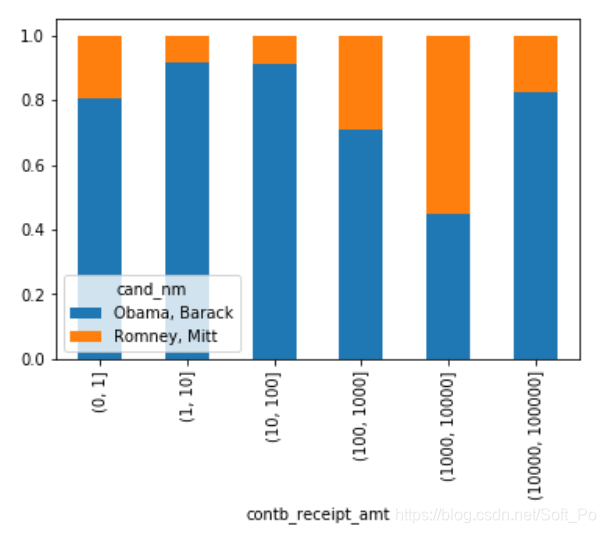
可以看出,小额赞助方面,Obama获得的数量和金额比Romney多得多
4. 时间序列
4.1 str转datetime
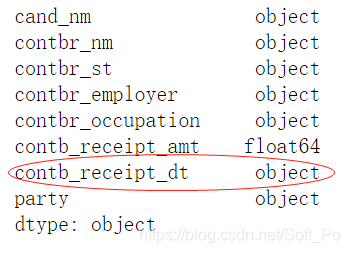
# 未经修改数据类型如下
contb_vs.dtypes
contb_vs['contb_receipt_dt'] = pd.to_datetime(contb_vs['contb_receipt_dt'])
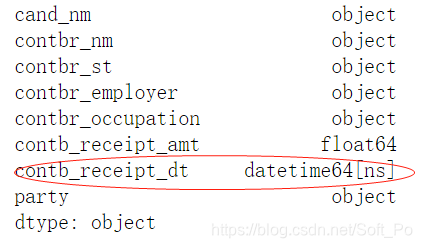
# 修改以后数据类型如下
# datetime64[ns] 时间序列类型数据,单位ns
contb_vs.dtypes
4.2 以时间序列作为行索引
contb_vs_time = contb_vs.set_index('contb_receipt_dt')
contb_vs_time.head()
4.3 重采样和频度转换
重采样(Resampling)指的是把时间序列的频度变为另一个频度的过程。把高频度的数据变为低频度叫做降采样(downsampling),resample会对数据进行分组,然后再调用聚合函数。这里我们把频率从每日转换为每月,属于高频转低频的降采样
!!!重采样的前提是:行索引必须是时间序列
# 行索引是时间,那么我们就可以实现重采样
# D:天,M:月,Y:年
# 统计捐赠次数
vs_month = contb_vs_time.groupby(['cand_nm']).resample('M')['contb_receipt_amt'].count().unstack(level = 0)
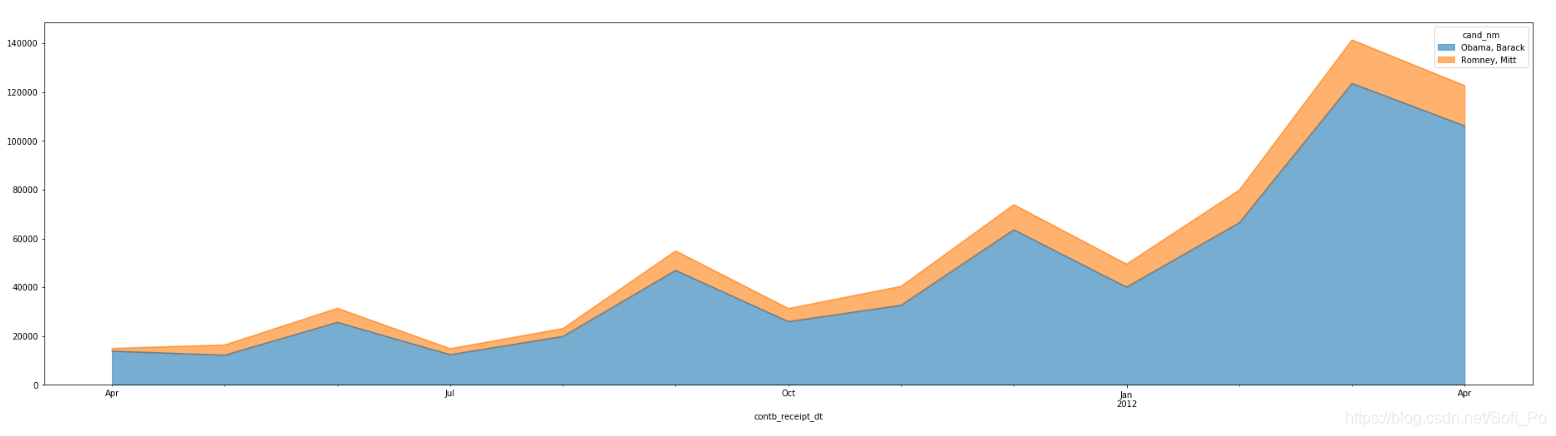
# 我们用面积图把11年4月-12年4月两位总统候选人接受的赞助笔数做个对比可以看出,
# 越临近竞选,大家赞助的热情越高涨,奥巴马在各个时段都占据绝对的优势
plt.figure(figsize=(32,8))
ax = plt.subplot(1,1,1)
vs_month.plot(kind = 'area',ax = ax,alpha = 0.6)
5. 各州支持率与数据地图可视化
5.1 根据候选人和州,进行分组运算
#依据州和候选人进行分组
state_vs = contb_vs.groupby(['cand_nm','contbr_st'])['contb_receipt_amt'].sum().unstack(level = 0)
state_vs
#将金额转化为百分比
state_vs_rate = state_vs.div(state_vs.sum(axis = 1),axis = 0)
state_vs_rate
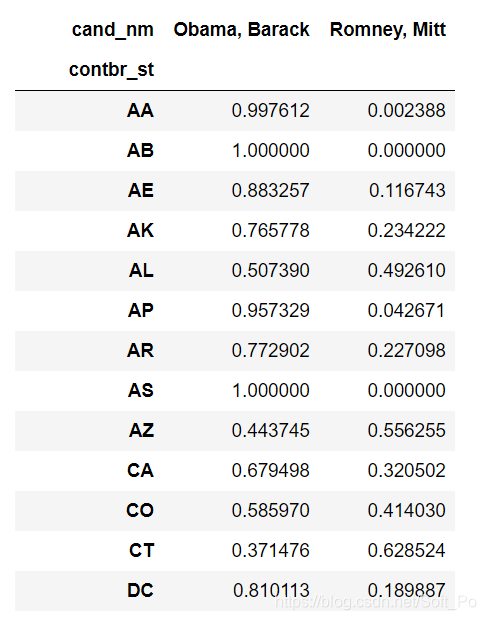
#有一些州统计错误比如:AA,AB等这些在美国根本不存在,删除
state_vs_rate.drop(labels=['AA','AB','AE','NOT PROVIDE'],inplace = True)
5.2 使用Basemap可视化各州支持率
basemape绘制地图,pip install 无法安装成功
下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/
找对应版本下载,使用pip install 文件
这样就可以了
#获取奥巴马在各州支持率
oba = state_vs_rate['Obama, Barack']
#州全称对应缩写缩写
abbr = {'Commonwealth of Kentucky':'KY','Commonwealth of Massachusetts':'MA','Commonwealth of Pennsylvania':'PA',
'State of Rhode Island and Providence Plantations':'RI'}
读取地图形状readshapefile需要去网站下载地图形状:https://gadm.org/download_country_v3.html
import matplotlib.pyplot as plt
%matplotlib inline
from mpl_toolkits.basemap import Basemap
# hex16进制表示的颜色
from matplotlib.colors import rgb2hex
from matplotlib.patches import Polygon
'''llcrnrlon 所需地图域(度)的左下角经度。
llcrnrlat 所需地图域左下角的纬度(度)。
urcrnrlon 所需地图域(度)的右上角经度。
urcrnrlat 所需地图域右上角的纬度(度)。
'''
plt.figure(figsize=(12,9))
m = Basemap(llcrnrlon = -122,
llcrnrlat = 23.41,
urcrnrlon = -64,
urcrnrlat = 45,
projection = 'lcc',
lat_1 = 30,
lon_0 = -100
)
m.drawcoastlines(linewidth=1.5)
m.drawcountries(linewidth = 1.5)
# 地图读取了美国地图形状,m中就有各州的形状,数据
m.readshapefile('./USA/gadm36_USA_1',name = 'states')
colors = []
states = []
cmap = plt.cm.Reds
for shapeinfo in m.states_info:
a = shapeinfo['VARNAME_1']
# 州的缩写
s = a.split('|')[0]
try:
rate = oba[s]
colors.append(cmap(rate))
states.append(s)
except:
colors.append(cmap(oba[abbr[s]]))
states.append(s)
# 州填充颜色
# seg州中的一部分区域,多边形
ax = plt.gca()
for n,seg in enumerate(m.states):
c = rgb2hex(colors[n])
poly = Polygon(seg,color = c )
ax.add_patch(poly)
plt.savefig('./usa_states_rate.jpg')
plt.show()
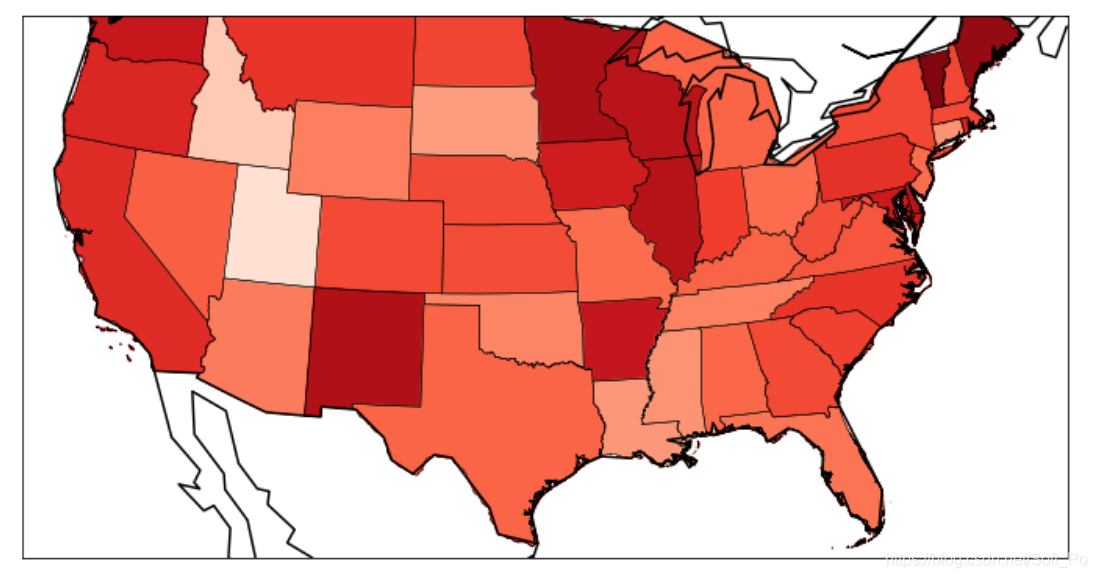
颜色越深,说明奥巴马支持率越高
github源码
链接:https://pan.baidu.com/s/1zcB–rCOiKr1jf95w4Wp6g
提取码:923k
关注微信公众号获取视频和源码















 7625
7625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











